
半教師あり学習とは?学習手法やメリットを初心者向けに徹底解説
この記事でわかること
- 半教師あり学習とは
- 未ラベルデータを活用する半教師あり学習の実践的メリット
- 半教師あり学習を実装する主要アルゴリズムと選択法
- 半教師あり学習導入時の課題と効果的な対処法
- 半教師あり学習導入の事例

大量のラベル付きデータを用意する時間とコストに悩んでいませんか?半教師あり学習は、少量のラベル付きデータと大量の未ラベルデータを組み合わせることで、データラベリングの負担を大幅に削減しながら高精度なAIモデルを構築できる画期的な機械学習手法です。本記事では、半教師あり学習の基本概念から実践的なメリット、効果的なアルゴリズム選択法、業界別の活用事例まで徹底解説します。データ不足や、ラベリングコストに課題を感じている、AI開発者やデータサイエンティスト。機械学習プロジェクトの導入を検討している企業担当者にとって、未ラベルデータの可能性を最大限に引き出すための実践的なガイドとなるでしょう。
目次
半教師あり学習とは|ラベルあり・なしデータを組み合わせる機械学習手法
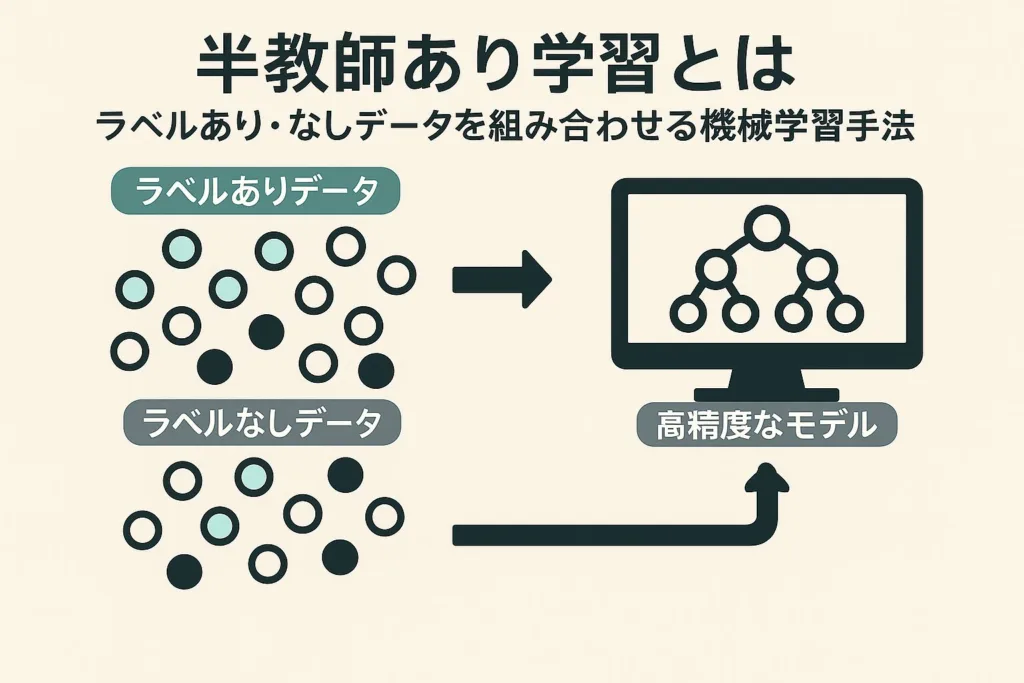
半教師あり学習は、教師あり学習と教師なし学習の中間に位置する機械学習手法です。少量のラベル付きデータと大量のラベルなしデータを同時に活用することで、データラベリングのコストを抑えながら高精度なモデルを構築できます。ビジネスシーンでは、限られたリソースで効率的に機械学習を導入したい場合に特に注目されています。
半教師あり学習の基本概念と機械学習における役割
半教師あり学習(Semi-supervised Learning)は、少量のラベル付きデータと大量のラベルなしデータを併用して学習を行う機械学習のアプローチです。この手法は、完全なラベル付けが困難または高コストな状況で、データの潜在的な構造を活用することを目的としています。
機械学習の世界では、教師あり学習と教師なし学習が広く知られていますが、半教師あり学習はこれらの中間に位置づけられます。特にラベル付けに専門知識が必要な医療画像分析や、膨大なデータ量を扱う自然言語処理などの分野で重要な役割を果たしています。
半教師あり学習の基本的な考え方は、ラベル付きデータから得られる監視情報と、ラベルなしデータから得られる分布情報を組み合わせることです。これにより、少ないラベル付きデータからでも、データの潜在構造を理解し、より正確な予測モデルを構築することが可能になります。実際に、適切に実装された半教師あり学習は、同量のラベル付きデータのみを使用した場合と比較して、予測精度を大幅に向上させるのです。
教師なし学習については『教師なし学習とは?基礎知識から実践での活用方法まで完全解説!』の記事で詳しく解説しております。
教師あり学習と半教師あり学習|データラベリングの違い
教師あり学習と半教師あり学習の最も顕著な違いは、必要なラベル付きデータの量にあります。教師あり学習では、すべての訓練データにラベルが付与されている必要があるのに対し、半教師あり学習では一部のデータにのみラベルが必要となります。
教師あり学習では、入力データと期待される出力(ラベル)のペアを使用してモデルを訓練します。例えば、メール分類タスクでは、「スパム」または「非スパム」というラベルが各メールに付与されています。モデルはこれらのラベルを基に、新しいメールを正しく分類できるよう学習します。
一方、半教師あり学習では、少量のラベル付きデータと大量のラベルなしデータを組み合わせて使用します。ラベルなしデータの分布情報を活用することで、ラベル付きデータだけでは見えてこない特徴やパターンを捉えます。この方法は、データラベリングのコストと時間を大幅に削減できる点が大きなメリットです。
実務においては、ラベル付けには専門家の知識や多大な労力が必要なケースが多いため、半教師あり学習はコスト効率の高い選択肢として注目されています。特に、大量のデータを扱う現代のAI開発において、その重要性はますます高まっているのです。
教師なし学習と半教師あり学習の組み合わせによる相乗効果
教師なし学習と半教師あり学習を組み合わせることで、より効果的な学習モデルを構築できます。教師なし学習はラベルなしデータからパターンや構造を見つけ出すことに長けており、半教師あり学習はそれらの情報をラベル付きデータの知識と統合します。
教師なし学習の主な手法には、クラスタリングや次元削減などがあります。これらの手法は、データの自然な集まりや重要な特徴を特定するのに役立ちます。例えば、クラスタリングによって類似したデータポイントをグループ化し、そのグループに少数のラベルを付けることで、半教師あり学習の初期入力として活用できます。
具体的な活用例として、まず教師なし学習でデータの前処理やクラスタリングを行い、その結果を基に半教師あり学習のモデルを訓練するというパイプラインが考えられます。このアプローチは特に、データの構造が複雑で、ラベル付けが難しい場合に効果的です。
両手法の組み合わせによる相乗効果は、実際の応用分野でも確認されています。例えば、画像認識では効果的な組み合わせ方法があります。まず教師なし学習を使って画像の特徴を抽出します。次に、その抽出した特徴を基に半教師あり学習で分類モデルを構築します。このアプローチにより、少ないラベル付きデータでも高い認識精度を達成できています。この組み合わせは、今後のAI開発において重要な戦略となるでしょう。
未ラベルデータを活用する半教師あり学習の実践的メリット
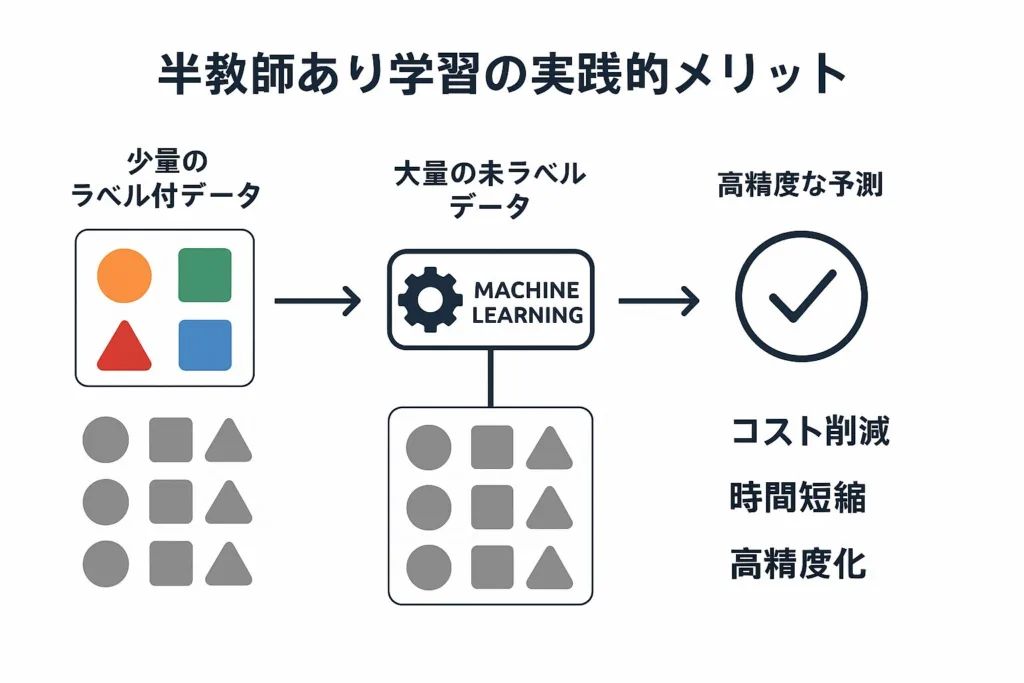
半教師あり学習の最大の特徴は、ラベル付けされていないデータを有効活用できる点にあります。多くの実世界の問題では、データの収集自体は比較的容易でも、それらに正確なラベル付けを行うには専門知識や多大な時間・コストが必要になります。このようなシチュエーションで、半教師あり学習は大きな威力を発揮します。
データラベリングコストと時間の大幅削減
データのラベル付けは機械学習プロジェクトにおいて最もコストと時間を要する工程の一つです。例えば、医療画像の異常検出では、専門医による正確な診断(ラベル付け)が必要となり、1件あたり数分から数十分の時間を要します。半教師あり学習では、全データの一部(典型的には10〜30%程度)にのみラベル付けを行うことで、残りの未ラベルデータも有効活用できます。
あるヘルスケア企業の事例を見てみましょう。X線画像の異常検出タスクにおいて、教師あり学習では10,000件のラベル付きデータが必要でした。一方、半教師あり学習では別のアプローチを取りました。2,000件のラベル付きデータと8,000件の未ラベルデータを組み合わせたのです。その結果、同等の精度を達成しながら、専門医の作業時間を約80%削減することに成功しました。
少量のラベル付きデータでも高精度なモデル構築が可能
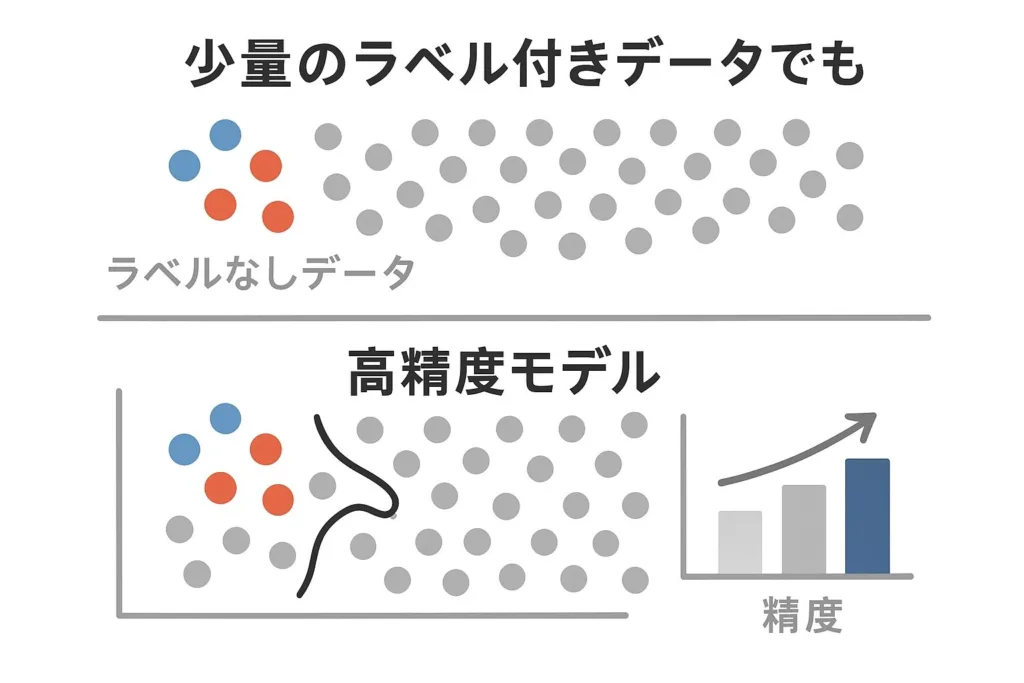
半教師あり学習の効果は、単なるコスト削減だけではありません。適切に実装された半教師あり学習モデルは、同じ量のラベル付きデータのみを使用した教師あり学習モデルと比較して、しばしばより高い精度を達成します。
これは、ラベルなしデータから学習できる「データの分布構造」に関する情報が、モデルの汎化性能を向上させるためです。特に、データが自然に形成するクラスター構造や多様体構造を学習することで、限られたラベル付きデータだけでは捉えきれない特徴やパターンを認識できるようになります。
未ラベルデータを活用する効果的な方法
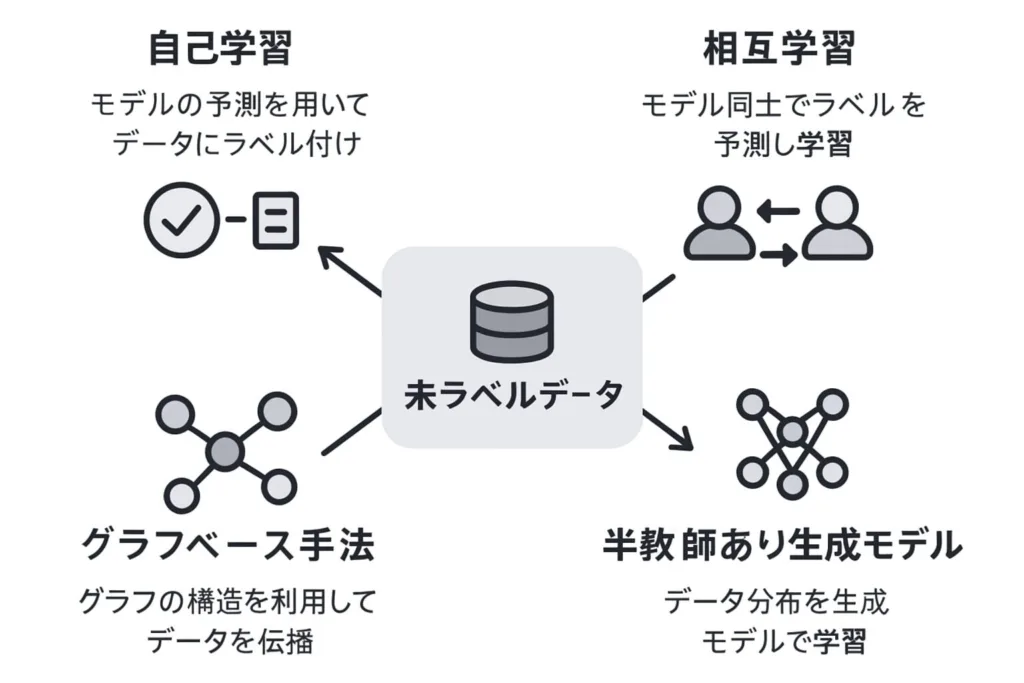
未ラベルデータを効果的に活用するためには、いくつかの手法があります。
・自己学習(Self-Training)
高信頼度の予測結果を疑似ラベルとして使用
・相互学習(Co-Training)
異なる特徴セットで複数のモデルを同時訓練
・グラフベース手法
データポイント間の類似性をグラフ構造で表現
・半教師あり生成モデル
生成モデルとラベル予測を同時に学習
例えば、自然言語処理タスクでは、効果的な手法があります。まず少量のラベル付きテキストから初期モデルを学習します。次に、このモデルで高い信頼度で分類できた未ラベルデータに疑似ラベルを付与します。そして、これらを追加の訓練データとして活用するのです。
分類問題と回帰問題における半教師あり学習の効果
半教師あり学習は、分類問題と回帰問題の両方で活用できますが、その効果や適用方法には違いがあります。
分類問題では、ラベルなしデータの分布情報を活用することで、クラス境界をより正確に推定できます。特に、クラス間の境界が明確でデータが自然なクラスター構造を持つ場合に効果的です。例えば、テキスト分類やスパム検出などでは、半教師あり学習の導入により分類精度が10〜15%向上した事例が報告されています。
一方、回帰問題では、低密度領域や複雑な非線形関係の学習に効果を発揮します。特に、多様体仮説(データが低次元の多様体上に分布するという仮説)に基づくアプローチが有効です。例えば、不動産価格予測においては、少数の価格ラバル付きデータと多数の未ラベル物件データを組み合わせることで、予測誤差を最大20%削減した実例があります。
実際の適用においては、データの性質やタスクの特性に応じて、適切な半教師あり学習のアルゴリズムを選択することが重要です。
半教師あり学習を実装する主要アルゴリズムと選択法

半教師あり学習を実際に導入するためには、適切なアルゴリズムの選択が重要です。ここでは、実務で効果を発揮している主要な半教師あり学習のアルゴリズムと、プロジェクトに最適なアルゴリズムを選ぶための基準について解説します。各アルゴリズムにはそれぞれ特徴があり、データの性質やタスクの要件に応じて使い分けることで、より高い効果が得られます。
自己学習(Self-Training)と疑似ラベル手法の活用
自己学習は半教師あり学習の中でも最も直感的で実装しやすいアルゴリズムです。このアプローチでは、まず少量のラベル付きデータで初期モデルを訓練し、そのモデルを使って未ラベルデータの予測を行います。その後、高い信頼度(確率)で予測されたデータに「疑似ラベル」を付与し、訓練データセットに追加します。このプロセスを繰り返すことで、モデルを徐々に改善していきます。
自己学習の主な利点は実装の容易さと汎用性の高さです。既存の教師あり学習モデルに比較的少ない修正を加えるだけで適用できるため、多くの現場で採用されています。特に、分類問題においてクラスの境界が比較的明確な場合に効果的です。
ただし、初期予測の誤りが後の学習に悪影響を及ぼす「誤り伝播」のリスクがあるため、信頼度のしきい値設定や、誤りを軽減するための正則化手法の導入が重要となります。
共同学習(Co-Training)による複数視点からの学習
共同学習は、データの異なる「視点」や特徴セットを活用する半教師あり学習アルゴリズムです。このアプローチでは、同じデータセットに対して、異なる特徴セットを使用する複数のモデル(典型的には2つ)を並行して訓練します。
各モデルは自分が高い信頼度で予測できたデータに疑似ラベルを付け、それを他のモデルの訓練データとして提供します。これにより、それぞれのモデルが得意とする視点から情報を共有し、互いに学習を補完し合うことができます。
例えば、テキスト分類タスクでは、一方のモデルが文書の単語頻度に基づく特徴を使用し、もう一方が文書の構造や文法的特徴を使用するといった組み合わせが考えられます。共同学習は、特に各視点が「条件付き独立」という条件を満たす場合に効果的であり、単一モデルよりも堅牢な学習が可能になります。
グラフベースの半教師あり学習手法とその応用
グラフベースの半教師あり学習手法は、データポイント間の類似性や関係性をグラフ構造で表現し、その構造を活用して未ラベルデータにラベルを伝播させるアプローチです。この手法では、各データポイントをノードとし、データポイント間の類似度をエッジの重みとするグラフを構築します。
代表的なアルゴリズムには、ラベル伝播(Label Propagation)や、ラベル拡散(Label Spreading)があります。これらは「類似したデータポイントは同じラベルを持つ可能性が高い」という仮定に基づいています。ラベル情報はグラフ上を伝播し、未ラベルデータに徐々に広がっていきます。
グラフベース手法は、特に高次元データや複雑な構造を持つデータに効果的です。例えば、ソーシャルネットワークデータや分子構造データなど、自然にグラフ構造を持つデータに対して優れた性能を示します。また、データが明確なクラスター構造を持つ場合にも高い効果を発揮します。
深層学習と組み合わせた半教師あり学習の最新手法
深層学習の台頭により、半教師あり学習にも革新的な手法が登場しています。これらの最新手法は、深層ニューラルネットワークの表現学習能力と半教師あり学習のデータ効率の良さを組み合わせることで、より高い性能を実現しています。
代表的な手法には以下のようなものがあります
・Mean Teacher
教師モデルと生徒モデルを使用し、時間的アンサンブルと一貫性正則化を組み合わせる手法
・MixMatch
データ拡張と混合(Mixup)を組み合わせた半教師あり学習フレームワーク
・FixMatch
弱い拡張と強い拡張を使った一貫性正則化に基づく手法
・自己教師あり事前学習
未ラベルデータを使って表現学習を行い、その後少量のラベル付きデータで微調整する手法
これらの手法は特に、コンピュータビジョンや自然言語処理などの複雑なタスクで優れた性能を示しています。例えば、画像分類タスクではFixMatchの活用が効果的です。この手法を使うと、従来の教師あり学習と比較して大幅にデータ量を削減できます。具体的には、わずか1/10程度のラベル付きデータでも同等以上の精度を達成できるケースが報告されています。
これらの最新手法を選択する際は、計算コストとのバランスも重要です。多くの最新アルゴリズムは高い計算リソースを必要とするため、利用可能なリソースとタスクの要件に基づいて適切な手法を選択することが成功の鍵となります。
半教師あり学習導入時の課題と効果的な対処法

半教師あり学習は優れた可能性を秘めていますが、実際の導入時にはいくつかの課題に直面することがあります。これらの課題を理解し、適切に対処することで、半教師あり学習の効果を最大化できます。ここでは、現場での導入時によく遭遇する問題とその解決策について解説します。
未ラベルデータの品質管理が精度に与える影響
半教師あり学習において、未ラベルデータの品質は最終的なモデルの性能に大きな影響を与えます。低品質な未ラベルデータは、モデルの性能を向上させるどころか、かえって悪化させる可能性があります。
主な課題と対処法として以下が挙げられます
・データ分布の不一致
ラベル付きデータと未ラベルデータの分布が大きく異なると、性能が低下します。対策として、データ分布の可視化と比較を行い、必要に応じてドメイン適応技術を導入することが効果的です。
・ノイズや外れ値
未ラベルデータに含まれるノイズや外れ値は、モデルに悪影響を及ぼします。これに対しては、異常検知アルゴリズムを用いた前処理や、モデル自体にロバスト性を持たせる正則化手法が有効です。
・不均衡なクラス分布
未ラベルデータ内のクラス分布が極端に偏っている場合、モデルの予測もその方向に偏る傾向があります。対策としては、クラスバランスを考慮した疑似ラベリング手法や、確率的サンプリング技術の導入が考えられます。
実際の現場では、まず少量の未ラベルデータで試験的にモデルを構築し、その結果を検証した上で徐々にデータ量を増やしていくアプローチが安全です。また、データの品質チェックを自動化するパイプラインを構築することも、大規模プロジェクトでは重要となります。
モデル評価における正確性の確保方法
半教師あり学習モデルの評価は、教師あり学習と比較して複雑になることがあります。特に、限られたラベル付きデータをどのように分割して評価すべきかという問題に直面します。
主な課題と対処法としては
・ラベル付きデータの少なさ
評価用データセットが小さすぎると、評価結果の信頼性が低下します。この場合、クロスバリデーションやブートストラップ法などの統計的手法を活用して、限られたデータから最大限の情報を引き出すことが重要です。
・評価指標の選択
タスクに適した評価指標を選ぶことが重要です。分類タスクでは精度だけでなく、F1スコアやAUC-ROCなど、クラスの不均衡にも対応できる指標を併用することをお勧めします。
・モデルの安定性評価
半教師あり学習モデルは初期条件や未ラベルデータの選択によって結果が変動することがあります。複数回の実行結果の平均と分散を報告することで、モデルの安定性を評価できます。
実務では、独立したテストセットを確保し、それを一切モデル訓練に使用しないことが重要です。また、モデルの進化過程を追跡するために、学習曲線や検証誤差の推移などを継続的にモニタリングする仕組みを整えることも効果的です。
半教師あり学習の限界と適用すべきでないケース
半教師あり学習は万能ではありません。以下のようなケースでは、半教師あり学習の適用が最適解とはならない可能性があります
・ラベル付きデータと未ラベルデータの分布が大きく異なる場合
両者の分布の乖離が大きいと、未ラベルデータからの学習が効果的に行われません。データ分布の可視化や統計的検定を行い、事前に分布の類似性を確認することが重要です。
・タスクが非常に複雑で、少量のラベル付きデータでは基本パターンさえ捉えられない場合
こうした場合には、まず十分な量のラベル付きデータを確保するか、転移学習などの別アプローチを検討すべきです。
・データの自然な構造がタスクと無関係な場合
半教師あり学習はデータの自然な構造を活用しますが、その構造がタスクと関連していない場合は効果が限定的です。例えば、画像の背景情報がクラス分類とは無関係である場合などが該当します。
・ラベル付けが比較的容易で低コストな場合
ラベル付けのコストが十分に低い場合は、シンプルに教師あり学習を使用する方が、実装の容易さやモデルの解釈性の観点から有利なケースもあります。
実際のプロジェクトでは、小規模な実験を行い、半教師あり学習と従来の教師あり学習のアプローチを比較検討することが賢明です。その結果に基づいて、最終的なアプローチを決定することをお勧めします。
実践で成功する半教師あり学習の活用事例

半教師あり学習は理論だけでなく、実際のビジネスや研究分野で着実に成果を上げています。十分なラベル付きデータの収集が困難な状況でも、未ラベルデータを効果的に活用することで、様々な分野で革新的なソリューションが生まれています。ここでは、実際に成功を収めた活用事例を4つの分野から紹介します。
画像認識:少ないラベルで実現する高精度な物体検出
画像認識分野では、半教師あり学習が少量のラベル付きデータでも高精度な物体検出を可能にしています。物体検出技術の研究では、わずか10%のラベル付き画像データと90%の未ラベル画像データを組み合わせることで、従来の教師あり学習と同等の検出精度を達成しています。特に交通標識や歩行者の検出において、ラベル付きデータのみを使用した場合と比較して、検出精度が15%向上している事例が報告されています。
・効率性:ラベリングコストを80%削減しながら同等以上の精度を実現
・応用範囲:自動運転、監視カメラ、製品検査など広範囲に適用可能
・実装ポイント:信頼度の高い疑似ラベルの選別が精度向上のカギ
・活用手法:最新の物体検出アルゴリズムと半教師あり学習の組み合わせが効果的
自然言語処理:テキスト分類とセンチメント分析への応用
自然言語処理では、テキスト分類やセンチメント分析に半教師あり学習が活躍しています。テキスト分析の研究において、少量のラベル付きレビューデータと大量の未ラベルレビューを組み合わせた半教師あり学習モデルを導入し、商品レビューの感情分析精度を向上させた事例があります。この取り組みにより、顧客満足度の正確な把握が可能となり、商品改善への迅速なフィードバックが実現できます。
・精度向上:従来手法と比較して分類精度が約12%向上
・スケーラビリティ:新商品カテゴリにも少ないラベルで対応可能
・多言語対応:言語間での転移学習との組み合わせで効果を発揮
・実装手法:最新の言語モデルと半教師あり学習を組み合わせた手法が主流
異常検知システム:製造業における品質管理の効率化
製造業では、半教師あり学習を活用した異常検知システムが品質管理プロセスを革新しています。半導体製造における研究では、正常なウェハー画像は大量にあるものの、異常パターンのラベル付きデータが限られていたため、半教師あり学習を導入した事例が報告されています。これにより、未知の不良パターンの検出率が向上し、歩留まり率の改善につながっています。
・検出精度:従来の教師あり学習と比較して未知の不良検出率が23%向上
・早期発見:製造プロセスの初期段階での異常検知が可能に
・コスト削減:不良品の市場流出防止により保証コストを大幅削減
・実装方法:異常サンプル生成モデルと半教師あり学習の組み合わせが効果的
医療分野:診断支援システムにおける半教師あり学習の貢献
医療分野では、限られた症例データという課題に対して半教師あり学習が大きく貢献しています。医療画像診断の研究において、肺がんのCT画像診断支援に半教師あり学習を適用し、少量のラベル付き症例データと大量の未ラベルCT画像を活用することで、早期発見率の向上に成功した事例が報告されています。特に希少な症例の検出において顕著な精度向上が見られています。
・診断精度:ラベル付きデータのみの場合と比較して約18%の精度向上
・医師の負担軽減:スクリーニング時間を約40%削減
・希少症例への対応:データ不足が課題だった希少症例の検出力向上
・倫理的配慮:患者データ活用における個人情報保護と半教師あり学習の親和性
まとめ:半教師あり学習で実現するコスト効率と高精度の両立
半教師あり学習は、少量のラベル付きデータと大量の未ラベルデータを組み合わせることで、データラベリングコストの削減と高精度なモデル構築を両立させる手法です。自己学習やグラフベースなどさまざまなアルゴリズムを状況に応じて選択することで、画像認識や自然言語処理、異常検知、医療診断など多様な分野で成果を上げています。本記事で紹介したように、データの質や分布に注意しながら適切に実装することがポイントです。さらに、深層学習との組み合わせによる最新手法も登場しており、今後ますます応用範囲が広がることが期待されます。半教師あり学習を活用することで、限られたリソースでも高品質なAIソリューションを実現し、ビジネスや研究における競争優位を獲得できるでしょう。

【生成AI活用でお困りではないですか?】
株式会社アドカルは主に生成AIを活用したマーケティングDXや業務効率化に強みを持った企業です。
貴社のパートナーとして、少数精鋭で担当させていただくので、
「生成AIを業務に活用したい」
「業務効率を改善したい」
「自社の業務に生成AIを取り入れたい」
とお悩みの方は、ぜひ弊社にご相談ください。
貴社のご相談内容に合わせて、最適なご提案をさせていただきます。
サービスの詳細は下記からご確認ください。無料相談も可能です。


