
LLMとは?仕組みから導入方法までわかりやすく解説!
この記事でわかること
- LLMとは何か?基本概念と仕組みの解説
- チャットボットや他のAI技術との違い
- LLMの導入ステップと活用方法の実例
- 導入前に知っておくべきリスクと対策

人工知能(AI)の急速な進化により、ChatGPTやGeminiなどの対話型AIが私たちの日常に溶け込みつつあります。皆さんも一度は使ったことがあるのではないでしょうか?
これらのサービスを支える核心技術が「LLM(Large Language Model:大規模言語モデル)」です。膨大なテキストデータから学習し、人間のような自然な会話や文章作成を可能にするLLMは、ビジネスの効率化から創造的な表現まで、様々な分野で革新をもたらしています。
本記事では、AIの専門知識がない方でも理解できるよう、LLMの基本概念から実践的な活用法まで、わかりやすく解説します。変化の激しいAI時代だからこそ知っておきたい、LLMの「いま」と「これから」をご紹介します。
目次
LLMとは?ChatGPTを支える大規模言語モデルの基本を理解する

ChatGPTなどの生成AIが社会に浸透する中、その基盤となっている「LLM(大規模言語モデル)」への関心が高まっています。ビジネスでの活用が進む今、LLMの基本を理解することが必要不可欠と言えるでしょう。
AIのコミュニケーション能力を革新したLLMの実態
LLMの登場は、AIのコミュニケーション能力に革命をもたらしました。従来のAIが単純な応答や限られた範囲での会話しかできなかったのに対し、LLMは人間のような自然な対話や複雑な質問への的確な回答を生成できるようになったのです。
2022年末にChatGPTがリリースされて以来、LLMは膨大なテキストデータから言語の規則性やパターン、ニュアンスまでをも深く学習し、文脈を理解して適切な応答を生成できる単なる「機械的な応答」から「理解を伴うコミュニケーション」を可能にしました。
LLMの正式名称と基本的な定義
LLMとは「Large Language Models(大規模言語モデル)」の略称です。従来の言語モデルと比較して「計算量(処理する仕事量)」「データ量(学習した情報量)」「パラメータ数(モデル内の調整可能な値の数)」という3つの要素が桁違いに大きい点が特徴です。
LLMは自然言語処理(NLP)の一種でありながら、特にテキストの理解と生成に特化しており、大量のテキストデータを学習することで、文脈の把握や意味の理解、適切な文章生成などが可能になります。言い換えれば、「人間の言葉を理解し、それに対して適切に応答できる巨大な言語処理エンジン」と表現できるでしょう。
身近な例で理解する言語モデルの基本概念
言語モデルをより身近に理解するために、スマートフォンの予測変換機能を例に考えてみましょう。
あなたが「おはよう」と入力すると、次に「ございます」などの候補が表示されます。これは、多くの人が「おはよう」の後によく使う言葉のパターンを学習しているからです。言語モデルも同様の原理で動作し、ある言葉の後に続く可能性の高い言葉を予測します。
LLMはこの仕組みをさらに発展させ、単語レベルではなく文章全体の文脈を理解します。例えば「リンゴが木から落ちた」という文の後に続く内容を予測する場合、重力の法則に関連する内容である「重力」「ニュートン」「物理法則」といった、文脈に適した内容を生成できるのです。
LLMと他のAI技術の違いをわかりやすく解説

AI技術の世界では似たような用語が多く混同されがちです。ここではLLMと他のAI技術との違いを明確にし、それぞれの関係性を解説します。
LLMとチャットボットの機能・目的・能力の明確な区別
LLMとチャットボットは根本的に異なります。LLMは「言語を理解し生成する能力を持ったAIモデル」であるのに対し、チャットボットは「ユーザーと対話するためのアプリケーション」です。
つまり、LLMは「エンジン」、チャットボットはそのエンジンを搭載した「車」のような関係です。最新のチャットボットはLLMを搭載していることが多いですが、すべてのチャットボットがLLMを使用しているわけではありません。LLMを活用したチャットボットは、より自然で柔軟な対話が可能になり、複雑な質問や曖昧な表現にも対応できる点が大きな違いです。
LLMが生成AIの中核技術として果たす具体的役割
生成AI(Generative AI)は、テキスト、画像、音声、動画など新しいコンテンツを生成できるAI技術の総称です。LLMはその中でもテキスト生成において重要な役割を果たしています。
LLMは生成AIのサブセットであり、テキストデータの処理に特化しています。例えば、ChatGPTやGeminiなどの対話型AIサービスはLLMを基盤としています。また、LLMの言語理解能力は、画像生成AIに適切な指示を出したり、生成された内容を評価したりする際にも活用されています。
LLMが従来の自然言語処理から進化した3つのポイント
LLMは従来の自然言語処理(NLP)技術から大きく進化し、主に3つのポイントがあります。
1つ目は「双方向の文脈理解」です。従来のNLPモデルは一方向の情報処理が主流でしたが、LLMは文章全体を双方向に深く理解できます。
2つ目は「転移学習能力」です。LLMは一度学習した知識を異なるタスクに応用できます。例えば、翻訳のために学習したモデルが、要約や質問応答などの異なるタスクにも対応できるようになりました。
3つ目は「少数データからの学習能力」です。LLMはわずかな事例から新しいタスクを学習できるため、特定の目的に合わせた追加学習(ファインチューニング)が効率的になりました。
「大規模」が意味するLLMの技術的優位性と特徴
LLMの「大規模」という特徴は質的な変化をもたらす重要な要素で、主に3つの側面があります。
1つ目はパラメータ数の増加です。最新のLLMでは数千億から1兆を超えるパラメータを持ち、複雑なパターンの認識や微妙なニュアンスの理解が可能になりました。
2つ目は学習データの質と量です。LLMは膨大なインターネット上のウェブサイト、書籍、論文などから学習し、幅広い知識や表現を獲得しています。
3つ目は計算リソースの進化です。大規模なGPUクラスターを用いた並列計算により、従来は不可能だった規模のモデル訓練が可能になりました。
図解でわかるLLMの動作原理と仕組み
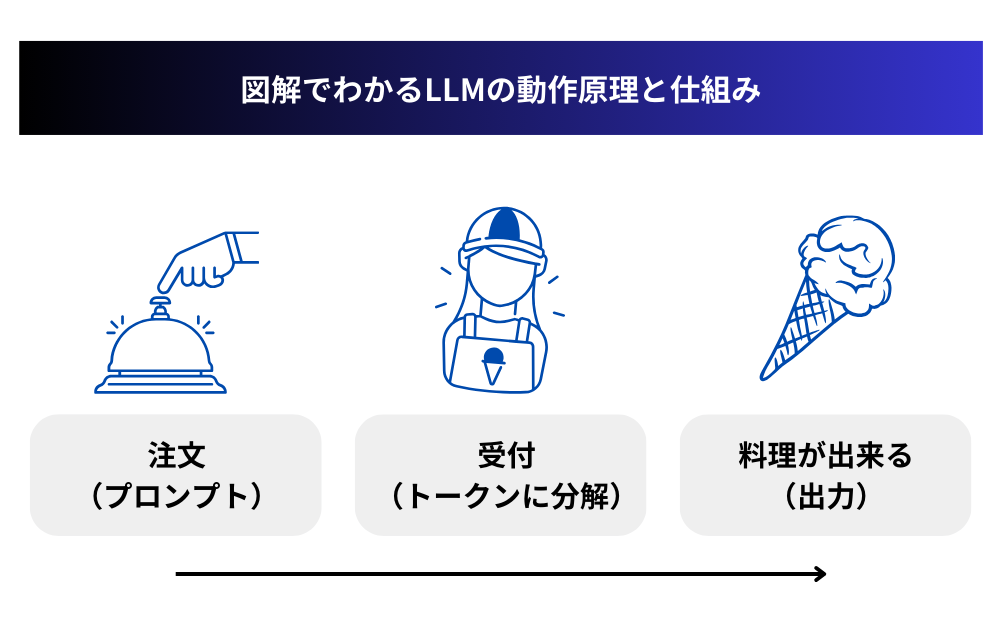
LLMは複雑な技術ですが、その基本的な仕組みは身近な例えを使って理解することができます。ここでは、専門的な知識がなくてもイメージしやすいように解説します。
レストランの例で理解するトランスフォーマー技術
LLMの中核となる「トランスフォーマー」技術は、高級レストランの厨房のようなものと考えられます。
お客さん(ユーザー)から注文(プロンプト)が入ると、受付係(トークナイザー)によって伝票(トークン)に分解されます。例えば「本日のおすすめ料理を教えてください」という注文は、「本日」「の」「おすすめ」「料理」「を」「教えて」「ください」といった個別の伝票に分けられます。
次にトランスフォーマーの核心部分である「アテンションメカニズム」は、複数のシェフが連携して作業するようなものです。各シェフ(アテンションヘッド)は伝票の異なる部分に注目し、それぞれの関連性を理解します。最終的にはこれらの情報を統合して美味しい料理(出力)を提供します。
入力から出力までの5ステップを簡単に解説
LLMが入力されたテキストを処理し、回答を生成するまでの流れは、以下の5つのステップです。
- トークン化:入力テキストを「トークン」と呼ばれる単位に分割します。
- 文脈理解:各トークンがどのように関連しているかを分析します。
- エンコード:トークンと関係性の情報を数値データ(ベクトル)に変換します。
- デコード:学習したパターンに基づいて、次に続く可能性の高いトークンを予測します。
- 出力生成:最も適切と判断されたトークンを順次選択し、まとまったテキストとして出力します。
「パラメータ」とは何か?そのイメージと重要性
LLMの「パラメータ」は、モデルが学習する過程で調整される数値のことで、「AIの脳内にある知識の集合体」です。
料理人が持つ「味付けの感覚」に例えると理解しやすいでしょう。熟練の料理人は、どの食材にどれくらいの塩や調味料を加えれば美味しくなるかを経験から知っています。同様に、LLMのパラメータは「言語の感覚」を数値として保持しています。
最新のLLMでは数千億から1兆を超えるパラメータがあり、これによって人間のような自然な文章生成や複雑な質問への回答が可能になっています。
LLMが「学習」するとはどういうことか
LLMの「学習」とは、大量のテキストデータから言語パターンを見つけ出し、パラメータを調整していくプロセスです。
主に2段階で行われます。「事前学習」では、インターネット上のテキスト、書籍、論文など膨大なデータを読み込み、次に続く言葉を予測する訓練を繰り返します。「ファインチューニング」では、特定の目的に合わせた追加学習を行います。
この学習プロセスにより、LLMは初めて見る質問に対しても、文脈を理解して適切に応答できる柔軟に応答する能力を獲得しています。
有名LLMの特徴比較と選び方

数多くのLLMが開発され、それぞれに特徴があります。ここでは、代表的なLLMの特徴と選定のポイントを解説します。
ChatGPTの基盤となるGPTシリーズの特徴
OpenAIのGPTシリーズは最も広く知られているLLMです。GPT-3.5は約1,750億のパラメータを持ち、コストパフォーマンスに優れています。GPT-4はさらに高性能で、複雑な指示の理解力や正確性が向上し、画像も処理できるマルチモーダル機能を備えています。最新のGPT-4oは反応速度が従来より3倍以上速く、音声対応も強化されています。
GPTシリーズの強みは汎用性の高さと使いやすさですが、コスト面やプライバシー懸念などの注意点もあります。
Google製LLMの強みと用途別おすすめポイント
GoogleのLLMもそれぞれ特徴が異なります。BERTは双方向の文脈理解に優れ、検索エンジンの質問応答などに強みがあります。LaMDAは対話に特化し、自然な会話の流れを維持する能力に優れています。PaLMは推論や論理的思考を必要とするタスクで高いパフォーマンスを示します。
最新のGemini 2.5 Proは長文の処理能力が向上し、100万トークンまでの文脈理解が可能になりました。特に専門分野での深い分析や、大量の文書を参照する必要がある業務に適しています。
オープンソースLLMが選ばれる理由とメリット
オープンソースLLMは、企業独自のカスタマイズやセキュリティ要件の厳しい分野で注目されています。MetaのLLaMA、スタンフォード大学のAlpaca、カリフォルニア大学のVicunaなどが代表例です。
最大の魅力は自社環境での実行とカスタマイズが可能な点です。自社の機密データを外部に送信せずに処理できるため、セキュリティやプライバシーの懸念が軽減されます。また、特定の業界や用途に合わせた「ドメイン特化型LLM」の開発も容易です。
導入には技術力が必要ですが、長期的にはコスト削減が見込めるでしょう。
目的別:最適なLLMの選定基準
LLM選びで最も重要なのは、活用目的を明確にすることです。
例えばカスタマーサポート自動化なら対話の自然さと多言語対応が重要で、GPT-4やGeminiが適しています。社内のナレッジベース構築には長文理解と専門知識の正確さが求められ、Gemini 2.5 Proや専門分野に特化したオープンソースLLMが効果的です。セキュリティ要件が厳しい場合は、自社環境で運用可能なLLaMAなどのオープンソースLLMを検討すべきです。予算や技術リソースも重要な判断材料です。
最終的には、複数のLLMを試験導入し、実際のユースケースでその性能を評価することが最も確実な選定方法と言えるでしょう。
手順で学ぶLLMの導入ステップと成功のポイント

LLMの可能性に興味を持っても、具体的にどう導入すればよいか悩む企業は少なくありません。ここでは、実践的な導入手順と成功のポイントを解説します。
LLM導入の第一歩:目的設定とKPIの具体化
LLM導入の最初のステップは明確な目的設定です。社内の「ペインポイント(痛点)」を洗い出し、LLMで解決可能なものを選び、優先順位をつけます。
次に、LLM導入の成果を測定するKPI(重要業績評価指標)を設定します。定量的指標としては「応答時間の短縮率」「処理可能な問い合わせ数の増加」などが考えられます。定性的指標としては「ユーザー満足度」「従業員の業務満足度」などを設定しましょう。
目標と指標が決まったら、小規模な検証(PoC)の計画を立て、本格導入前にLLMの効果を確認することが重要です。
予算別LLM実装アプローチ:API活用による段階的な導入
LLM導入は、予算や組織の規模に応じた段階的なアプローチが効果的です。
小規模予算(~100万円)であれば、既存のLLMサービスのAPIを活用するのが最も効率的です。中規模予算(100万円~500万円)では、APIを活用しつつも、特定のユースケース向けにLLMのカスタマイズを進めることができます。大規模予算(500万円~)では、オープンソースLLMをベースにした自社専用モデルの構築や、複数の業務システムとLLMを連携させた包括的なAIプラットフォームの開発が可能です。
どのアプローチでも、初期の小さな成功体験を積み重ね、段階的に拡大していくことがリスクを抑えながら着実に成果を出すための重要な戦略となります。
自社特化型LLM構築のための社内データ活用
より高度なLLM活用を目指す場合、自社のデータや知識をLLMに取り込む「特化型LLM」の構築が効果的です。これによって汎用的なLLMでは難しい、専門性の高い業務や独自のニーズに対応することができます。
まず、活用する社内データを選定します。次に、収集したデータを前処理し、LLMが利用しやすい形に整えます。データの準備ができたら、「ファインチューニング」と「RAG(検索拡張生成)」のいずれかの方法でLLMとの連携を行います。最後に、セキュリティとコンプライアンスの観点から、データの取り扱いポリシーを明確にします。
LLM導入後の効果検証と改善のためのPDCAサイクル
LLM導入は一度きりの取り組みではなく、継続的な改善が必要です。導入直後から定期的なモニタリングを行い、設定したKPIの達成状況を測定するとともに、ユーザーからのフィードバックを収集します。
収集したデータに基づいて改善計画を立て、LLMシステムを更新し、再び効果測定を行います。このPDCAサイクルを継続することで、LLMの精度と有用性は徐々に向上していきます。
LLMの限界と注意点:導入前に知っておくべきこと

誤情報生成(ハルシネーション)とその対処法
LLMの最も注意すべき課題の一つが「ハルシネーション(幻覚)」と呼ばれる現象です。これは、LLMが実際には存在しない情報や事実と異なる回答を、正しいかのように生成してしまう問題です。「AIに嘘をつかれている」という状態です。
対処法としては、「RAG(検索拡張生成)」と呼ばれる外部の情報源を参照しながら回答する手法の導入、LLMの出力に「確信度」を表示する機能の追加、人間による検証プロセスの組み込みなどが有効です。特に、業務上の重要な意思決定にLLMを活用する場合は、複数の情報源と照合する習慣をつけることが大切です。
知的財産権とプライバシーに関する法的リスク
LLMの利用に関連する法的リスクとして、知的財産権とプライバシーの問題があります。LLMが生成したコンテンツの著作権帰属がまだ不明確な場合があり、意図せず著作権を侵害してしまう可能性があります。また、社内の機密情報や顧客データをLLMに入力する際には情報漏洩のリスクにも注意が必要です。
プライバシーの面では、個人情報保護法との整合性を確保することが重要です。これらのリスクに対処するためには、法務部門との連携、利用規約や免責事項の整備、データの匿名化処理の徹底などが有効です。
セキュリティ確保のための具体的対策
LLMの活用には情報セキュリティの観点からも慎重な対応が求められます。プロンプトインジェクション攻撃への対策として、ユーザー入力の検証や機密情報へのアクセスを制限することが重要です。
データ漏洩リスクへの対応も必須で、商用LLMのAPIを使用する場合は機密情報や個人情報の事前削除または匿名化が必要です。また、アクセス制御と監査体制の整備も重要な対策です。
LLMを安全に活用するためには、技術的対策だけでなく、利用者への教育や明確なガイドラインの整備など、組織的な取り組みも必要です。
運用コストと環境負荷の懸念
LLM導入を検討する際には、継続的な運用コストや環境への影響も考慮することが重要です。APIの利用料金だけでなく、インフラ整備費、人材育成費などを含めた総所有コスト(TCO)を算出すべきです。
環境負荷の面では、大規模なLLMの学習や推論には膨大な計算リソースが必要となり、それに伴うエネルギー消費と炭素排出が課題です。これらの課題に対しては、必要最小限の規模のモデル選定や効率化技術の採用などが有効です。
業界別:LLMがもたらす変革と未来展望

LLMの活用は業界を問わず広がりつつありますが、その効果や活用方法は業種によって異なります。ここでは、主要産業におけるLLM活用の現状と近い将来の展望について解説します。
製造業の業務効率と品質管理を革新するLLM活用モデル
製造業では、技術文書の活用とナレッジ管理にLLMが変革をもたらしています。膨大な量の技術マニュアル、図面、故障事例などのデータから必要な情報を瞬時に抽出し、問題解決に役立てることが可能になりました。品質管理の面でも、製品検査データの分析やパターン認識にLLMが活用され始めています。
サービス業界全体を変革するLLMの現在進行形の導入効果
サービス業界では、顧客とのコミュニケーション強化にLLMが活用されています。24時間対応可能なAIチャットボットによる問い合わせ対応は、顧客満足度の向上と同時に、スタッフの業務負荷軽減をもたらしています。また、顧客の問い合わせ内容をLLMが分析することで、マーケティング戦略の精度向上にも貢献しています。
クリエイティブ産業でLLMが実現する創作と価値の新領域
クリエイティブ産業では、LLMが「共同クリエイター」としての役割を担い始めています。広告業界では、ターゲット層や商品特性に合わせたキャッチコピーの候補をLLMが生成し、クリエイターがそれをブラッシュアップする手法が一般化しつつあります。
クリエイターの役割は「一から作り上げる」ことから「AIの出力を編集・洗練させる」方向へとシフトし始めており、パーソナライズされたコンテンツ制作の可能性も広がっています。
業界横断的なLLM技術進化の5年後シナリオと準備すべき対応
今後5年間でLLM技術とその活用は大きく進化すると予想されます。主な変化としては、テキストだけでなく画像や音声などの複数の情報を扱える「マルチモーダル化」の進展、特化の業種や業界に特化した「特化型LLM」の普及、組織文化の変革などが挙げられます。
このような変化に備えるために企業が今から準備すべき対応としては、データ整理と標準化の推進、社内AI人材の育成、実験と学習を奨励する組織文化の醸成が重要です。特に重要なのは、LLMを単なる業務効率化ツールとしてだけでなく、新たな価値創造やビジネスモデル変革の機会として捉える視点です。
まとめ:LLMの理解から始める自社のAI活用戦略
ChatGPTに代表される生成AIの浸透により、ビジネスのAI活用は新たな段階に入りました。その基盤となるLLM(大規模言語モデル)の理解は、効果的なAI戦略の出発点です。LLMは単なるチャットボット技術ではなく、言語理解と生成の基盤として、業務プロセスやサービスに変革をもたらします。
導入には明確な課題設定から始め、APIを活用した小規模実験から段階的に拡大することが効果的でしょう。ハルシネーションや法的リスクなどの課題にも適切に対処しながら進めることが重要です。
重要なのは最新技術の追求ではなく、自社の課題解決や新たな価値創造にどう役立てるかという視点です。技術とビジネスの両面から自社ならではのAI活用戦略を構築することで、真の競争優位性を獲得できるでしょう。

【生成AI活用でお困りではないですか?】
株式会社アドカルは主に生成AIを活用したマーケティング支援や業務効率化に強みを持った企業です。
貴社のパートナーとして、少数精鋭で担当させていただくので、
「生成AIを業務に活用したい」
「業務効率を改善したい」
「自社の業務に生成AIを取り入れたい」
とお悩みの方は、ぜひ弊社にご相談ください。
貴社のご相談内容に合わせて、最適なご提案をさせていただきます。
サービスの詳細は下記からご確認ください。無料相談も可能です。
この記事でわかることを1問1答で紹介
Q. LLMとは何の略ですか?
LLMは「Large Language Model(大規模言語モデル)」の略で、人間のような自然な文章を理解・生成できるAIモデルです。
Q. LLMとチャットボットの違いは?
A. LLMは言語を理解・生成するエンジンで、チャットボットはそのエンジンを使ったアプリケーションです。すべてのチャットボットがLLMを使っているわけではありません。
Q. LLMはどんな仕組みで動いているの?
A. LLMは「トークナイズ → 文脈理解 → エンコード → デコード → 出力生成」という5ステップで文章を処理します。
Q. LLMの活用にはどんな方法がありますか?
A. API活用、自社データでのファインチューニング、RAGによる連携など、予算や目的に応じた段階的な導入が可能です。
Q. LLMを導入するメリットは何ですか?
A. 自然な対話による業務効率化、ナレッジの整理、クリエイティブ作業の支援、顧客対応の自動化など、幅広い業務改革が可能になります。
Q. LLM導入前に気をつけるべきことは?
A. 誤情報生成(ハルシネーション)、知的財産権やプライバシーのリスク、セキュリティ、運用コストと環境負荷への配慮が必要です。
Q. どの業界でLLMは活用されていますか?
A. 製造業、サービス業、クリエイティブ業界など、あらゆる業種で導入が進んでいます。今後は特化型LLMの普及も予想されます。
Q. 自社に最適なLLMを選ぶには?
A. 活用目的を明確にし、用途に応じた性能やコスト、セキュリティ要件などをもとに複数モデルを比較・検証することが重要です。


