
Hugging Faceとは?AI開発に役立つ7つの機能
この記事でわかること
- Hugging Faceの基本機能と注目される理由
- 事前学習済みモデルやデータセットの使い方
- Transformersなど主要ライブラリの活用方法
- AIモデルの作成・共有・デモ公開の実践ステップ
- ビジネス導入時のメリット・注意点・将来性

AI開発を始めたいけれど、モデルの構築やデータセットの準備に時間がかかると悩んでいませんか?
そんな方におすすめなのが「Hugging Face」です。Hugging Faceは、高品質な事前学習済みモデルやデータセットを無料で利用できるオープンソースプラットフォームです。
AI開発の敷居を大幅に下げ、わずか数行のコードでAIの実装が可能になります。本記事では、Hugging Faceの基本概念から実践的な活用法まで、AI開発を効率化する7つの機能を徹底解説します。
目次
Hugging Faceとは:AI開発を効率化する革新的プラットフォーム
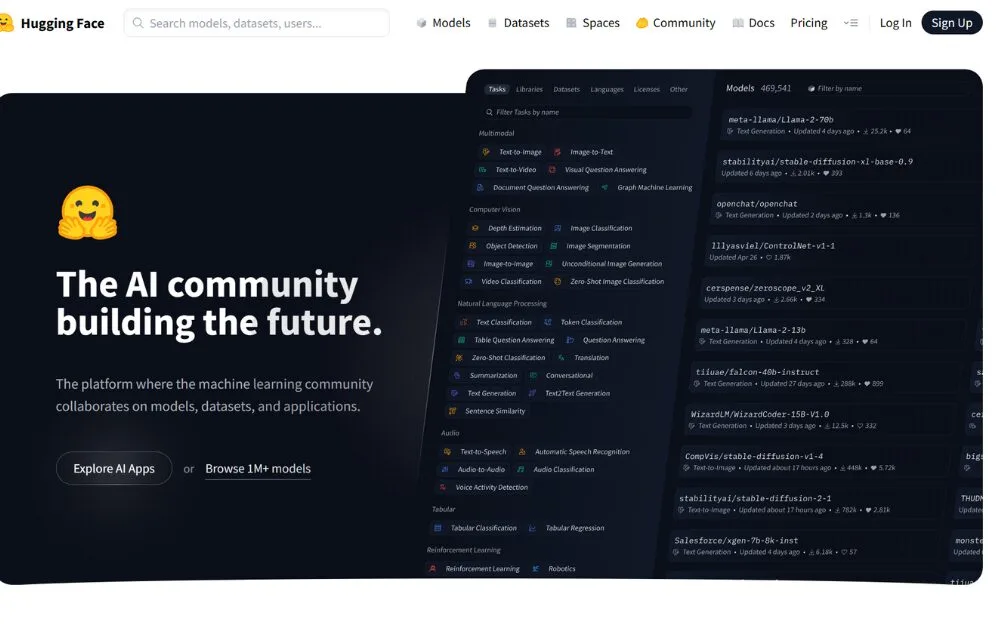
「AIモデル開発に取り組みたいけれど、どこから始めればよいか分からない」「生成AIを活用したいけれど、専門知識や計算リソースが足りない」といった悩みを抱えていませんか?そんな課題を解決する強力なプラットフォームが「Hugging Face」です。この記事では、AI開発を劇的に効率化するHugging Faceの機能や活用法を詳しく解説します。
Hugging Faceの概要と歴史
Hugging Faceは2016年に設立されたアメリカの企業で、AI開発・機械学習のためのオープンソースプラットフォームを提供しています。
当初はチャットボットを開発する企業として出発しましたが、現在は大きく領域を広げ、AIコミュニティの協力と共有を促進することを目的として活動しています。
特筆すべきは、単なるプラットフォーム提供者ではなく、自らも多くのオープンソースライブラリを開発・提供している点です。「ライブラリ」でAIシステム開発ツールを提供し、「HUB」でそれらを使って作られた成果物(モデルなど)を共有する場所として機能しており、AI開発者にとって必須のエコシステムとなっています。
なぜ今Hugging Faceが注目されているのか
Hugging Faceが近年特に注目を集めている理由は、ChatGPTの登場以降、自然言語処理分野や生成AI分野の需要が爆発的に高まっているからです。Hugging Faceはこれらの分野において、高品質なモデルとデータセットを豊富に提供しています。
多くの開発者やビジネスが生成AIを活用したいと考える中、その実現のハードルを大きく下げる役割を果たしているのです。
また、MetaやOpenAI、Googleといった大手IT企業も多くのAIモデルをHugging Face上で公開しており、最先端のAI技術にアクセスできる場としての価値も高まっています。オープンソースの文化を促進し、AIの民主化に大きく貢献していることが、その人気の源となっています。
Hugging Faceが解決する課題
Hugging Faceは、AI開発における以下のような課題を効果的に解決します。
・開発コストの削減
事前学習済みのモデルを活用することで、ゼロからの開発に比べて時間とコストを大幅に削減できます
・技術的障壁の低減
専門知識がなくても、数行のコードで高度なAIモデルを実装可能にし、参入障壁を下げています
・リソース制約の解消
膨大な計算リソースが必要な学習済みモデルを直接利用できるため、限られた環境でも高度なAI機能を実現できます
・知識共有の促進
コミュニティベースの双方向プラットフォームとして、知識や成果物の共有を容易にしています
これらの課題解決により、個人開発者から大企業まで、さまざまな規模の組織がAI技術を活用できるようになっています。特に、自社でAI開発チームを持たない中小企業にとって、Hugging Faceは最新AI技術を取り入れる貴重な窓口となっているのです。
Hugging Face Hubの基本機能とは:4つの主要サービスを解説
Hugging Face Hubは、AI開発・機械学習のためのオープンソースプラットフォームです。プラットフォームでは、ユーザーは自ら開発したモデルやデータセットを公開したり、他のユーザーが公開したリソースを活用したりします。このプラットフォームの魅力は、AI開発の効率化と知識共有の促進にあります。ここでは、Hugging Face Hubが提供する4つの主要サービスについて詳しく見ていきましょう。
Hugging Face Modelsとは:事前学習済みモデルの活用方法
Hugging Face Hubの最大の特長は、あらかじめトレーニング済みの高品質なAIモデルを簡単に利用できる点です。Modelsでは、自然言語処理モデルや音声モデル、画像モデルなど、さまざまな分野のAIモデルが公開されています。それらを数行のコードで自社システムに組み込むことができます。
公開されているモデルはカテゴリ別に整理されており、目的に合ったモデルを簡単に見つけられるのです。各モデルには「Model Card」があります。モデルの説明や目的、制限事項、トレーニングに使用したパラメータやデータセット、評価結果などが記載されています。
これらの情報を参考にしながら、自社のニーズに最適なモデルを選択できます。
ゼロから高品質なモデルを開発するには膨大な計算リソースと専門知識が必要です。
Hugging Face Hubを利用することで、それらのコストを大幅に削減できます。
Hugging Face Datasetsとは:高品質なデータセットへのアクセス手順
Hugging Face Hubには、自然言語処理、画像認識、音声認識などさまざまなタスクのためのデータセットが公開されています。例えば、Wikipediaの記事やニュース記事、SNSの投稿など、多様なテキストデータが提供されています。これらを活用することで高精度な言語モデルを短期間で開発できるでしょう。
各データセットには「Dataset Card」があり、データセットの言語やライセンス、タグなどの詳細情報が説明されています。上部ナビゲーションの検索バーやメインデータセットページを使用して簡単に検索でき、結果をフィルタリングすることも可能です。
データセットへのアクセス手順は非常にシンプルで、Hugging Faceが提供するDatasetsライブラリを使用すれば、わずか数行のコードでデータをロードして利用できます。これにより、データ収集や前処理にかかる時間を大幅に削減できるのです。
Hugging Face Spacesとは:AIモデルのデモ作成と共有プロセス
Hugging Face Spacesは、開発したAIモデルをデプロイし、インタラクティブなデモを作成して共有できるサービスです。
自社のAIモデルを迅速に実装し、ステークホルダーに効果的にアピールしたい場合に非常に便利です。
ユーザーは、GradioやStreamlitといった、機械学習モデルのWebアプリケーションデモを簡単に作れるフレームワークを使用して、AIモデルのデモを開発・公開できます。無料プランでは、2つの仮想CPU、16GBのメモリ、50GBのストレージが提供されています。中小規模のAIモデルであれば追加コストなしでデモを公開することができます。
現在、Spacesには企業や個人が開発した多数のデモが公開されており、有名な画像生成AIである「Stable Diffusion」なども使用可能です。これらのデモを試すことで、モデルの性能や使い勝手を実際に体験してから導入を検討できるのも大きなメリットです。
Hugging Face Docsとは:充実した学習リソースの効果的な使い方
Hugging Face Docsは、Hugging Faceの機能や公開されているモデル・データセット・ライブラリの詳細を、学べる包括的なドキュメントです。各機能の詳細な説明や使用方法、ベストプラクティスが記載されており、開発者はこれらの情報を活用して効率的にAIシステムを構築することができます。
例えば、Transformersライブラリの使い方やDatasetsの活用方法、Spacesでのデモ作成手順などが、ステップバイステップで解説されています。また、公開されているリソースの特徴や性能、使用上の注意点なども丁寧に説明されているため、初心者でも安心して利用を始められます。
Docsを効果的に活用するコツは、まず概要を把握してから、実際に手を動かしながら学習を進めることです。チュートリアルに沿って実装してみることで、理解が深まり、実際のプロジェクトへの応用もスムーズになります。
また、定期的にDocsをチェックすることで、新機能や更新情報をキャッチアップすることも重要です。
Hugging Faceのライブラリとは:AI開発を加速する4つのツール

Hugging Faceの特筆すべき点は、単なるプラットフォーム運営者ではなく、自社でも数多くのオープンソースライブラリを開発・提供している点です。これらのライブラリを活用することで、AIの開発や研究に必要な時間とリソースを大幅に削減できます。ここでは、Hugging Faceが提供する4つの主要ライブラリについて解説します。これらのツールは互いに連携して動作し、AI開発の全工程をサポートします。
Hugging Face Transformersライブラリとは:自然言語処理の強力なツール
Transformersライブラリは、Hugging Faceの看板ライブラリであり、自然言語処理や画像認識、音声認識などに関する事前学習済みモデルを簡単に利用できるツールです。BERT、GPT-2、ViT、Wav2Vec 2.0といった有名なモデルが実装されており、数行のコードで高度なAI機能を実現できます。
このライブラリの最大の特長は、大規模なデータセットで事前学習されたモデルをそのまま使用できる点です。また、新たなデータセットでの追加学習やファインチューニング(微調整)を行うための機能も充実しており、自社の特定の課題に合わせてモデルをカスタマイズすることも容易です。
PyTorch、TensorFlow、JAXといった主要なディープラーニングフレームワークとの互換性も備えており、開発者は慣れ親しんだ環境でTransformersの機能を最大限に活用できます。これにより、自然言語処理に関する開発コストを大幅に削減し、より多くの企業がAI技術を活用できるようになっています。
Hugging Face Datasetsライブラリとは:データ処理を効率化する方法
Datasetsライブラリは、AI開発・機械学習の研究に必要となるさまざまなデータセットを簡単に利用できるようにするためのツールです。自然言語処理をはじめとする多様なタスクのためのデータセットが提供されており、これらを活用することで学習データの準備にかかる時間を大幅に短縮できます。
このライブラリの優れている点は、わずか1行のコードでデータセットを読み込めることです。また、データの変換やフィルタリングなど、前処理の機能も充実しており、より効率的に機械学習を進めることができます。さらに、大規模なデータセットでもメモリ効率の良い処理が可能なため、限られたリソースでも快適に作業を進められます。
研究者や開発者は、データ収集や整形に時間を費やす代わりに、モデルの設計や評価など、より創造的なタスクに集中できるようになります。
これは特に、データ収集が難しい分野や、スタートアップのような限られたリソースの環境で大きな価値を発揮します。
Hugging Face Tokenizersライブラリとは:テキスト処理の高速化技術
Tokenizersライブラリは、テキストデータを機械学習モデルが処理しやすい形式に変換する「トークン化」のプロセスを効率化するためのツールです。自然言語処理モデルでは、テキストをそのまま扱うことができないため、単語や部分単語などの「トークン」に分解する必要があります。
このライブラリが提供する主な機能は以下の通りです
・テキストをトークンと呼ばれる最小の単位に区切る処理
・それぞれのトークンに固有のIDを割り当てる処理
・モデルの入力に必要なスペシャルトークンを追加する処理
トークン化の方法は使用するモデルによって異なりますが、Tokenizersライブラリにはさまざまなモデルに対応したトークナイザーが用意されています。また、Rustで実装されているため非常に高速で、大規模なテキストデータも効率的に処理できます。
これにより、データの前処理にかかる時間を大幅に削減し、AIの開発サイクルを加速することができます。
Hugging Face Accelerateライブラリとは:異なる計算環境での実行を可能にする技術
Accelerateライブラリは、異なる計算リソース環境でも同じコードを実行できるようにするためのツールです。CPU、GPU、TPUといったさまざまなハードウェアや、単一デバイスから分散システムまで、環境に応じた最適な実行を可能にします。
機械学習の世界では、開発環境と本番環境の違いや、利用可能な計算リソースの違いによってコードが動作しないことがよくあります。Accelerateライブラリを使用すれば、わずか数行のコードを追加するだけで、あらゆる環境での実行を保証できます。
特に大規模なモデルのトレーニングや推論では、複数のGPUやTPUを効率的に活用することが重要です。Accelerateライブラリは、こうした分散環境でのトレーニングを簡単に実装できるようにし、開発者がハードウェアの詳細に悩まされることなく、モデルの設計や改善に集中できるようサポートします。また、クラウド環境からエッジデバイスまで、幅広い展開シナリオに対応できるのも大きな魅力です。
Hugging Faceで利用できるAIモデルとは:用途別の選び方と特徴

Hugging Faceプラットフォームの大きな魅力は、数多くの高品質なAIモデルが公開されていることです。自然言語処理から画像認識、音声処理、そして複数のモダリティを組み合わせたマルチモーダルモデルまで、さまざまな用途に応じたモデルが揃っています。ここでは、主要なモデルカテゴリとその特徴、選び方について解説します。
Hugging Faceの自然言語処理モデル:BERT、GPT-2、T5の特徴と使い分け
Hugging Faceの代表的な自然言語処理モデルには、BERT、GPT-2、T5などがあります。BERTは文脈を考慮した双方向の言語理解に優れており、テキスト分類や質問応答などのタスクに適しています。GPT-2は自然な文章生成能力が高く、文章の続きを生成するようなタスクに強みがあります。
T5はあらゆる自然言語処理タスクをテキスト生成問題として統一的に扱えるため、多様なタスクに対応可能です。
これらのモデルの使い分けは、タスクの性質によって決まります。例えば、テキスト理解が重要なアプリケーションではBERT系モデルを、創造的な文章生成が必要なケースではGPT系モデルを選ぶと良いでしょう。また、多言語対応が必要な場合は、mBERTやXLM-RoBERTaなどの多言語モデルが適しています。
Hugging Faceの画像認識モデル:ViTなどの代表的なモデルの活用法
画像認識分野では、Vision Transformer (ViT)をはじめとする革新的なモデルが利用可能です。ViTは画像を小さなパッチに分割し、Transformerアーキテクチャで処理することで高い認識精度を実現しています。また、DETRは物体検出を効率的に行うTransformerベースのモデルとして注目されています。
これらの画像認識モデルは、商品の自動分類、医療画像の診断支援、監視カメラ映像の分析など、さまざまな実用シーンで活用できます。
例えば、ECサイトでは商品画像から自動的にカテゴリを判別したり、製造業では製品の外観検査を自動化したりすることが可能です。
モデル選択の際は、必要な精度と処理速度のバランス、特定のドメインに対する適合性を考慮することが重要です。
Hugging Faceの音声処理モデル:Wav2Vec 2.0などの性能と利用シーン
音声処理分野では、Wav2Vec 2.0やHuBERT、Whisperなどの高性能モデルが提供されています。特にWav2Vec 2.0は、少量のラベル付きデータでも高い精度を実現する自己教師あり学習アプローチを採用しており、さまざまな言語での音声認識に強みがあります。
これらの音声モデルは、音声文字起こし、通話内容の分析、音声アシスタント、言語学習アプリなど、多様なアプリケーションで活用できます。例えば、会議の自動議事録作成や、カスタマーサポートコールの分析、多言語コンテンツの字幕生成などに利用できます。モデル選択では、対象言語のサポート状況や認識精度、処理速度、リアルタイム性などを考慮するとよいでしょう。
Hugging Faceのマルチモーダルモデル:最新技術の実践的な応用例
マルチモーダルモデルは、テキスト、画像、音声など複数の情報モダリティを組み合わせて処理する次世代のAIモデルです。例えば、CLIPはテキストと画像を関連付けて学習したモデルで、テキストによる画像検索や画像の意味理解が可能です。
また、FLAVAやLLaVAなどのモデルは、大規模言語モデルと視覚表現を組み合わせた強力なマルチモーダル理解を実現しています。
これらのモデルは、画像に基づく質問応答、視覚的な商品検索、コンテンツ推薦、アクセシビリティ向上など、革新的なアプリケーションを可能にします。例えば、ECサイトでは「青い花柄の夏用ワンピース」といったテキスト検索から直接商品画像を検索できるようになります。
また、視覚障害者向けのアプリでは、周囲の環境を説明するキャプションを自動生成することも可能です。最新のマルチモーダルモデルは、異なる種類の情報を統合して理解する能力により、よりインテリジェントで自然なユーザー体験を創出しています。
Hugging Faceを使ったAI開発とは:初心者から上級者まで実践ガイド

Hugging Faceを活用したAI開発は、驚くほど簡単に始められます。事前学習済みのモデルを活用することで、AIの知識が浅い方でも高度な機能を実装可能です。ここでは、環境構築から独自モデルの共有まで、段階的に実践方法を解説します。
Hugging Face環境構築ガイド:初めての設定から使用開始までの手順
Hugging Face環境の構築は、主にPythonと必要なライブラリのインストールから始まります。
まず、Pythonをインストールし、仮想環境を作成することをお勧めします。これにより、プロジェクト間での依存関係の競合を避けられます。
# 仮想環境の作成と有効化
python -m venv huggingface_env
source huggingface_env/bin/activate # Windowsの場合は huggingface_env\Scripts\activate
# 必要なライブラリのインストール
pip install transformers datasets torch
環境構築が完了したら、必要に応じてHugging Face Hubのアカウントを作成し、APIトークンを取得します。このトークンはモデルのアップロードやプライベートモデルへのアクセスに必要です。基本的なIDEとしては、VS CodeやJupyter Notebookが便利です。
Hugging Faceでの初めてのモデル利用:5行のコードで始める方法
Hugging Faceの最大の魅力は、わずか数行のコードで高度なAIモデルを利用できる点です。
例えば、以下の5行だけで感情分析を実装できます。
python
from transformers import pipeline
# 感情分析パイプラインの初期化
classifier = pipeline(‘sentiment-analysis’)
# テキストの感情分析を実行
result = classifier(‘このサービスは非常に使いやすくて満足しています!’)
print(result) # [{‘label’: ‘POSITIVE’, ‘score’: 0.9998}] のような結果が出力されます
このように、パイプラインAPIを使うことで、モデルのロードから推論までを簡単に実装できます。
テキスト生成、要約、翻訳、質問応答など、さまざまなタスクに対応したパイプラインが用意されており、AIの専門知識がなくても直感的に利用できます。
Hugging Faceでのモデルファインチューニング:自社データでカスタマイズする手順
事前学習済みモデルをそのまま使うだけでなく、自社のデータでファインチューニングすることで、特定のタスクに特化したモデルを作成できます。
ファインチューニングの基本的な手順は以下の通りです。
- データの準備: 自社データをHugging Faceのデータセット形式に変換します
- モデルの準備: ファインチューニングのベースとなる事前学習済みモデルを選択します
- トレーニングの設定: Trainer APIを使用して学習パラメータを設定します
- トレーニングの実行: 用意したデータでモデルを学習させます
- 評価と保存: モデルの性能を評価し、満足のいく結果であれば保存します
例えば、日本語の製品レビューを分類するモデルをカスタマイズしたい場合、BERTなどの事前学習済みモデルをベースにできます。自社の製品レビューデータでファインチューニングすることで、業界特有の表現や製品特性を考慮した高精度な分類が可能になります。
Hugging Faceでの開発モデルの共有:コミュニティに貢献するメリット
開発したモデルをHugging Face Hubで共有することには、多くのメリットがあります。まず、コミュニティからのフィードバックを得られるため、モデルの改善に役立ちます。また、企業の技術力をアピールする場としても活用できます。
モデルを共有する手順は以下の通りです
・Model Cardの作成
モデルの概要、使用方法、制限事項などを記載した文書
・ライセンスの選択
オープンソースライセンスの中から適切なものを選択
・モデルのアップロード
Hugging Face CLIまたはPythonライブラリを使用して実行
なお、すべてのモデルを公開する必要はなく、プライベートリポジトリとして保存することも可能です。これにより、社内やクライアントとの間でのみモデルを共有することができます。
モデル共有の文化に参加することで、AI技術の発展に貢献しながら、自社のプレゼンスを高められるという一石二鳥の効果が期待できます。
また、公開したモデルが多くの開発者に利用されることで、予想外の活用方法や改善案が生まれることもあります。
Hugging Face導入のメリットとは:導入前に知っておくべきポイント
Hugging Faceは多くの企業や開発者に採用されていますが、導入する前に、そのメリットと注意点を把握しておくことが重要です。ここでは、ビジネス視点からHugging Face導入の価値と検討すべきポイントを解説します。
Hugging Faceがビジネスにもたらす具体的な価値
Hugging Faceの導入は、ビジネスに以下のような具体的な価値をもたらします。
まず、開発コストと時間の大幅削減が挙げられます。事前学習済みモデルを活用することで、ゼロからAIモデルを開発する場合と比較して、開発期間を70%以上短縮できるケースもあります。特に、大規模なデータセットの収集や学習インフラの構築が不要になるため、初期投資を抑えられます。
また、AIの専門家が少ない組織でも、Hugging Faceのシンプルなインターフェースを使えば、高度なAI機能を実装できます。これにより、AI人材の採用コストや外部委託費用を削減しながら、デジタルトランスフォーメーションを加速できるのです。
さらに、常に最新のAI技術にアクセスできる点も大きな価値です。Hugging Faceコミュニティでは、最新の研究成果が迅速に実装・共有されるため、自社で研究開発を行わなくても、常に最先端のAI技術を活用することができます。
Hugging Faceと競合プラットフォームの機能比較
AI開発プラットフォームにはさまざまな選択肢がありますが、Hugging Faceには独自の強みがあります。
OpenAI APIと比較すると、Hugging Faceはオープンソースでカスタマイズ性が高く、モデルを完全にコントロールできる点が大きな違いです。一方、OpenAI APIは使いやすさと高性能さで優れていますが、ブラックボックス的な側面があります。
TensorFlow HubやPyTorch Hubと比較すると、Hugging Faceはより統合されたエコシステムと、使いやすいインターフェースを提供しています。特に、モデルの検索、データセットの活用、コミュニティの活発さにおいて優位性があります。
クラウドプロバイダー(AWS、Azure、GCP)のAIサービスと比較すると、Hugging Faceはベンダーロックインのリスクが低く、より柔軟な導入が可能です。
ただし、大規模なインフラ管理においては、クラウドプロバイダーの方が優れている場合もあります。
Hugging Face導入時の懸念点
Hugging Face導入を検討する際には、以下の点に注意が必要です。
セキュリティとプライバシーの観点では、公開モデルを使用する場合のデータ漏洩リスクや、独自モデルを共有する際の知的財産権の問題を考慮する必要があります。特に、機密性の高いデータを扱う場合は、プライベートリポジトリの活用やオンプレミス環境での運用を検討すべきでしょう。
コスト面では、基本的な機能は無料で利用できますが、大規模なデプロイやプライベートモデルの管理には有料プランが必要になります。長期的なコスト予測を立てた上で導入を判断することが重要です。
また、チームの学習コストも考慮すべき点です。Hugging Faceは比較的学習曲線が緩やかですが、それでも新しい技術の導入には一定の教育コストがかかります。段階的な導入と社内トレーニングの計画が成功の鍵となるでしょう。
Hugging Face活用の将来性と発展可能性
Hugging Faceエコシステムは急速に成長しており、AIの民主化をリードする存在となっています。今後は以下のような発展が期待されます。
マルチモーダルAIの領域では、テキスト、画像、音声を統合的に扱うモデルが増加していくでしょう。これにより、より自然で高度なAIアプリケーションの開発が容易になります。
エッジコンピューティングへの展開も進んでおり、軽量化されたモデルをモバイルデバイスやIoTデバイスで動作させる取り組みが活発化しています。
これにより、オフラインでも動作するAIアプリケーションの開発が可能になります。
また、企業向け機能の強化も進んでおり、セキュリティやガバナンス、スケーラビリティの面での改善が継続的に行われています。このことから、今後はより多くのエンタープライズユースケースにおいてHugging Faceが活用されるようになるでしょう。
オープンソースAIのエコシステムの中心として、Hugging Faceの影響力はさらに拡大すると予想され、早期に導入することで競争優位性を獲得できる可能性があります。
まとめ:Hugging Faceで実現するAI開発の効率化と未来の可能性

本記事では、AI開発を効率化する「Hugging Face」について解説しました。このプラットフォームは、事前学習済みモデルやデータセットの共有、開発ツールの提供を通じて、AI開発の民主化に貢献しています。わずか数行のコードで高度なAI機能を実装できる手軽さは、企業のDX推進において大きな強みとなります。
Hugging Faceの魅力は、専門知識や大規模リソースがなくても高品質なAIを活用できる点にあります。マルチモーダルAIやエッジコンピューティングへの展開など、将来性も非常に高いプラットフォームです。
AI導入を検討している方は、まずはアカウント作成と基本モデルの試用から始めてみてください。
AIの活用が競争力の鍵となる現代、Hugging Faceはビジネス成長の強力な味方となるでしょう。

【生成AI活用でお困りではないですか?】
株式会社アドカルは主に生成AIを活用したマーケティング支援や業務効率化に強みを持った企業です。
貴社のパートナーとして、少数精鋭で担当させていただくので、
「生成AIを業務に活用したい」
「業務効率を改善したい」
「自社の業務に生成AIを取り入れたい」
とお悩みの方は、ぜひ弊社にご相談ください。
貴社のご相談内容に合わせて、最適なご提案をさせていただきます。
サービスの詳細は下記からご確認ください。無料相談も可能です。
この記事でわかることを1問1答で紹介
Q:Hugging Faceとは何ですか?
A: AI開発の効率化を支援するオープンソースプラットフォームで、事前学習済みモデルやデータセット、開発ツールなどを無料で提供しています。
Q:なぜHugging Faceが注目されているのですか?
A: ChatGPT以降の生成AIブームで、誰でも簡単にAI開発ができる環境を提供しているため、注目が急上昇しています。
Q:どのような課題を解決できますか?
A: 開発コストの削減、専門知識不足、計算リソース不足、知識共有の難しさなど、AI開発における障壁を総合的に解消できます。
Q:Hugging Face Hubにはどんな機能がありますか?
A: 以下の4機能が中心です:
Models(事前学習済みAIモデル)
Datasets(高品質な学習データ)
Spaces(デモの公開・共有)
Docs(公式ドキュメントと学習リソース)
Q:代表的なライブラリには何がありますか?
A:Transformers:自然言語・画像・音声処理に対応
Datasets:豊富なデータの簡単取り扱い
Tokenizers:高速トークン化処理
Accelerate:GPU・TPUなど環境依存の解消
Q:どんなAIモデルが使えますか?
A:自然言語処理(NLP):BERT, GPT-2, T5など
画像認識:ViT, DETRなど
音声認識:Wav2Vec 2.0, Whisperなど
マルチモーダル:CLIP, LLaVAなど、複数の情報を同時に処理できるモデルもあります。
Q:初心者でも使えますか?
A: はい。Python環境があれば、5行のコードで感情分析や要約が可能です。公式チュートリアルやサンプルコードも充実しています。
Q:自社データでAIをカスタマイズすることはできますか?
A: 可能です。ファインチューニング機能により、業界特有のデータに最適化されたモデルを作成できます。
Q:開発したモデルは共有できますか?
A: はい。Hugging Face Hub上で公開・非公開を選択でき、Model Cardやライセンス設定も簡単に行えます。
Q:導入前に知っておくべき注意点はありますか?
A: セキュリティ、知財リスク、長期的な有料プランコスト、社内教育の必要性などを事前に確認しましょう。
Q:Hugging Faceは今後どう発展しますか?
A: マルチモーダルAI、エッジデバイス対応、エンタープライズ機能強化など、今後さらに多様なビジネス活用が期待されています。


