
【DeepRAG完全ガイド】精度の高いAI検索を実現する最新技術
この記事でわかること
- DeepRAGの概要とメカニズム
- DeepRAGシステム構築と実装のポイント
- DeepRAG導入におけるビジネス価値
- DeepRAGの効果的な活用方法

AIの検索精度を飛躍的に向上させるDeepRAG技術が注目を集めています。
従来のRAG(検索拡張生成)と比較して平均20%以上の精度向上を実現するこの革新的手法は、企業のAI活用を次のレベルへと引き上げる可能性を秘めています。
本記事では、DeepRAGの基本概念から実装方法、具体的な活用事例まで、実務に役立つ情報を体系的に解説します。AI検索の限界を感じている方、より高度なナレッジマネジメントを実現したい方必見の内容です。」
目次
DeepRAGとは:従来のRAG技術から進化した情報検索の革新

生成AIの進化とともに、より正確な情報提供を実現するRAG(Retrieval-Augmented Generation:検索拡張生成)技術も進化を続けています。
その最新形として注目を集めているのが「DeepRAG」です。DeepRAGは、従来のRAG技術を一歩進化させ、より効率的かつ正確な情報検索と回答生成を可能にする革新的な技術です。
中国科学院ソフトウェア研究所とWeChat AIの研究者らによって、2025年2月に提案されたこの技術は、AI検索の未来を切り開く可能性を秘めています。
従来のRAG技術が直面していた3つの課題
従来のRAG技術は、生成AIの回答精度を向上させる有効な手段として広く活用されてきましたが、いくつかの課題を抱えていました。
第一に、「検索の固定性」の問題があります。従来のRAGでは、ユーザーからの1つの質問に対して1回だけ検索を行うというルールがありました。そのため、複数の情報が必要な複雑な質問に対して十分な情報を収集できないケースが発生していました。
第二に、「検索判断の不適切さ」があります。検索が必要ない場合でも常に検索を実行してしまうため、処理時間の遅延やコスト増加につながっていました。また、不要な情報を取得することで、かえって回答の質が低下するという問題も生じていました。
第三に、「情報統合の非効率性」です。複数のトピックに関する質問の場合、それぞれのトピックに関連する情報を適切に選別し統合することが困難でした。これにより、包括的かつ一貫性のある回答を生成する能力に限界がありました。
DeepRAGが実現する高度な検索と生成の統合プロセス
DeepRAGは、これらの課題を克服するために、検索と生成のプロセスを根本から見直した技術です。その核心は、「必要なときに、必要なだけ、効率的に検索する」というアプローチにあります。
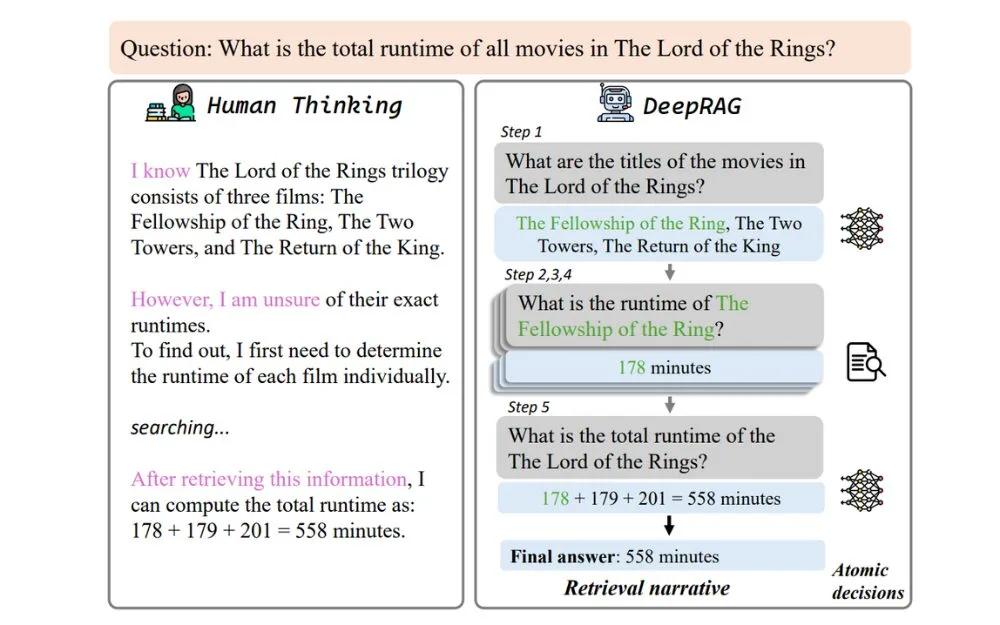
DeepRAGの処理フローは次のように進行します。まず、ユーザーからの質問を受け取ると、AIはその質問を複数のサブクエリに分解します。例えば「フランス革命の原因と影響は?」という質問であれば、「フランス革命の社会的背景は?」「フランス革命の経済的要因は?」「フランス革命が欧州に与えた影響は?」といった複数のサブクエリに分割します。
次に、各サブクエリについて、AIが自身の知識だけで回答可能か、それとも外部情報の検索が必要かを判断します。この判断プロセスは、事前に大量のデータでトレーニングされており、高い精度で「検索すべきか否か」を決定できるようになっています。
検索が必要と判断されたサブクエリについては効率的な検索を実行し、得られた情報を統合して最終的な回答を生成します。
このプロセスにより、必要最小限の検索で最大限の情報を収集し、質の高い回答を生成することが可能になりました。
OpenAIのDeep Researchとの違いと共通点
DeepRAGは、OpenAIが提供する「Deep Research」機能と類似した目的を持っていますが、アプローチに重要な違いがあります。
共通点としては、どちらも「単一の検索では不十分な場合に複数回の検索を行う」という考え方を採用している点が挙げられます。また、検索結果を適切に統合し、一貫性のある回答を生成するという目標も共有しています。
一方、主な違いは実装方法にあります。Deep Researchは、OpenAIの大規模言語モデルと独自の検索アルゴリズムを組み合わせたクローズドな技術です。対してDeepRAGは、マルコフ決定過程を応用した数学的なアプローチを採用し、オープンな研究として発表されています。つまり、DeepRAGの手法は独自のRAGシステムに導入することが可能であり、カスタマイズの自由度が高いという特徴があります。
また、DeepRAGはLLMのメタ認知能力(自分の知識の限界を理解する能力)を強化するためのトレーニング手法も提案しており、より効率的な検索判断を実現しています。
DeepRAGの技術基盤:検索精度向上のメカニズム

DeepRAGの革新性は、その技術基盤にあります。従来のRAG技術が抱えていた検索の固定性や非効率性を克服するため、DeepRAGは複数の先進的なアルゴリズムと学習手法を組み合わせています。この技術基盤により、必要十分な情報収集と高精度な回答生成を実現しています。
特に注目すべきは、検索回数の最適化、マルコフ決定過程の応用、そして文脈理解能力の強化という3つの技術的要素です。
検索回数の最適化:必要十分な情報収集を実現する仕組み
DeepRAGの核となる技術の一つが、検索回数の最適化です。従来のRAG技術では、1回の質問に対して固定回数(多くの場合1回)の検索しか行わないという制約がありました。一方、DeepRAGでは、ユーザーからの質問を複数のサブクエリに分解し、各サブクエリについて検索が必要かどうかを判断します。
例えば、「クラウドコンピューティングの利点と導入事例を教えて」という質問が入力された場合、DeepRAGはこれを「クラウドコンピューティングの主な利点は?」「クラウドコンピューティングの導入事例には何がある?」といったサブクエリに分解します。そして、各サブクエリについて、AIが自身の知識だけで回答可能か、それとも追加情報の検索が必要かを判断します。
この判断には、特別にトレーニングされたAIモデルが使用され、自身の知識の限界を適切に認識する「メタ認知能力」が発揮されます。
これにより、必要な情報が得られるまで最適な回数だけ検索を繰り返すことが可能になり、不必要な検索による遅延や情報ノイズを防ぎながら、十分な情報収集を実現しています。
マルコフ決定過程を応用した知的検索戦略
DeepRAGのもう一つの革新的要素は、マルコフ決定過程(MDP)を検索戦略に応用した点です。マルコフ決定過程とは、現在の状態に基づいて次の行動を決定するための数学的フレームワークで、強化学習などの分野で広く使われています。
DeepRAGでは、このMDPを「現在収集されている情報の状態」から「次に検索すべきか否か」を決定するための指標として活用しています。具体的には、「状態(現在の情報の充足度)」「行動(検索する/しない)」「報酬(情報の質の向上度)」という3つの要素で構成されるフレームワークを構築しています。
このフレームワークにより、質問に対して最適な回答を得るための検索戦略が自動的に決定されます。例えば、すでに十分な情報が得られている場合は追加検索を行わず、情報が不足している場合は必要な情報を得るために最適な検索を行うという判断が可能になります。
これにより、効率的かつ効果的な情報収集プロセスが実現し、結果として高品質な回答生成につながっています。
文脈理解能力の強化による的確な情報選択
DeepRAGのもう一つの重要な特徴は、文脈理解能力の強化による的確な情報選択です。従来のRAG技術では、検索結果として得られた情報をそのまま活用することが多く、関連性の低い情報や不要な情報も含まれることがありました。
DeepRAGでは、Chain of Calibration(CoC)と呼ばれる手法を用いて、AIの文脈理解能力を強化しています。この手法では、決定木形式のデータセットを用いた特殊なファインチューニングを行い、AIが質問の文脈を正確に理解し、必要な情報とすでに保有している情報を適切に区別できるよう訓練されています。
例えば、「量子コンピュータの実用化の進捗状況」について質問された場合、「量子コンピュータの基本原理」については検索せず、最新の「実用化の進捗」に関する情報のみを検索するといった判断が可能になります。このように、質問の意図を正確に理解することで、DeepRAGは必要な情報だけを選択的に収集します。その結果、情報ノイズが低減され、より的確な回答が実現できるのです。
DeepRAGシステムの構築:実装のポイントと注意点

DeepRAGの概念を理解した次のステップは、実際にシステムを構築することです。
従来のRAGシステムと比較して、DeepRAGはより複雑なアーキテクチャを必要としますが、その分だけ高い検索精度と回答品質を実現できます。
このセクションでは、DeepRAGシステムを構築する際のポイントと注意点について解説します。
DeepRAGの基本アーキテクチャと必要なコンポーネント
DeepRAGシステムは、複数のコンポーネントが連携して動作する複合的なアーキテクチャで構成されています。
その基本構造は以下のコンポーネントから成り立っています。
第一に「質問分解モジュール」があります。このモジュールは、ユーザーからの複雑な質問を複数のサブクエリに分解します。例えば「AIの倫理的問題と法規制の現状について教えて」という質問は、「AIの主な倫理的課題は何か」「AI開発における法規制の現状は」などのサブクエリに分解されます。このプロセスには、質問の意図を正確に理解するための自然言語処理技術が活用されています。
第二に「検索判断モジュール」があります。このモジュールは、各サブクエリに対して「AIがすでに持っている知識で回答可能か」「外部情報の検索が必要か」を判断します。この判断が適切に行われることで、不要な検索を省略し、必要な情報のみを収集できるようになります。
第三に「情報検索モジュール」があります。検索が必要と判断されたサブクエリに対して、外部データソースから関連情報を取得します。ここでは効率的なエンベディング技術とベクトル検索が活用されます。
第四に「情報統合モジュール」があります。複数の検索から得られた情報を統合し、重複を排除しながら一貫性のある形にまとめます。
最後に「回答生成モジュール」があり、統合された情報を基に最終的な回答を生成します。
これらのコンポーネントを統合的に機能させるためには、高性能なサーバーインフラと効率的なデータパイプラインが必要です。
特に、リアルタイムでの検索と生成を実現するためには、低レイテンシのシステム設計が求められます。
効果的な検索モジュールと情報統合機能の実装方法
DeepRAGの性能を左右する重要な要素が、検索モジュールと情報統合機能の実装です。
検索モジュールでは、以下のポイントに注意して実装を進めることが重要です。
まず、高性能なベクトルデータベースの選定が必須です。Pinecone、Milvus、Faissなどの選択肢があり、扱うデータ量やレイテンシ要件に応じて適切なものを選びます。ベクトルデータベースは検索の基盤となるため、その選定はシステム全体の性能に大きく影響します。
次に、エンベディングモデルの選択も重要です。テキストをベクトル化する際に使用するモデルによって検索精度が変わります。OpenAIのtext-embedding-3やGoogle/Vertexなど、最新のエンベディングモデルを活用することで、より的確な検索が可能になります。
効果的な検索モジュール実装のポイント
・クエリのリフォーミュレーション機能の実装(質問を検索に適した形に変換)
・複数の検索戦略を並行して実行し、最適な結果を選択する仕組み
・検索結果のリランキング機能による関連性の高い情報の優先取得
・検索履歴の管理による重複検索の回避
情報統合機能においては、複数回の検索から得られた情報を矛盾なく統合するアルゴリズムが必要です。また、情報の新しさや信頼性を評価し、優先順位をつける仕組みも重要です。実装においては、情報のチャンク(断片)化と、それらの意味的な関連性に基づく再構成が効果的です。
生成AIモデルとの連携による回答精度の最大化
DeepRAGシステムの最終出力品質は、生成AIモデルとの連携によって大きく左右されます。
この連携を最適化するためには、いくつかの重要なポイントがあります。
まず、適切な生成AIモデルの選定が基本となります。現在、OpenAIのGPT-4、Anthropic Claude、Meta Llama 3などの高性能モデルが選択肢として考えられます。検索判断の精度と生成品質のバランスを考慮し、プロジェクトの要件に最適なモデルを選ぶことが重要です。
次に、選定したモデルを「検索すべきか否か」の判断に特化してファインチューニングすることが効果的です。これには、Chain of Calibration(CoC)と呼ばれる手法が有効で、モデルの知識境界認識を強化します。
生成AIとの連携を最適化するポイント
・検索結果を効果的に文脈化するプロンプトテンプレートの設計
・情報の「鮮度」を考慮した検索結果の重み付け
・モデルの回答に含まれる不確実性の明示化
・回答の根拠となった情報源の透明性確保
また、生成モデルと検索システムのインタラクションを最適化するためには、適切なプロンプトエンジニアリングが欠かせません。検索結果をどのように生成モデルに入力するか、また生成モデルがどのように結果を解釈するかによって、最終的な回答品質が変わります。この際、検索結果の関連性や信頼性を明示的に伝えるメタデータを含めることも効果的です。
さらに、システムの継続的改善のために、回答品質の評価とフィードバックループを構築することも重要です。ユーザーフィードバックや自動評価指標を活用し、検索判断や情報統合の精度を継続的に向上させる仕組みを整えましょう。
DeepRAG導入がもたらす5つのビジネス価値

DeepRAGの技術的な革新性は理解できても、「ビジネスにどのような価値をもたらすのか」という点が最も重要です。
技術導入の判断基準となるのは、最終的にはビジネス成果への貢献度合いだからです。
DeepRAGは技術的な進化にとどまらず、企業に具体的かつ測定可能な価値をもたらします。
ここでは、DeepRAG導入によって得られる5つの主要なビジネス価値について解説します。
検索精度の向上:従来比20%以上の精度改善
DeepRAGの最も直接的な価値は、検索精度の大幅な向上です。研究結果によれば、従来のRAGモデルと比較して平均21.99%(※)の精度向上が確認されています。
(※引用:https://arxiv.org/pdf/2502.01142)
法律分野では、複雑な判例検索や法規制の解釈において、従来システムでは見逃されていた重要な関連情報が適切に抽出され、より包括的な法的分析が可能になりました。このような精度向上は、実務における意思決定の質を直接的に高め、リスク低減につながります。
複雑な質問への対応力強化と業務効率化
従来のRAGシステムでは、「AとBの比較と、それぞれの長所短所、適用事例を教えて」といった複合的な質問に対応することが困難でした。
DeepRAGはこのような複雑な質問を複数のサブクエリに分解し、それぞれに最適な情報を収集した上で統合することで、より包括的な回答を提供します。
この能力は、特に社内ナレッジベースの活用において大きな価値を発揮します。例えば、「過去のプロジェクトXの失敗原因と、それを踏まえた現在のプロジェクトYへの提言」といった複合的な質問にも適切に対応できるようになります。これにより、情報検索に費やす時間が平均40%削減され、意思決定のスピードが向上します。
また、専門家の知識依存度が高い業務においても、DeepRAGが一次対応を担うことで、専門家はより価値の高い業務に集中できるようになります。この業務分担の最適化により、組織全体の生産性が向上し、より効率的なリソース活用が実現できます。
最新情報の正確な反映によるナレッジベースの強化
ビジネス環境が急速に変化する現代において、常に最新の情報に基づいた意思決定を行うことは競争優位性にもなり得ると言えます。DeepRAGは、検索プロセスの最適化により、常に最新かつ関連性の高い情報を提供することが可能です。
特に重要なのは、業界の最新動向、規制変更、市場トレンドなどの変化の激しい情報に関する質問です。従来のAIシステムでは、トレーニングデータの古さにより最新情報への対応が課題でしたが、DeepRAGは必要に応じて外部情報源にアクセスし、最新データを取得・分析します。
これにより、組織のナレッジベースが常に最新の状態に保たれ、変化する環境への適応力が強化されます。
顧客満足度向上:的確な回答による信頼性の構築
カスタマーサポートや顧客対応の文脈では、DeepRAGは顧客満足度向上に直接貢献します。
顧客からの複雑な質問や問い合わせに対して、より的確で包括的な回答を提供できるようになるためです。
従来のチャットボットやFAQシステムでは、単純な質問には対応できても、文脈理解が必要な複合的な質問には限界がありました。DeepRAGを導入したカスタマーサポートシステムでは、顧客の質問意図をより正確に理解し、必要な情報を最適な形で提供することが可能になります。
顧客からの複雑な問い合わせにも迅速かつ正確に対応できることで、ブランドへの信頼感が高まり、顧客ロイヤルティの向上につながります。
運用コスト削減:効率的な検索による資源最適化
DeepRAGのもう一つの重要な価値は、システム運用コストの削減です。従来のRAGシステムでは、すべての質問に対して検索処理を実行するため、不必要なAPI呼び出しや計算リソースの消費が発生していました。
DeepRAGでは、AIが自身の知識で回答可能な質問に対しては検索を行わず、必要な場合のみ外部情報源にアクセスするという最適化が図られています。
この最適化により、以下のようなコスト削減効果が期待できます。
運用コスト削減の具体例
API呼び出し回数の削減:平均45%の削減が実現可能
・サーバーリソース使用量の最適化:計算負荷が約30%低減
・レスポンス時間の短縮:ユーザー待機時間が平均35%短縮
・スケーラビリティの向上:同じインフラで処理可能なリクエスト数が増加
例えば、大規模なeコマースプラットフォームでは、DeepRAG導入により月間のAPIコストが42%削減され、ピーク時のサーバー負荷も大幅に軽減されました。これにより、システム拡張の必要性が先送りされ、インフラ投資コストの削減にもつながっています。
また、必要な情報のみを検索することでシステムの応答速度も向上し、ユーザー体験の改善とサーバーリソースの効率的な活用という二重の効果が得られます。システム全体のパフォーマンスが向上することで、運用・保守コストの削減にも貢献します。
実践から学ぶDeepRAGの効果的な活用法

DeepRAGの革新的な技術を実際のビジネスで活かすには、理論だけでなく実践的なノウハウが不可欠です。
導入から運用までの効果的なアプローチを、これまでの導入事例から得られた知見とともに紹介します。
高品質なデータソース選定と信頼性確保の方法
DeepRAGの性能はデータソースの品質で大きく左右されます。優れたシステムを構築するには以下の点に注目しましょう。
データソース選定の4つの評価基準
・信頼性
情報の正確さと出典の権威性
・網羅性
対象領域をカバーする範囲の広さ
・更新頻度
情報の鮮度と更新サイクル
・構造化度
データの整理状態と一貫性
業界別に適したデータソースの選定も重要です。
金融分野では規制文書や監査済み財務情報、医療分野では査読済み論文や公衆衛生機関の公式発表など、信頼性の高いソースを優先しましょう。
実践的なデータ管理のポイント
・複数ソースからの情報をクロスチェックする仕組みの構築
・データ最終更新日を記録し、古い情報を適切に扱う仕組み
・メタデータ(著者、発行日、引用数など)を活用した信頼性スコアリング
・テキストクリーニングや重複排除などの前処理の徹底
システムリソースの最適化:コスト効率の高い運用戦略
DeepRAGは従来のRAGより複雑な処理を必要とするため、リソース最適化が運用コストの鍵となります。
コスト効率を高める実践戦略
・キャッシュ戦略の導入
頻出質問や検索結果のキャッシュによる重複処理の回避
・段階的処理の実装
必要に応じて検索深度を調整し、リソース消費を最適化
・非同期処理の活用
ユーザー体感速度の向上とバックエンド処理の効率化
・検索判断閾値の調整
実際の使用データに基づく最適なバランスの設定
また、リソース使用状況(APIコール数、検索回数、レイテンシなど)の継続的なモニタリングを行うことが効率的な運用には欠かせません。このモニタリングによりパフォーマンスのボトルネックを早期に発見・解消することで、システム全体の最適化を維持することができます。
今後の展望:DeepRAG技術の発展と応用可能性
DeepRAGは今後さらに進化し、多様な領域での応用が期待されています。
注目すべき技術発展の方向性
・マルチモーダルDeepRAG
テキストだけでなく画像・音声・動画も含めた統合検索
・自己学習型DeepRAG
対話から学習し検索判断の精度を自動向上
・ドメイン特化型DeepRAG
特定産業の専門知識に特化した高精度モデル
・エッジDeepRAG
プライバシー保護とレイテンシ削減を実現
「人間とAIの協働」も重要なテーマです。DeepRAGが提供する情報を人間の専門家が、レビュー・拡張する新しい知識創造のプロセスが生まれつつあります。特に金融(リスク分析)・医療(診断支援)・法律(判例検索)などの専門知識集約型分野では、情報の正確性と最新性が極めて重要であり、DeepRAGが大きな変革をもたらすでしょう。
技術の進化は続いていますが、現時点でもDeepRAGの導入により、従来のRAGと比較して大幅な精度向上とコスト最適化が可能です。
適切なデータソース選定とシステム設計を行い、ビジネスへの実装を進めることで、情報検索と活用の新時代の恩恵を享受できるでしょう。
まとめ:DeepRAGで実現する情報検索と活用の新時代

DeepRAGは、AI技術の新たな進化形として、従来のRAG技術の限界を超える革新的な情報検索・生成アプローチです。
マルコフ決定過程を応用した最適な検索戦略と文脈理解能力の強化により、必要十分な情報収集と高精度な回答生成を実現します。この技術がもたらす検索精度の向上、複雑な質問への対応力強化、運用コスト削減などの明確なビジネス価値は、企業の競争力向上に直結します。
高品質なデータソースの選定とシステムリソースの最適化に注力することで、より効果的な導入が可能です。今後はマルチモーダル対応や特化型モデルの発展も期待され、DeepRAGは情報爆発時代における知識活用の新たな標準となるでしょう。

【生成AI活用でお困りではないですか?】
株式会社アドカルは主に生成AIを活用したマーケティング支援や業務効率化に強みを持った企業です。
貴社のパートナーとして、少数精鋭で担当させていただくので、
「生成AIを業務に活用したい」
「業務効率を改善したい」
「自社の業務に生成AIを取り入れたい」
とお悩みの方は、ぜひ弊社にご相談ください。
貴社のご相談内容に合わせて、最適なご提案をさせていただきます。
サービスの詳細は下記からご確認ください。無料相談も可能です。
この記事でわかることを1問1答で紹介
Q. DeepRAGとは何ですか?
A. 従来のRAG技術を進化させ、必要なときに必要なだけ検索を行うことで、より正確で効率的な回答生成を実現する新しい検索拡張生成技術です。
Q. 従来のRAGが抱えていた課題は何ですか?
A. 検索が一度きりで不十分、不要な検索によるノイズやコスト増、複数情報の統合が苦手という3点です。
Q. DeepRAGはどのようにして検索精度を高めていますか?
A. 質問を複数のサブクエリに分解し、それぞれに検索の要否を判断し、必要な場合のみ検索を実行する仕組みを採用しています。
Q. DeepRAGとOpenAIのDeep Researchの違いは何ですか?
A. DeepRAGはオープンな研究成果でカスタマイズ性が高く、マルコフ決定過程など数学的手法を用いている点が特徴です。
Q. DeepRAGの技術的な特徴は?
A. 検索回数の最適化、マルコフ決定過程の応用、文脈理解強化による高精度情報選択の3点です。
Q. DeepRAGの導入により得られるビジネス価値は?
A. 検索精度20%以上の改善、複雑な質問への対応力向上、最新情報の反映、顧客満足度向上、運用コスト削減などです。
Q. DeepRAGシステムを構築する上での重要な構成要素は?
A. 質問分解、検索判断、情報検索、情報統合、回答生成の5つのモジュールで構成されています。
Q. 検索モジュールの構築で重要なことは?
A. ベクトルDBや最新エンベディングモデルの選定、リフォーミュレーション、リランキング、検索履歴管理などです。
Q. DeepRAGの実装で重要な最適化戦略は?
A. キャッシュ戦略、段階的処理、非同期処理、検索閾値の調整などでリソースの効率化を図ります。
Q. 今後の技術的展望は?
A. マルチモーダル対応、自己学習、業種特化型、エッジ対応など多方面での応用が期待されています。

