
教師なし学習とは?基礎知識から実践での活用方法まで完全解説!
この記事でわかること
- 企業における教師なし学習の活用と導入プロセス
- 必要なリソースと体制整備
- 導入時の課題とその対策

近年、AIや機械学習の技術が急速に発展し、さまざまな分野で活用されています。
その中でも「教師なし学習」は、正解データなしでパターンを発見する独自の手法として多くの企業や研究機関から重要視されています。
本記事では、教師なし学習の基本概念から実践的な活用方法、最新のトレンドまで徹底解説します。
AIや機械学習の初心者から、実際に教師なし学習を活用したいビジネスパーソンや開発者まで、幅広い読者に役立つ知識を提供します。
クラスタリングや異常検知、生成AIなど、教師なし学習の多様な手法とその可能性について、わかりやすく解説していきましょう。
目次
教師なし学習とは?AI初心者でもわかる基本概念
AIや機械学習の世界では様々な学習方法がありますが、その中でも「教師なし学習」は特に興味深いアプローチです。
正解データなしでAIがどのように学習するのか、その基本概念から詳しく解説していきます。
なぜ「教師なし」と呼ばれるのか?
教師なし学習が「教師なし」と呼ばれる理由は、文字通り「教師」となる正解データが必要ないからです。
教師あり学習では、「これは猫の画像です」「これは犬の画像です」といった正解ラベルを大量に用意して学習させますが、教師なし学習ではそうした正解ラベルは不要です。
代わりに、AIはデータそのものの中にある特徴やパターンを自分で見つけ出します。
人間でいえば、誰にも教えられなくても似たもの同士をグループ分けできる能力に近いでしょう。
これにより、正解がわからない状況でも、データの構造や関係性を見出すことができるのです。
どのようにデータからパターンを発見するのか?
教師なし学習では、データが本来持っている構造や特徴を分析することで、パターンを発見します。
具体的には、以下のようなプロセスが行われます。
まず、AIはデータの類似性や相違点を測る指標(距離やコサイン類似度など)を使って、データポイント間の関係性を計算します。
次に、その関係性に基づいて、似ているデータ同士をグループ化したり、データを低次元に圧縮したりします。
例えば、スーパーの購入データを分析する場合、「ワインを買う人はチーズも一緒に購入する傾向がある」といったパターンを自動的に発見します。
このように、教師なし学習は人間が気づかなかった関連性やグループを見つけることができるのです。
教師なし学習は主に以下のような作業を得意としています。
- データの自然なグループ分け(クラスタリング)
- 複雑なデータの単純化(次元削減)
- 異常データや不正の検出(異常検知)
- 新しいデータの生成(生成モデル)
機械学習における教師なし学習の位置づけは?
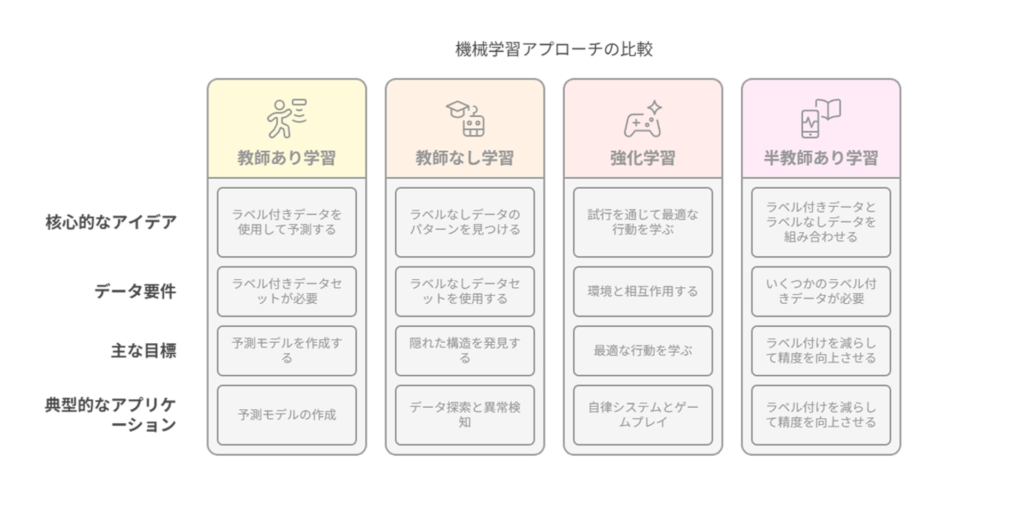
機械学習の手法は大きく分けて「教師あり学習」「教師なし学習」「強化学習」の3つがあります。
教師なし学習は、この中で特に探索的な役割を担っています。
教師あり学習が「過去のデータと答えから予測モデルを作る」方法であるのに対し、教師なし学習は「データの中に潜むパターンや構造を見つける」方法です。
一方、強化学習は「試行錯誤を通じて最適な行動を学ぶ」方法です。
また、最近では「半教師あり学習」という、教師あり学習と教師なし学習を組み合わせた手法も注目されています。
これは少量の正解ラベル付きデータと大量のラベルなしデータを併用するもので、教師なし学習の特徴を活かしながら精度を高められる利点があります。
教師なし学習は、特にデータの前処理や探索的分析、異常検知、生成モデルなどの分野で活躍しています。
機械学習プロジェクトの初期段階でデータの全体像を把握するために使われることも多く、深層学習やビッグデータ分析の基盤を支える重要な技術となっているのです。
教師なし学習と教師あり学習の違いを徹底解説
機械学習の二大アプローチである「教師あり学習」と「教師なし学習」。
名前は似ていますが、その学習方法や適用場面には大きな違いがあります。ここでは両者の違いを様々な観点から比較し、それぞれの特徴を明らかにしていきます。
学習方法の根本的な違いは何か?
教師あり学習と教師なし学習の最も根本的な違いは、「正解データ(ラベル)」の有無です。
教師あり学習では、「入力データ」と「あるべき出力(正解)」のペアを大量に与えることで、その関係性を学習させます。
たとえば、顧客データから「この人は契約を更新するか否か」を予測するモデルを作る場合、過去の顧客データと実際の更新結果のペアを学習させるのです。
一方、教師なし学習では正解ラベルは存在せず、入力データだけから何らかのパターンや構造を見つけ出します。
例えば顧客データから「似た傾向を持つ顧客グループ」を自動的に見つけ出すといった形です。
教師あり学習が「正解に基づく予測の最適化」を目指すのに対し、教師なし学習は「データの潜在構造の発見」を目指しているのです。
どんなデータが必要なのか?
データ要件も両者で大きく異なります。
教師あり学習では、入力データと正解ラベルのペアを大量に用意する必要があります。
例えば、スパムメール検知システムを開発するなら、大量のメールに「スパム」か「非スパム」のラベルを付けたデータセットが必要です。
このラベル付け作業は通常、人間が手作業で行うため、時間とコストがかかります。
対照的に、教師なし学習ではラベル付きデータは不要で、入力データのみを使用します。
例えば、ECサイトの購買データから顧客の購買パターンを分析する場合、「どの購買パターンが正しい」という正解はなく、データから自然に浮かび上がる傾向を見つけるだけです。
そのため、生データさえあれば分析を始められるという利点があります。
どのような問題解決に向いているのか?
両学習方法は得意とする問題タイプが異なります。
教師あり学習は以下のような明確な「予測」や「分類」タスクに最適です。
- 需要予測:将来の売上や需要を予測する
- 画像認識:写真の中の物体を識別する
- センチメント分析:テキストの感情を判定する
- 与信判断:融資の返済可能性を評価する
一方、教師なし学習は以下のような「発見」や「探索」タスクに適しています。
- 顧客セグメンテーション:類似顧客のグループ化
- 異常検知:通常と異なるパターンの発見
- 次元削減:複雑なデータの単純化
- トピックモデリング:文書の潜在的テーマの発見
つまり、「明確な答えを予測したい」場合は教師あり学習、「データの中に隠れたパターンを発見したい」場合は教師なし学習が向いていると言えるでしょう。
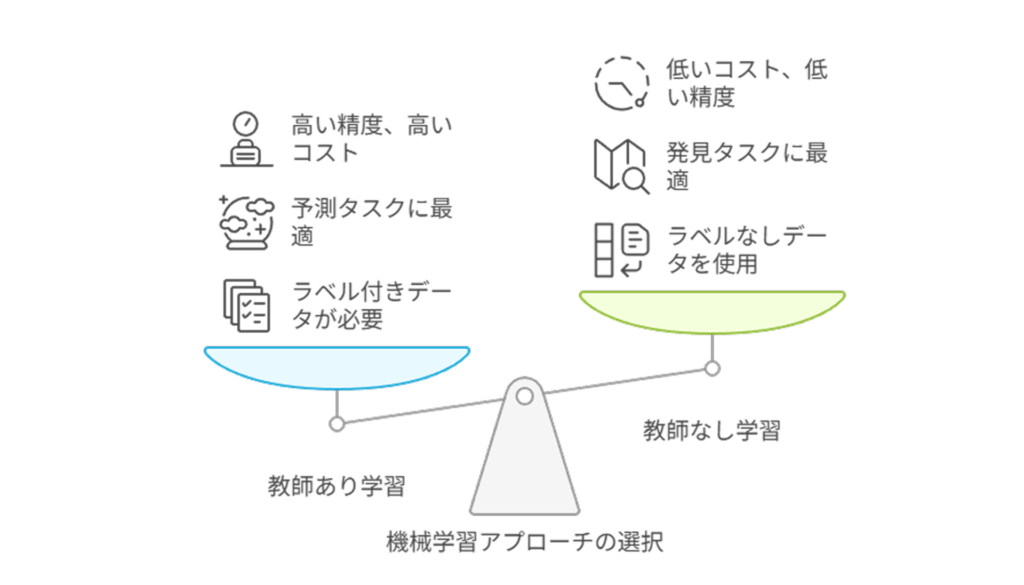
コスト面と精度のトレードオフ
選択にあたっては、コストと精度のバランスも重要な考慮点です。
教師あり学習は通常、より高い予測精度を実現できますが、正解ラベルの作成に大きなコストがかかります。
特に専門知識が必要な領域(医療画像の診断など)では、専門家による正確なラベル付けが必須となり、コストは更に膨らみます。
教師なし学習はラベル付けが不要なため初期コストは低いものの、結果の解釈や評価が難しいという課題があります。
「なぜこのようなグループ分けになったのか」の解釈には専門知識が必要で、ビジネス価値に直結させるためには追加の分析が必要になることもあります。
実際のプロジェクトでは、予算、目的、データの入手可能性などを考慮し、適切な学習方法を選択することが重要です。
時には、教師あり学習と教師なし学習を組み合わせた「半教師あり学習」が最適な選択となることもあります。
教師なし学習の5つの主要手法と特徴

教師なし学習にはさまざまな手法がありますが、特に重要なのが5つの主要アプローチです。
それぞれに独自の特徴と応用分野があり、目的に応じて適切な手法を選ぶことが成功の鍵となります。
ここでは、各手法の基本的な仕組みと活用法を解説します。
クラスタリング|顧客や商品を自動で分類する基本手法
クラスタリングは、データポイントを類似性に基づいて自動的にグループ(クラスタ)に分ける手法です。
例えば、顧客データを分析する場合、年齢、購買頻度、購入金額などの特徴に基づいて、自然と形成されるグループを見つけることができます。
代表的なアルゴリズムには、K-means(データをK個のクラスタに分割)、階層型クラスタリング(ツリー状の階層構造を作成)、DBSCAN(密度ベースのクラスタリング)などがあります。
クラスタリングはマーケティングでの顧客セグメンテーション、在庫管理での商品グループ化、画像認識での物体検出など、多様な分野で活用されています。
分析の初期段階で「データがどのような自然なグループに分かれるか」を把握するのに最適な手法と言えるでしょう。
次元削減:複雑なデータを単純化する技術
次元削減は、高次元データから重要な特徴だけを抽出し、より少ない次元で表現する手法です。
例えば、100の特徴を持つ顧客データが、実は2〜3の主要な軸で十分に表現できる場合があります。
代表的な手法には、PCA(主成分分析:データの分散が最大になる方向を見つける)、t-SNE(高次元データの局所的構造を保持したまま視覚化)、UMAP(最新の非線形次元削減法)などがあります。
次元削減は、データ可視化、特徴量圧縮、ノイズ除去などに活用され、機械学習の前処理としても重要です。
複雑なデータを人間が理解しやすい形に変換し、隠れたパターンを発見するのに役立ちます。
異常検知|製造・金融などで活躍する教師なしの定番応用
異常検知は、通常のパターンから逸脱したデータポイントを識別する手法です。
正常データの特徴を学習し、それと大きく異なるものを「異常」として検出します。
主な手法には、Isolation Forest(データポイントを孤立させる決定木)、One-Class SVM(正常データの境界を学習)、オートエンコーダ(再構成誤差を利用)などがあります。
異常検知は、製造ラインでの不良品検出、金融取引の不正検知、ネットワークセキュリティでの侵入検知、医療画像での異常発見など、多くの領域で活用されています。
正常な状態のデータさえあれば、明示的に異常データを用意せずとも監視システムを構築できる点が大きな利点です。
生成モデル:GAN・VAEによる新データ生成の仕組み
生成モデルは、既存のデータの分布を学習し、それに従った新しいデータを生成する手法です。
単なるデータ分析を超えて、「創造」に踏み込む点が特徴的です。
代表的な手法には、GAN(敵対的生成ネットワーク:生成器と識別器が競い合う)、VAE(変分オートエンコーダ:確率的に潜在空間を学習)、Flow-based models(可逆変換による生成)などがあります。
生成モデルは、画像生成(写真やイラストの自動生成)、データ拡張(学習データの人工的増加)、アノマリー検知(再構成誤差の利用)、創薬(新しい分子構造の提案)など多岐にわたる分野で革新を起こしています。
AIの創造性を示す最前線の技術といえるでしょう。
アソシエーション分析:データ間の関連性を見つける手法
アソシエーション分析は、データセット内のアイテム間の関連性や依存関係を発見する手法です。
最も有名な例は「ビールとおむつの法則」で、スーパーでビールを買う人はおむつも一緒に買う傾向があるという発見です。
代表的なアルゴリズムには、Apriori(頻出アイテムセットを段階的に発見)、FP-Growth(頻出パターンツリーを使用)、ECLAT(縦型データフォーマットでの高速処理)などがあります。
アソシエーション分析は、小売業での商品配置や推薦システム、ウェブサイトのナビゲーション設計、クロスセリング戦略の立案など、アイテム間の関係性を活用したいビジネスシーンで広く利用されています。
複雑なデータベースから有用な関連ルールを自動的に抽出できる点が強みです。
教師なし学習の実践的な活用事例5選
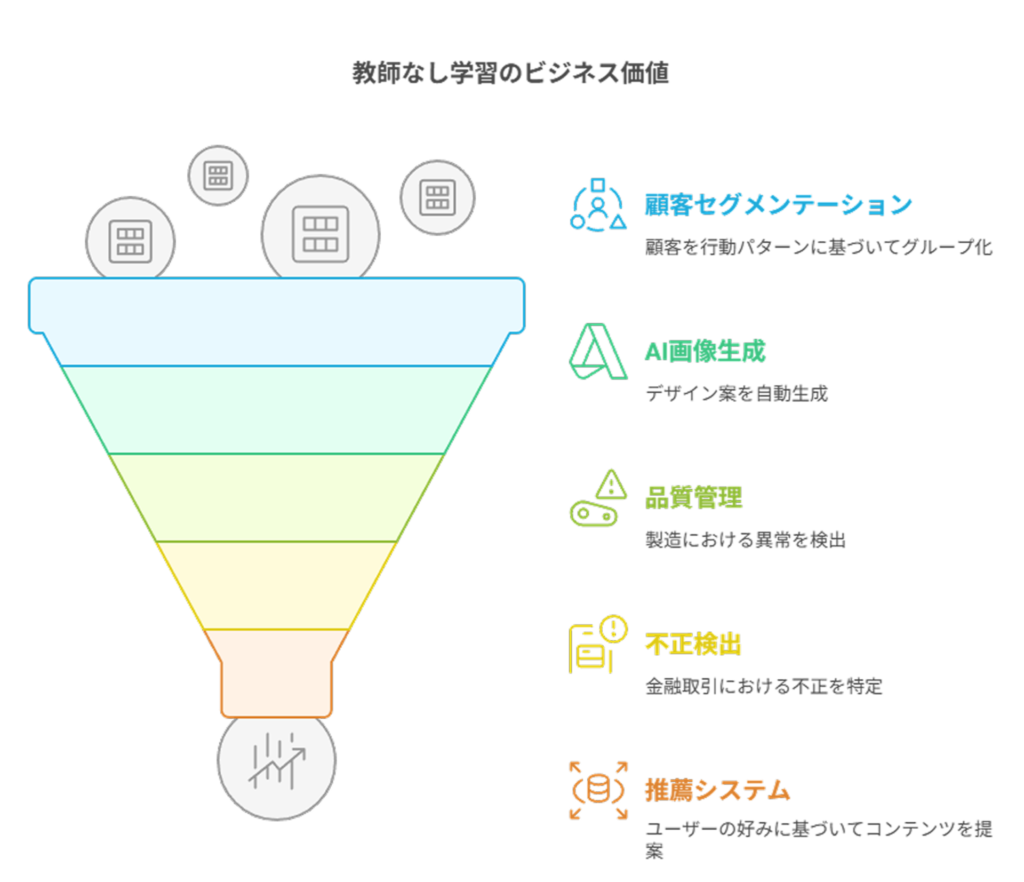
教師なし学習は様々な業界で実際に活用され、ビジネス価値を生み出しています。
ここでは、企業が教師なし学習を導入して成果を上げた事例を5つ紹介します。
自社での活用を検討する際の参考にしてください。
マーケティングでの顧客セグメンテーション実例
大手ECサイトでは、クラスタリング手法を用いて顧客を行動パターンや購買履歴に基づいて自動的にセグメント化しています。
K-meansアルゴリズムにより、「頻繁に購入するが少額」「稀に購入するが高額」「季節限定購入者」といった顧客グループを特定しました。
このセグメンテーションにより、各グループに最適化されたマーケティングキャンペーンを展開でき、あるアパレル企業ではEメールマーケティングのコンバージョン率が23%向上、顧客生涯価値が15%増加しました。
従来のデモグラフィックだけでなく行動データを基にしたセグメンテーションにより、より精緻なターゲティングが可能になりました。
教師なし学習の「データから自然と現れるグループを発見する」特性が、マーケティング戦略の質を向上させています。
画像生成分野でのAI画像生成技術の実例
ファッション業界では、GAN(敵対的生成ネットワーク)を活用してデザイン案や商品画像を自動生成する取り組みが進んでいます。
ある有名アパレルブランドでは、過去のデザインデータをGANに学習させ、新シーズンのデザイン案を生成するシステムを導入しました。
このシステムにより、デザイナーは自動生成されたデザイン案からインスピレーションを得ることができ、デザインプロセスが平均30%効率化されました。
また、生成された画像での市場調査により、顧客の反応を事前に評価できるようになりました。
GANの強みは完全に新しいものを創造できる点にあり、クリエイティブ産業で特に価値を発揮しています。
最終判断は人間が行うというハイブリッドアプローチが成功の鍵です。
製造業での異常検知による品質管理の実際
自動車部品製造業では、生産ラインのセンサーから得られる振動、温度、音響などのデータを用いて、異常検知による予防保全システムを導入しています。
ある大手メーカーでは、オートエンコーダを活用し、正常稼働時のパターンを学習させました。
システムは正常パターンから逸脱した状態を検出すると、メンテナンスチームに自動通知します。
導入により、設備の突発的故障が37%減少し、計画外のダウンタイムによる損失が年間約3億円削減されました。
教師なし学習を用いた異常検知は、複雑なパターンの異常も検出でき、新たな異常パターンにも対応できるため、製造ラインが変更されても再学習するだけで適応できる柔軟性が利点です。
金融業界での不正検出システムの仕組み
大手金融機関では、クレジットカード取引の不正検出に教師なし学習を活用しています。
従来の教師あり学習では既知の不正パターンしか検出できませんが、教師なし学習では新種の不正パターンも検出可能です。
Isolation Forestやオートエンコーダなどを用いて、通常の取引パターンからの逸脱を検出します。
ある国際的な決済プロバイダーでは、不正検出率が17%向上し、誤検出(正常な取引を不正と判断)が23%減少しました。
このシステムは常に進化する不正手法に対応でき、新たな不正パターンが出現しても「通常と異なる」限り検出可能です。
リアルタイム処理により、不正取引を即座にブロックし被害拡大を防止しています。
推薦システムにおける協調フィルタリングの活用法
動画ストリーミングや音楽配信プラットフォームでは、協調フィルタリングを用いた推薦システムを導入しています。
これは「似た嗜好を持つユーザーは似たコンテンツを好む」という原理に基づいています。
大手音楽ストリーミングサービスでは、視聴履歴や評価データから特徴量を抽出し、ユーザー間の類似性を計算します。
その結果に基づいて新しい楽曲を提案することで、ユーザーの平均視聴時間が31%増加し、サービス継続率が24%向上しました。
協調フィルタリングはコンテンツの内容自体を分析しなくても効果的な推薦が可能ですが、「コールドスタート問題」に対処するため、実際には教師あり学習やコンテンツベースのフィルタリングと組み合わせたハイブリッドアプローチが多く採用されています。
教師なし学習と他の機械学習手法の組み合わせ
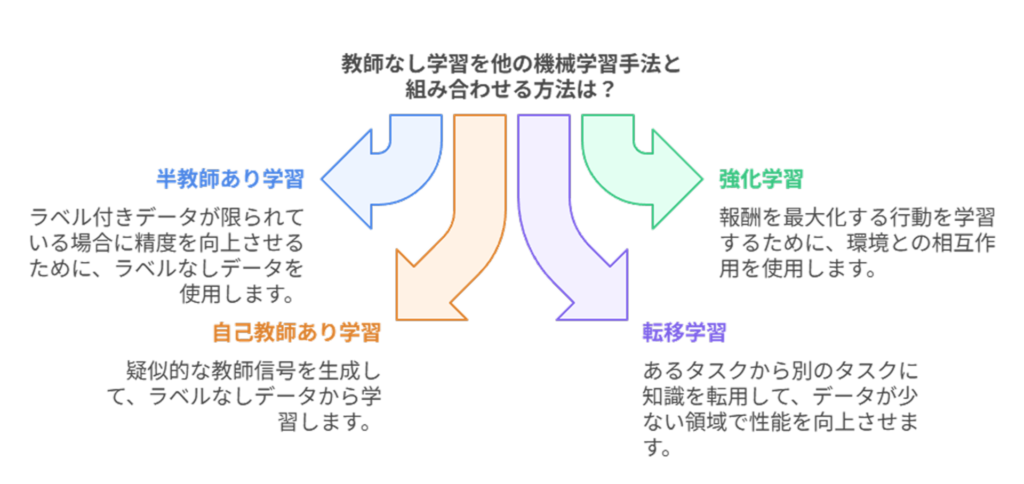
教師なし学習は単独でも価値がありますが、他の機械学習手法と組み合わせることでさらに強力なソリューションを構築できます。
ここでは、教師なし学習を他の学習手法と組み合わせた先進的なアプローチを解説します。
半教師あり学習で教師なし学習を補強する方法
半教師あり学習は、少量のラベル付きデータと大量のラベルなしデータを併用する手法です。
まず教師なし学習でラベルなしデータの構造を学習し、その知見をラベル付きデータによる教師あり学習に活かします。
医療画像診断では、専門医がラベル付けした少数の画像と、ラベルのない大量の画像を扱います。
オートエンコーダなどで全画像の特徴を学習し、その特徴空間上でラベル付きデータを用いた分類を行うことで精度を向上させます。
実際に、従来の教師あり学習に比べて90%少ないラベル付きデータで同等の精度を達成した事例もあり、特にラベル付けコストが高い領域で効果を発揮します。
強化学習との違いと併用可能なケース
強化学習は環境との相互作用を通じて報酬を最大化する行動を学習するアプローチで、教師なし学習とは異なりますが、両者は補完関係にあります。
教師なし学習は強化学習の前処理として活用できます。高次元の状態空間を持つロボット制御では、教師なし学習で状態空間を低次元に圧縮してから強化学習を適用することで効率化が図れます。
また、ロボットの物体把持など、環境のモデル化にも教師なし学習が役立ち、実環境でのトライアンドエラーを減らせます。
自動運転や工場自動化など安全性が求められる分野では特に重要です。
自己教師あり学習が変えた教師なし学習の可能性
自己教師あり学習は、データから「疑似的な教師信号」を自動生成して学習する手法です。
画像の一部を隠して隠した部分を予測する「マスク画像モデリング」などが代表例です。
この手法は従来の教師なし学習を拡張し、例えば顔認識システムでは、自己教師あり学習で特徴抽出器を学習し、少量のラベル付きデータで微調整することで、従来の10分の1のデータで同等の精度を達成しています。
BERTやGPTなどの大規模言語モデルも自己教師あり学習の一種であり、文章中の単語予測というタスクで学習された言語理解能力が様々な用途に転用されています。
転移学習と教師なし学習のハイブリッドアプローチ
転移学習とは、あるタスクで学習した知識を別のタスクに転用する手法です。
大規模なラベルなしデータで教師なし学習を行い、その学習済みモデルを特定タスク向けに微調整することで、データが少ない領域でも性能向上が期待できます。
医療画像分析では、一般的な医療画像で事前学習したモデルを希少疾患の検出に転用することで、限られたデータでも高い診断精度を実現しています。
このアプローチは専門領域や少数サンプル学習に効果的で、計算リソースが限られた環境でも高性能モデルを構築できる利点があります。
教師なし学習の実装ステップとPython活用法
理論を理解したら、次は実際にPythonで教師なし学習を実装してみましょう。
Pythonは豊富なライブラリが揃っており、初心者でも比較的簡単に機械学習モデルを構築できます。
基本から応用まで段階的に解説します。
scikit-learnで始める教師なし学習入門
scikit-learnは教師なし学習を始めるのに最適なライブラリです。
例えば、K-meansクラスタリングはたった数行で実装できます。
from sklearn.cluster import KMeans
import numpy as np
# サンプルデータ作成
X = np.array([[1, 2], [1, 4], [1, 0], [4, 2], [4, 4], [4, 0]])
# クラスタリングの実行
kmeans = KMeans(n_clusters=2, random_state=0).fit(X)
# クラスタの中心点
print(kmeans.cluster_centers_)
# 各データポイントのクラスタラベル
print(kmeans.labels_)
同様に、主成分分析(PCA)も簡単に実装できます。
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
X_reduced = pca.fit_transform(X)
scikit-learnの強みは、一貫したAPIと豊富なドキュメント、そして実装の速さです。
実験的なプロジェクトや高度な機能が必要ない場合には、まずscikit-learnから始めることをお勧めします。
TensorFlowとKerasによる高度な実装方法
より複雑なモデルや大規模データセットを扱う場合は、TensorFlowとKerasが適しています。
例えば、シンプルなオートエンコーダは以下のように実装できます。
import tensorflow as tf
from tensorflow.keras import layers
# エンコーダとデコーダの構築
encoder = tf.keras.Sequential([
layers.Dense(128, activation=’relu’),
layers.Dense(64, activation=’relu’),
layers.Dense(32, activation=’relu’),
])
decoder = tf.keras.Sequential([
layers.Dense(64, activation=’relu’),
layers.Dense(128, activation=’relu’),
layers.Dense(input_dim, activation=’sigmoid’)
])
# オートエンコーダの構築と学習
autoencoder = tf.keras.Sequential([encoder, decoder])
autoencoder.compile(optimizer=’adam’, loss=’mse’)
autoencoder.fit(X_train, X_train, epochs=50, batch_size=256)
TensorFlowとKerasを使えば、GANやVAEといった高度な生成モデルも実装できます。
GPUの活用やモデルの保存・読み込みなどの実用的な機能も充実していますが、初心者にはやや複雑なので、基本を理解してから挑戦するとよいでしょう。
実装時の課題と具体的解決策
教師なし学習の実装時には、いくつかの一般的な課題に直面します。
まず「次元の呪い」です。
高次元データでは距離の概念が曖昧になり、クラスタリングが効果的に機能しなくなります。
解決策としては、PCAなどで次元削減を行ってから他のアルゴリズムを適用することが効果的です。
もう一つの課題は、クラスタ数などのハイパーパラメータの決定です。
K-meansの場合、エルボー法やシルエットスコアを使ってクラスタ数を決定できます。
from sklearn.metrics import silhouette_score
import matplotlib.pyplot as plt
silhouette_scores = []
for k in range(2, 11):
kmeans = KMeans(n_clusters=k, random_state=0).fit(X)
score = silhouette_score(X, kmeans.labels_)
silhouette_scores.append(score)
plt.plot(range(2, 11), silhouette_scores)
plt.xlabel(‘クラスタ数’)
plt.ylabel(‘シルエットスコア’)
plt.show()
また、データの前処理も重要です。特に教師なし学習では、外れ値や特徴量のスケールが結果に大きく影響します。
StandardScalerなどを使って特徴量のスケーリングを行うことが推奨されます。
結果の評価指標と解釈方法
教師なし学習の結果を評価するには、タスクに応じた指標を使用します。
クラスタリングの場合、一般的にはシルエットスコア、Calinski-Harabasz指標、Davies-Bouldin指標などが使われます。
from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_score
# 各評価指標の計算
silhouette = silhouette_score(X, labels)
calinski = calinski_harabasz_score(X, labels)
davies = davies_bouldin_score(X, labels)
次元削減の評価には、保持された分散の比率やt-SNEによる可視化が有効です。
生成モデルでは、再構成誤差やInception Scoreなどが使われます。
結果の解釈も重要なポイントです。クラスタリング結果を解釈する際は、各クラスタの特徴を理解するために、クラスタごとの特徴量の平均値や分散を計算すると良いでしょう。
実際のビジネス文脈に沿った解釈が最も重要で、「このクラスタは高価値顧客を表している」といった具体的な意味付けができると、実用的な価値が高まります。
教師なし学習の最新トレンドと進化するテクノロジー
教師なし学習は日々進化を続けており、最先端の研究によって従来の限界を超える新たな技術が次々と生まれています。
今後の技術変化に対応するため、特に注目すべき最新トレンドを解説します。
コントラスティブ学習が切り開く新たな可能性
コントラスティブ学習は「似ているデータ同士を近づけ、異なるデータ同士を遠ざける」という原理で表現学習を実現します。
GoogleのSimCLRやOpenAIのCLIPなどが代表例です。
画像認識では、同じ画像の異なる角度やフィルタ処理をした版を「正のペア」として扱い、ラベルなしでも強力な特徴抽出器を構築します。
この技術の強みは、少量のラベル付きデータでの微調整で高性能を発揮する点で、医療画像や衛星画像など、ラベル付けが困難な分野で革新をもたらしています。
自己符号化器(オートエンコーダー)の進化
オートエンコーダーは近年大きく進化し、変分オートエンコーダー(VAE)やデノイジングオートエンコーダーなど多様なバリエーションが登場しています。
特にVQ-VAEやVQ-GANのような離散的な潜在表現を学習するモデルは、Stable Diffusionなどの画像生成技術の基盤となっています。
また、Transformerとオートエンコーダーの組み合わせにより、多様なデータに対応できる汎用的な表現学習も可能になっています。
大規模言語モデルにおける教師なし学習の役割
ChatGPTやGPT-4などの大規模言語モデル(LLM)の基盤には教師なし学習が大きく貢献しています。
これらは「次の単語を予測する」という自己教師ありタスクで膨大なテキストから学習し、文法、事実知識、推論能力を獲得します。
注目すべきは「スケール則」で、モデルサイズとデータ量を増やすほど予測性能が向上するだけでなく、算数の問題解決や簡単なプログラミングなど、明示的に教えていない能力が創発する現象が見られます。
マルチモーダル教師なし学習の最前線
マルチモーダル学習は、テキスト、画像、音声、動画など異なるモダリティを同時に扱う方法です。
OpenAIのCLIPはテキストと画像を同じ意味空間に埋め込み、テキストによる画像検索や画像内容の言語説明を可能にしています。
DALL-EやStable Diffusionのような文章から画像を生成するモデルもこの成果です。
最前線では「基盤モデル」の開発が進み、テキスト指示から動画生成、画像から音生成といった、より自然なマルチモーダルAIの実現が近づいています。
まとめ:教師なし学習の活用で何が可能になるのか
教師なし学習は、正解ラベルなしでデータの隠れたパターンを発見できる技術として、現代のビジネスに新たな可能性をもたらしています。
顧客セグメンテーションによるマーケティング最適化、異常検知による予防保全、生成AIによるコンテンツ創出など、その応用範囲は広がり続けています。
人間が気づかなかった関連性やグループを見つけ出す能力は、新たなビジネス機会の創出につながり、教師あり学習と組み合わせることで少ないラベルデータでも高精度なモデル構築が可能になります。
技術の進化とともに活用ハードルも下がっており、まずは自社データの探索的分析から始めることで、データに眠る可能性を引き出せるでしょう。
進化を続ける教師なし学習は、今後もビジネスにおけるデータ活用の中核を担い続けるといえます。
【生成AI活用でお困りではないですか?】
株式会社アドカルは主に生成AIを活用したマーケティングDXや業務効率化に強みを持った企業です。
貴社のパートナーとして、少数精鋭で担当させていただくので、
「生成AIを業務に活用したい」
「業務効率を改善したい」
「自社の業務に生成AIを取り入れたい」
とお悩みの方は、ぜひ弊社にご相談ください。
貴社のご相談内容に合わせて、最適なご提案をさせていただきます。
サービスの詳細は下記からご確認ください。無料相談も可能です。


