
【初心者向け】構造化データとは?メリットやSEO・LLMOへの効果と実装手順を解説
この記事でわかること
- 構造化データの基本概念とschema.org・JSON-LDの仕組み
- 構造化データがSEOにもたらす5つの具体的なメリット
- 自社サイトに必要なタイプの選び方とJSON-LDの実装手順
- 実装後のテスト・検証方法とGoogleガイドラインの注意点

SEO対策に取り組む中で「構造化データ」という言葉を目にしたことがある方は多いのではないでしょうか。しかし、「自社サイトに本当に必要なのか」「具体的に何をすればよいのか」がわからず、導入に踏み切れていないケースも少なくありません。構造化データは、Googleも公式に実装を推奨しており、リッチリザルトの表示やAI検索への対応など、今後のSEO戦略を支える基盤となる技術です。
本記事では、構造化データの基本から、SEO上のメリット、Googleがサポートするタイプの選び方、JSON-LDによる実装手順、テスト・検証の方法までを一気通貫で解説します。初心者の方でもこの記事を読み終える頃には、自社サイトで構造化データを導入・運用できる状態を目指せるはずです。

【SEO・LLMO対策でお困りではないですか?】
株式会社アドカルはSEO対策・LLMO対策に強みを持った企業です。
貴社のパートナーとして、少数精鋭で担当させていただくので、
「LLMO対策について詳しく知りたい」
「現状のSEO対策で成果が出ていない」
「LLMO対策でAI検索からの集客を強化したい」
とお悩みの方は、ぜひ弊社にご相談ください。
貴社のご相談内容に合わせて、最適なご提案をさせていただきます。
サービスの詳細は下記からご確認ください。無料相談も可能です。
目次
構造化データとは?
構造化データとは、Webページに書かれた情報を検索エンジンが理解しやすい形に整理して伝えるためのデータ形式です。ここでは基本概念から共通規格、そして誤解されやすいポイントまでを整理します。
構造化データと構造化マークアップの違い
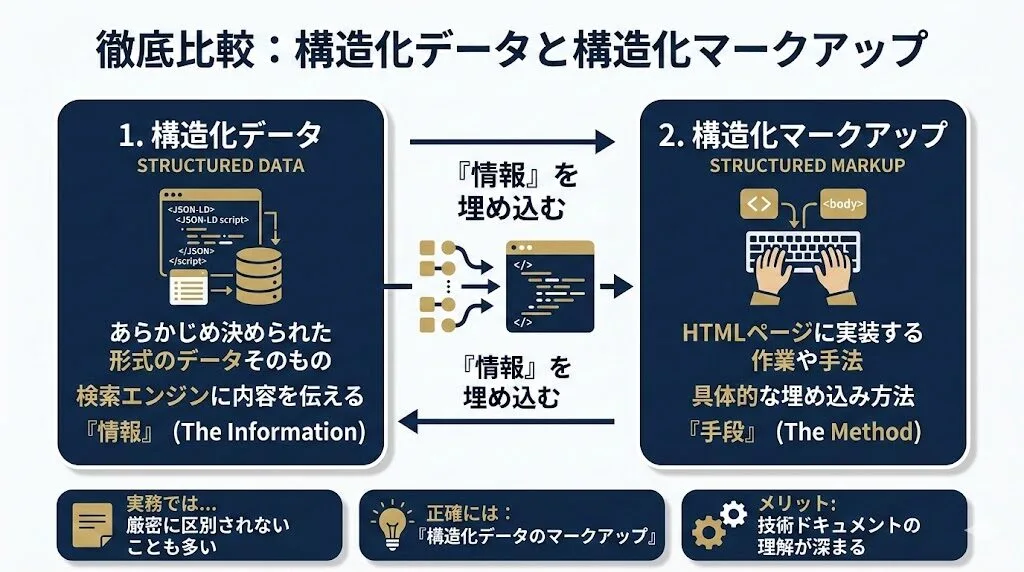
構造化データとは、ページの内容を検索エンジンに伝えるために、あらかじめ決められた形式で記述されたデータそのものを指します。一方、構造化マークアップとは、その構造化データをHTMLページ上に実装する作業や手法のことです。
つまり、構造化データという「情報」を、構造化マークアップという「手段」でページに埋め込む、という関係になっています。実務の現場では両者を厳密に区別せず使われることも多いですが、正確には「構造化データのマークアップ」という表現が適切です。この違いを押さえておくと、技術ドキュメントを読む際にも混乱しにくくなるでしょう。
共通規格「schema.org」とJSON-LDの基本
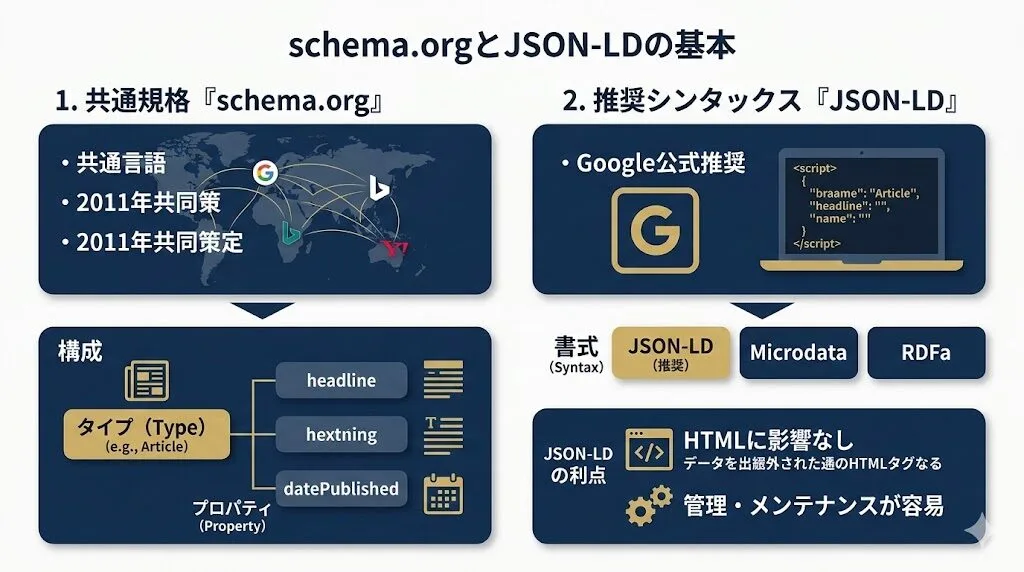
構造化データを記述する際に使われる共通規格が「schema.org(スキーマ・ドット・オルグ)」です。これはGoogle・Microsoft(Bing)・Yahoo!などの主要検索エンジンが2011年に共同で策定した仕様であり、どの検索エンジンでも同じルールで情報を解釈できるようにするための”共通言語”として機能しています。
schema.orgでは、ページの種類に応じた「タイプ」と、そのタイプに紐づく「プロパティ」が定義されています。たとえば記事ページなら「Article」というタイプを使い、「headline(記事タイトル)」「datePublished(公開日)」などのプロパティで情報を整理します。
また、構造化データをHTMLに記述するシンタックス(書式)には「JSON-LD」「Microdata」「RDFa」の3種類がありますが、Googleが公式に推奨しているのはJSON-LD形式です。JSON-LDはHTMLの<script>タグ内にJavaScript表記で記述するため、既存のHTMLコードに影響を与えず、管理・メンテナンスが最も容易な点が大きな利点です。
構造化データでできること/できないことを整理する
構造化データを導入する前に、「できること」と「できないこと」を正しく理解しておくことが重要です。それぞれを整理すると、以下のようになります。
構造化データで「できること」
・ページ内容の意味を検索エンジンに正確に伝える(例:商品名・価格・レビュー評価などのラベル付け)
・リッチリザルト(検索結果上での拡張表示)の対象となる可能性を生む
・AIや外部サービスが情報を機械的に取得・活用しやすくなる
【リッチリザルトの表示例】
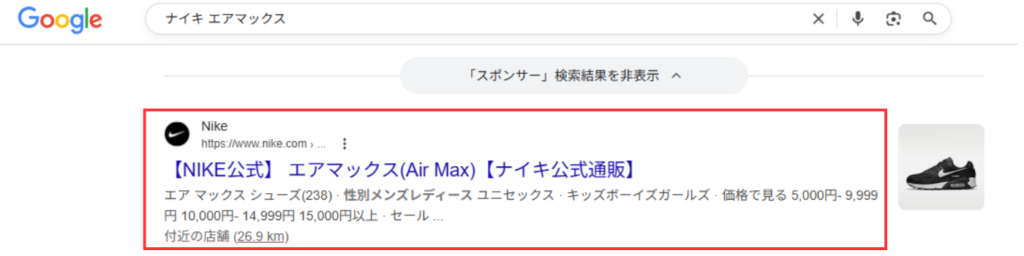
構造化データで「できないこと」
・リッチリザルトの表示を保証する(Googleの公式ガイドラインでも「必ず表示されるとは限らない」と明記されている)
・検索順位を直接的に押し上げる(構造化データはランキング要因ではない)
・コンテンツの質の低さを補う(構造化データはあくまで情報伝達の仕組みであり、本文の品質が前提となる)
リッチリザルトが表示されない理由としては、検索履歴・位置情報・デバイスなど多数の要因でアルゴリズムが最適な表示を判断することが挙げられます。この「できること・できないこと」を正しく認識した上で導入を進めることが、過度な期待や誤った運用を防ぐ鍵となります。
構造化データをSEOに活用する5つのメリット

構造化データの導入は、SEOにおいて複数の面で効果が期待できます。ここでは5つの具体的なメリットを解説します。
検索エンジンがページ内容を正確に理解できる
構造化データを実装する最大のメリットは、検索エンジンがページの内容をより深く、正確に把握できるようになることです。通常、検索エンジンはHTMLの文字列を自然言語処理で解析しますが、文脈の取り違えが起きることがあります。たとえば「Apple」という単語が企業名なのか果物なのかは、前後の文脈からしか判断できません。
ここでOrganizationタイプの構造化データを使い「name: Apple」「url: https://www.apple.com」と明示すれば、検索エンジンはそのページがテクノロジー企業について言及していると確実に理解できます。このように、曖昧さを排除して情報の意味を正確に伝えられることが、構造化データの本質的な価値です。
リッチリザルトの表示でクリック率が向上する
構造化データを正しく実装すると、検索結果にリッチリザルトとして表示される可能性が生まれます。リッチリザルトとは、通常のタイトル・説明文だけでなく、星評価・価格・FAQ・画像などの追加情報が付与された検索結果のことです。
Google公式が紹介している事例では、Rotten Tomatoesが構造化データを10万ページに追加した結果、クリック率が25%向上したと報告されています。また、Nestléではリッチリザルト表示ページのクリック率が非表示ページに比べ82%高かったとされています(出典:Google Search Central「構造化データのマークアップの概要」)。視覚的に目立つ情報が加わることで、ユーザーが「このページに求めている情報がありそうだ」と判断しやすくなり、クリックにつながるのです。
AI検索やLLMOの土台としても期待できる
近年注目されているAI検索やLLMO(Large Language Model Optimization)の領域においても、構造化データは情報整理の土台として期待されています。構造化データは「機械が意味を取りやすい形で情報を明示する」という本質を持っており、AIが回答を生成する際にページ内容を正確に解釈するための手がかりとなり得ます。
とりわけ、Organization・Person・sameAsなどのエンティティ情報を構造化データで整備しておくと、AIが「この情報は信頼できる組織のものだ」と判断しやすくなる可能性があります。ただし注意すべき点として、構造化データだけでAIからの引用や参照が決まるわけではありません。本文コンテンツの品質、一次情報としての価値、サイト全体の権威性など、複合的な要因が影響します。構造化データはあくまで「情報を正しく届ける経路のひとつ」と捉え、コンテンツの質を高める取り組みと組み合わせて活用することが大切です。
間接的に検索順位の向上に貢献する可能性がある
構造化データは直接的なランキング要因ではありませんが、間接的に検索順位の改善に寄与する経路があります。ひとつは、検索エンジンがページ内容を正しく理解することで、適切な検索クエリとマッチングされやすくなる点です。ページの主題や詳細情報が明確に伝わることで、関連性の高いキーワードでの評価機会が広がります。
もうひとつは、リッチリザルト表示によるCTR向上が行動シグナルとして好影響を及ぼす可能性です。クリック率が上がれば、そのページがユーザーにとって有用であるという間接的な評価につながることが考えられます。こうした複合的な効果を通じて、中長期的にサイト全体のパフォーマンスを底上げする施策として位置づけるのが適切でしょう。
サイトの信頼性・専門性のアピールにつながる
構造化データでOrganization(企業情報)やPerson(著者情報)を明示的に記述することは、サイトの信頼性・専門性を検索エンジンに対してアピールする手段にもなります。たとえば、企業の公式サイトでOrganizationタイプにロゴ・所在地・SNSアカウント(sameAs)を設定すれば、Googleのナレッジパネルに情報が反映される可能性があります。
また、記事ページにArticleタイプで著者名・所属組織・公開日を記述すれば、「誰が・どの組織で・いつ発信した情報か」が機械的にも明確になります。これはGoogleが重視するE-E-A-T(経験・専門性・権威性・信頼性)の評価においてもプラスに働く要素です。構造化データを通じてサイトの”身元”を明確にすることが、検索エンジンからの信頼獲得につながっていくのです。
構造化データの主なタイプとGoogleのサポート状況
構造化データにはさまざまなタイプがあり、Googleがサポートする範囲も異なります。ここでは主要タイプの一覧と優先度の考え方、最新の仕様変更、そして自社サイトへの導入判断基準を解説します。
Googleがサポートする構造化データ一覧と優先度の考え方
Googleが検索結果で認識・活用する構造化データのタイプは、Google Search Centralの「検索ギャラリー」で一覧として公開されています。主要なタイプとその用途、優先度を以下の表に整理しました。
| タイプ | 主な用途 | リッチリザルト対応 | 導入優先度 |
|---|---|---|---|
| BreadcrumbList(パンくずリスト) | サイト階層を検索結果に表示する | ○ | 高(全ページ共通でシステム化しやすい) |
| Article / BlogPosting(記事) | 記事のタイトル・著者・公開日を伝える | ○ | 高(CMS連携で自動出力が可能) |
| Product(商品) | 商品名・価格・在庫・レビュー評価を表示する | ○ | 高(ECサイトではCTR向上に直結) |
| LocalBusiness(ローカルビジネス) | 店舗名・住所・営業時間・電話番号を構造化する | ○ | 高(実店舗ビジネスに必須) |
| Organization | 企業名・ロゴ・所在地・SNSアカウントを伝える | △(ナレッジパネルへの情報提供) | 中(トップページに一度設定すれば済む) |
| WebSite | サイト名やサイト内検索機能を設定する | × | 中(トップページに一度設定すれば済む) |
| Event(イベント) | セミナー・展示会等の日時・場所を表示する | ○ | 状況による(イベント系ページがある場合) |
| FAQ(よくある質問) | 質問と回答の一覧を構造化する | △(政府・医療系サイトのみ表示対象) | 状況による(詳細は次項を参照) |
| Recipe(レシピ) | 材料・調理時間・カロリー等を表示する | ○ | 状況による(レシピ系ページがある場合) |
| JobPosting(求人) | 求人情報をGoogleしごと検索に表示する | ○ | 状況による(採用ページがある場合) |
このほかにもVideo(動画)やCourse(講座)など多数のタイプが用意されています。まずは自社サイトの性質に合ったタイプを優先し、導入ハードルの低いものから着手するのが効率的です。
FAQ・HowToリッチリザルトの最新仕様と今後の活用方針
FAQ(FAQPage)とHowToの構造化データは、2019年にGoogleがリッチリザルト対応を開始して以降、多くのサイトで活用されてきました。しかし、2023年8月にGoogleは大幅な仕様変更を発表しています(出典:Google Search Central Blog「HowTo とよくある質問のリッチリザルトにおける変更」2023年8月8日)。
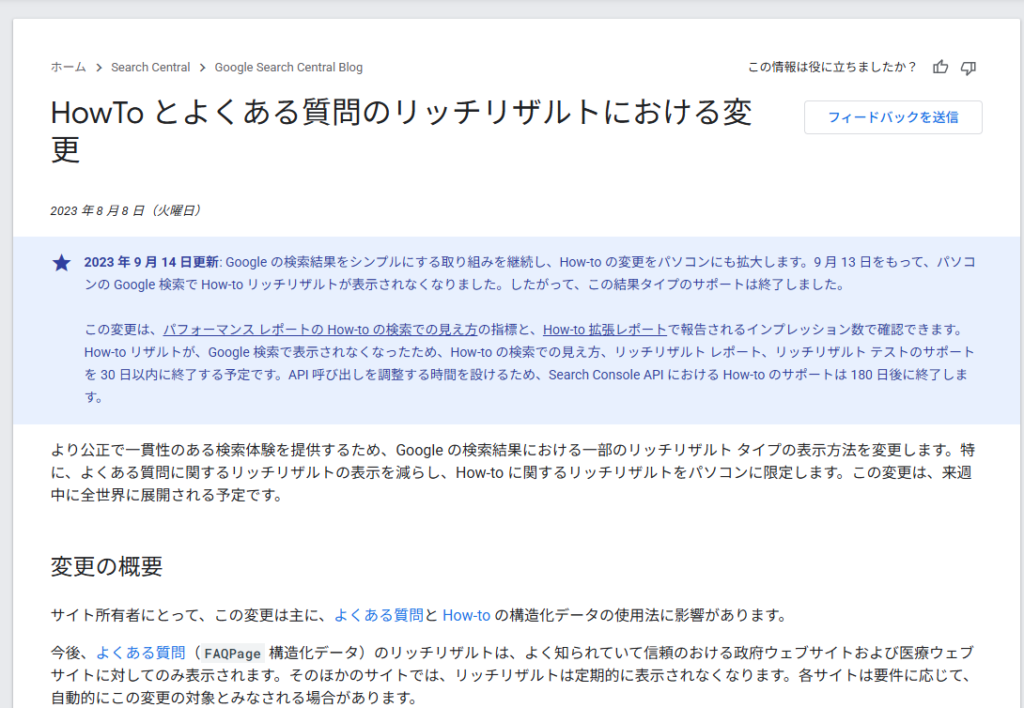
変更内容を正確に整理すると、FAQリッチリザルトの表示対象は「よく知られていて信頼のおける政府ウェブサイトおよび医療ウェブサイト」に限定されました。一般の企業サイトやブログでは、FAQ構造化データを実装してもリッチリザルトとして表示されることは基本的にありません。また、HowToリッチリザルトについては、2023年9月13日をもってPC・モバイルともに完全に廃止され、Google検索でのサポートが終了しています。
ただし重要なのは、これらの構造化データを「削除する必要はない」というGoogleの公式見解です。使用されていない構造化データが検索に悪影響を与えることはなく、検索エンジンへの情報伝達手段としては引き続き有効に機能します。特にAI検索が普及する中で、FAQやHowToの構造化データはAIがページ内容を理解するための手がかりとして活用される可能性があります。リッチリザルト表示は期待できなくなったものの、情報伝達の観点から構造化データ自体は残しておく方針が合理的です。
自社サイトに必要なタイプを見極めるチェックリスト
構造化データのタイプは数十種類ありますが、すべてを導入する必要はありません。自社サイトの種類に応じて、以下の表を参考に必要なタイプを見極めましょう。
| サイトの種類 | 推奨タイプ | 実装難易度 | 理由 |
|---|---|---|---|
| ECサイト | Product、BreadcrumbList、FAQ | 中(商品ごとに個別記述が必要) | 価格・在庫・レビューの表示でCTR向上が見込める |
| コーポレートサイト | Organization、WebSite、BreadcrumbList | 低(トップページ+テンプレート化で完了) | 企業の基本情報を正しく伝え、ナレッジパネル対応にもなる |
| メディア・ブログサイト | Article、BreadcrumbList、Organization | 低(CMS連携で自動出力可能) | 記事の著者・公開日を明示し、E-E-A-T向上に寄与する |
| 店舗・飲食サイト | LocalBusiness、BreadcrumbList | 低(店舗情報を一度設定すれば済む) | ローカル検索・Googleマップでの視認性を高められる |
| 採用サイト | JobPosting、Organization、BreadcrumbList | 中(求人ごとに個別記述が必要) | Googleしごと検索への掲載で応募数の増加が期待できる |
タイプの選定後は、「リッチリザルトの対象かどうか」をGoogle検索ギャラリーで確認し、対象となるタイプを優先的に実装しましょう。さらに「実装・運用コスト」も重要な判断基準です。BreadcrumbListやOrganizationのようにテンプレートやCMSで一括管理できるタイプは導入コストが低い一方、ProductやJobPostingのようにページごとに固有の情報を記述するタイプは運用負荷が高くなります。リソースが限られている場合は、低コストで全サイトに適用できるタイプから始め、段階的に拡大していく進め方が現実的です。
構造化データの書き方と実装手順
構造化データの基本知識を押さえたところで、ここからは実際の書き方と実装方法を解説します。コードの読み方から、すぐに使えるテンプレート、ツール活用、WordPressでの設定まで順に見ていきましょう。
JSON-LD形式の基本構造とコードの読み方
JSON-LD形式の構造化データは、HTMLの<script type=”application/ld+json”>タグ内に記述します。基本的な構造は「キー:値」のペアで構成されており、プログラミング経験がなくても読み方を理解するのは難しくありません。
どのJSON-LDコードにも共通して登場する要素は3つあります。1つ目は「@context」で、ここには使用する規格(通常は”https://schema.org”)を指定します。2つ目は「@type」で、構造化データの種類(ArticleやProductなど)を宣言します。3つ目がタイプごとのプロパティで、「headline」「name」「datePublished」など、伝えたい情報を具体的に記述していきます。
プロパティには「必須(Required)」と「推奨(Recommended)」の区分があります。必須プロパティが欠けているとリッチリザルトの対象にならないため、まずは必須項目を漏れなく記述し、その後に推奨項目を追加していく流れが確実です。各タイプの必須・推奨プロパティはGoogle Search Centralの各タイプ別ガイドで確認できます。
すぐ使える最小テンプレート(Organization・WebSite・BreadcrumbList・Article)
初心者がまず導入すべき4タイプの最小テンプレートを紹介します。いずれもコピーして自社の情報に書き換えるだけで使用可能です。なお、構造化データは<head>タグ内に記述するのが一般的ですが、<body>内でも問題なく動作します。複数タイプを同一ページに設置する場合は、それぞれ別の<script>タグで記述してください。
Organization(企業情報)
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Organization",
"name": "株式会社アドカル",
"url": "https://adcal.co.jp",
"logo": "https://adcal.co.jp/logo.png",
"sameAs": [
"https://twitter.com/example",
"https://www.facebook.com/example"
]
}
</script>WebSite(サイト情報)
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "WebSite",
"name": "サイト名",
"url": "https://example.com",
"potentialAction": {
"@type": "SearchAction",
"target": "https://example.com/search?q={search_term_string}",
"query-input": "required name=search_term_string"
}
}
</script>BreadcrumbList(パンくずリスト)
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "BreadcrumbList",
"itemListElement": [
{"@type": "ListItem", "position": 1, "name": "ホーム", "item": "https://example.com/"},
{"@type": "ListItem", "position": 2, "name": "SEOコラム", "item": "https://example.com/seo/"},
{"@type": "ListItem", "position": 3, "name": "構造化データとは", "item": "https://example.com/seo/structured-data/"}
]
}
</script>Article(記事)
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "記事タイトルをここに入力",
"image": "https://example.com/image.jpg",
"author": {"@type": "Person", "name": "著者名"},
"publisher": {"@type": "Organization", "name": "運営組織名"},
"datePublished": "2025-01-01",
"dateModified": "2025-01-15"
}
</script>これら4タイプを組み合わせれば、コーポレートサイトやメディアサイトの基本的な構造化データ環境を整えることができます。
ツールを使った自動生成の方法
コードを手書きすることに抵抗がある場合は、ツールを活用して構造化データを自動生成する方法があります。Google公式の下記の無料ツールをまずは使ってみましょう。
・Google 構造化データ マークアップ支援ツール:対象ページのURLを入力し、画面上でクリック操作するだけでJSON-LDを生成できる。対応タイプは限定されるが、初心者でも直感的に操作可能
<Google「構造化データ マークアップ支援ツール」でコードを生成する方法>
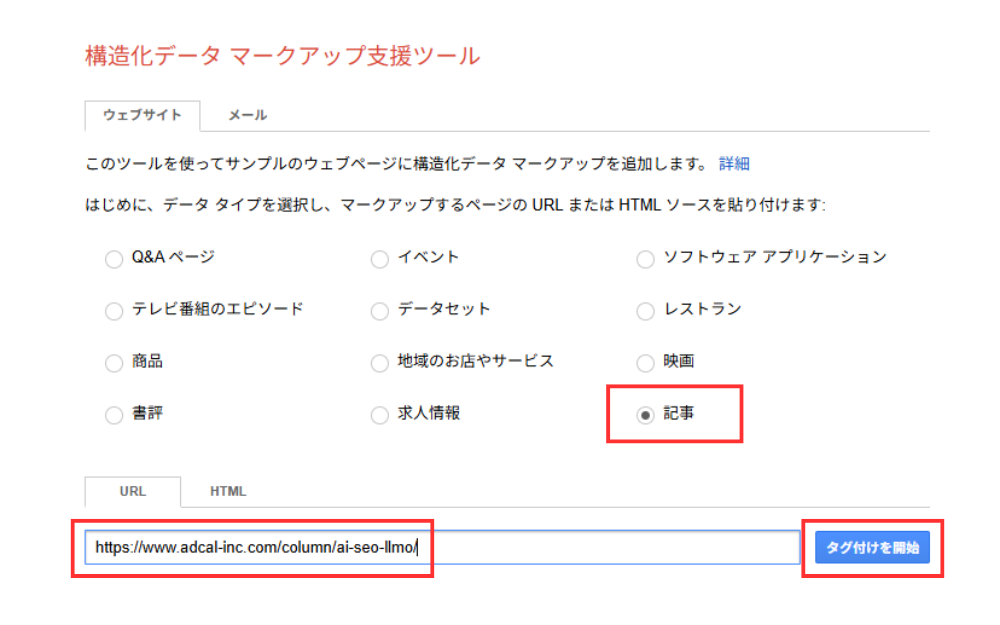
①構造化データのタイプを選ぶ
タイプを選んだら、対象のURLを入力するか、未公開のページであればHTMLを直接貼り付けます。設定が済んだら「タグ付けを開始」をクリックして次のステップに進みましょう。
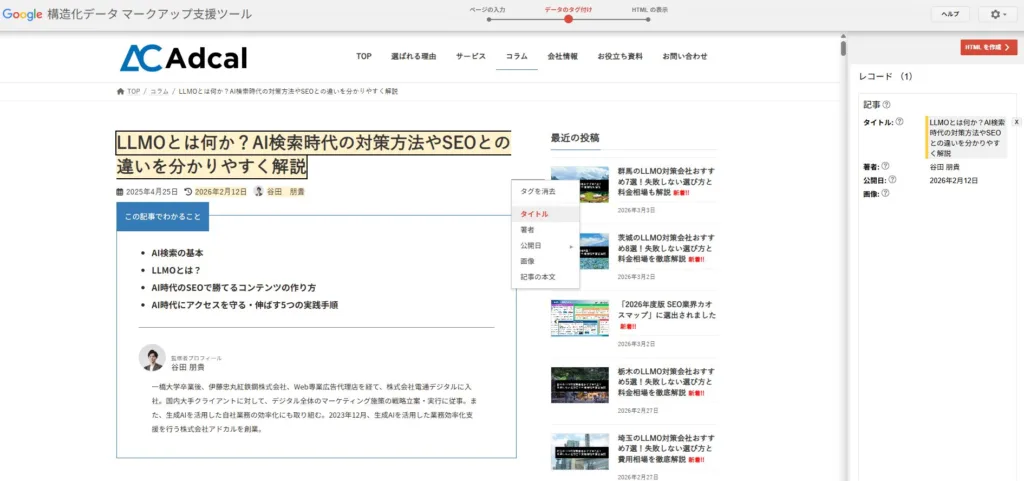
②ページ上の要素のタグ付け
ページが読み込まれると、左側にプレビューが表示されます。右側の「レコード」欄に記載されている「タイトル」「著者名」「公開日」などの推奨プロパティを確認しながら、プレビュー上の該当箇所をマウスでクリックしてタグ付けしていきます。
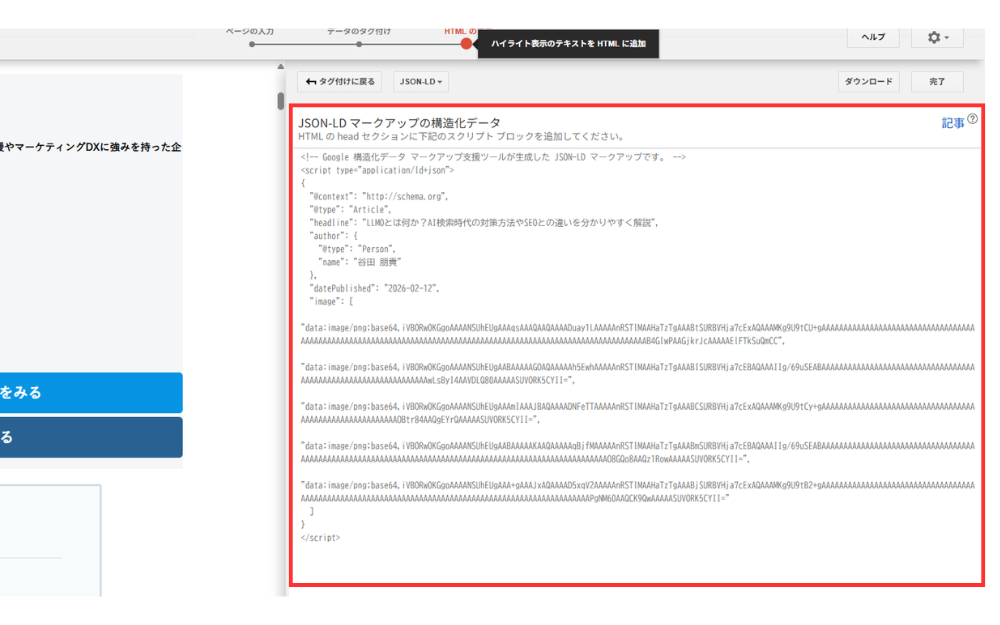
可能な限り、各要素について漏れなく設定しましょう。
③コードの取得
タグ付けが完了すると、設定内容をもとにJSON-LD形式のコードが自動生成されます。生成されたコードはコピーするか、ファイルとしてダウンロードして取得しましょう。
他にも下記の無料ツールが存在します。
・Technical SEO Schema Markup Generator(technicalseo.com):タイプを選択しフォームに情報を入力するとJSON-LDが出力される。Organization・FAQ・LocalBusinessなど幅広いタイプに対応し、細かなプロパティまで設定できる
まずはGoogle公式ツールで基本的な構造化データを作成し、対応していないタイプが必要な場合にTechnical SEOのツールを活用する、という使い分けが効率的です。
WordPressでの実装方法(プラグイン・テーマ機能)
WordPressサイトで構造化データを導入する場合、主に「プラグインを使う方法」と「テーマの標準機能を使う方法」の2つのアプローチがあります。
プラグインで代表的なのは「Yoast SEO」と「All in One SEO」です。どちらもSEO総合プラグインとして構造化データの自動出力機能を備えており、ArticleやBreadcrumbListなどの基本タイプを設定画面から簡単に管理できます。より細かいカスタマイズが必要な場合は、構造化データ専門プラグインの「Schema & Structured Data for WP & AMP」も選択肢になります。
一方、近年のWordPressテーマには構造化データの出力機能が標準搭載されているものも増えています。たとえばSWELL・JIN・AFFINGER・Cocoonといった人気テーマでは、記事ページやパンくずリストの構造化データを自動で生成してくれるため、プラグインを追加する必要がないケースもあります。利用中のテーマがどのタイプの構造化データに対応しているかは、テーマの公式マニュアルで確認しましょう。プラグインとテーマの出力が重複すると不具合の原因になるため、どちらか一方に統一して管理することが大切です。
構造化データのテスト・検証と守るべきガイドライン
構造化データは実装して終わりではなく、テスト・検証とガイドラインの遵守が不可欠です。ここでは検証ツールの使い分けから、Googleのポリシーに基づく注意点、初心者がつまずきやすいミスまでを解説します。
リッチリザルトテストとスキーママークアップ検証ツールの使い分け
構造化データの検証には、目的の異なる2つのツールを使い分けることが重要です。それぞれの違いを以下の表に整理しました。
| ツール名 | 目的 | 確認できること | 使うタイミング |
|---|---|---|---|
| スキーマ マークアップ検証ツール(validator.schema.org) | schema.org規格への準拠を確認する | 構造化データの「文法的な正しさ」(構文エラー・プロパティの記述ミスなど) | コードを書き終えた段階で最初に使う |
| リッチリザルトテスト(search.google.com/test/rich-results) | Googleのリッチリザルトとして有効かを確認する | Googleの検索結果で拡張表示される可能性があるか | 文法チェック後、実装前〜実装直後に使う |
効率的な検証フローとしては、まずスキーマ マークアップ検証ツールで文法エラーがないか確認し、問題がなければリッチリザルトテストでGoogleでの有効性を確認する、という二段階の流れがおすすめです。URLだけでなくコードスニペットを直接入力してテストすることも可能なので、本番環境にデプロイする前の段階でも検証できます。
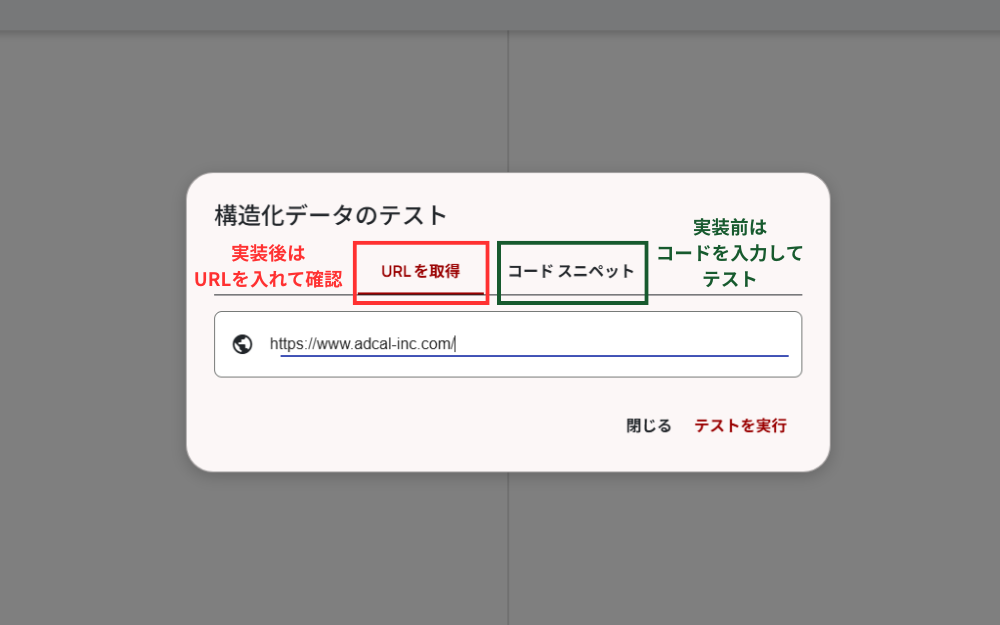
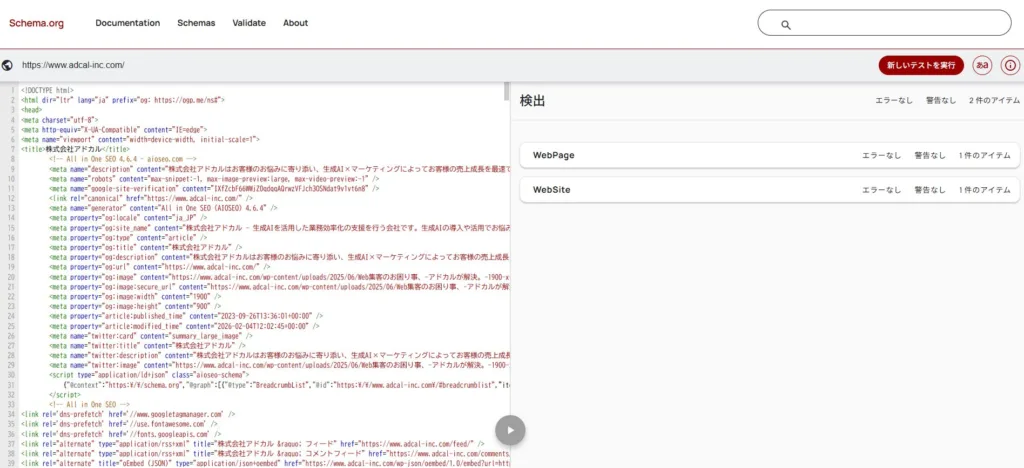
【スキーママークアップ検証ツールでの検証方法】
①実装済みのページであればURLを、まだ実装前であればコードを直接入力し、「テストを実行」をクリックします。実装前の段階では「コードスニペット」タブに生成した構造化データを貼り付けてテストし、実装後は「URLを取得」タブからページのURLを指定して確認するとよいでしょう。
②テスト結果が表示され、問題がなければ「エラーなし」と出ます。コードに誤りがあった場合は「アイテムが検出されませんでした」と表示され、具体的なエラー内容も確認できます。エラーが見つかったらコードを修正し、再度テストを実行しましょう。
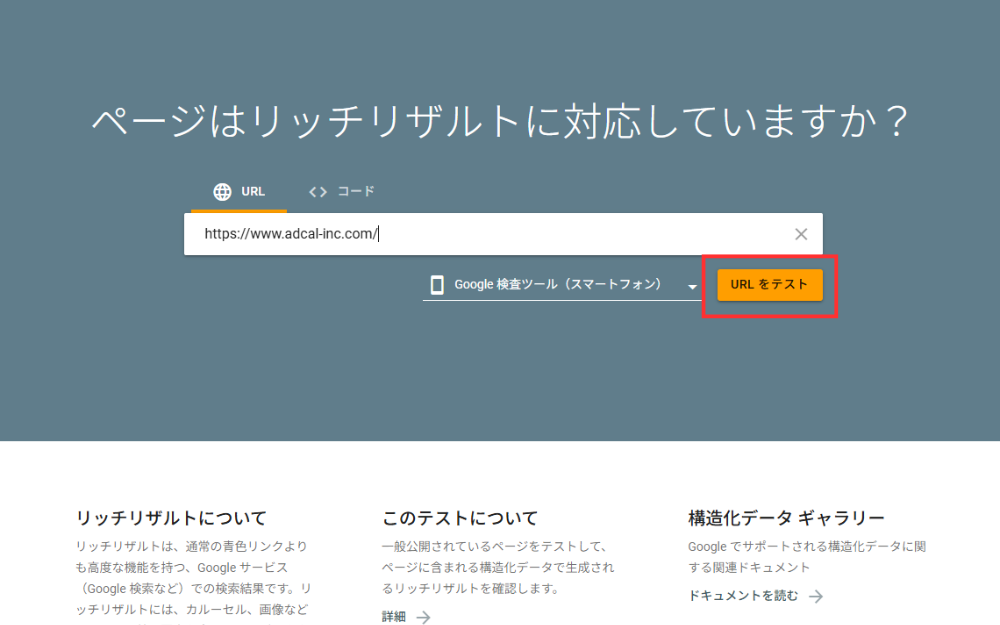
【リッチリザルトテストでの検証方法】
①実装済みのページであればURLを、未実装であればコードを入力し、「テスト」をクリックします。
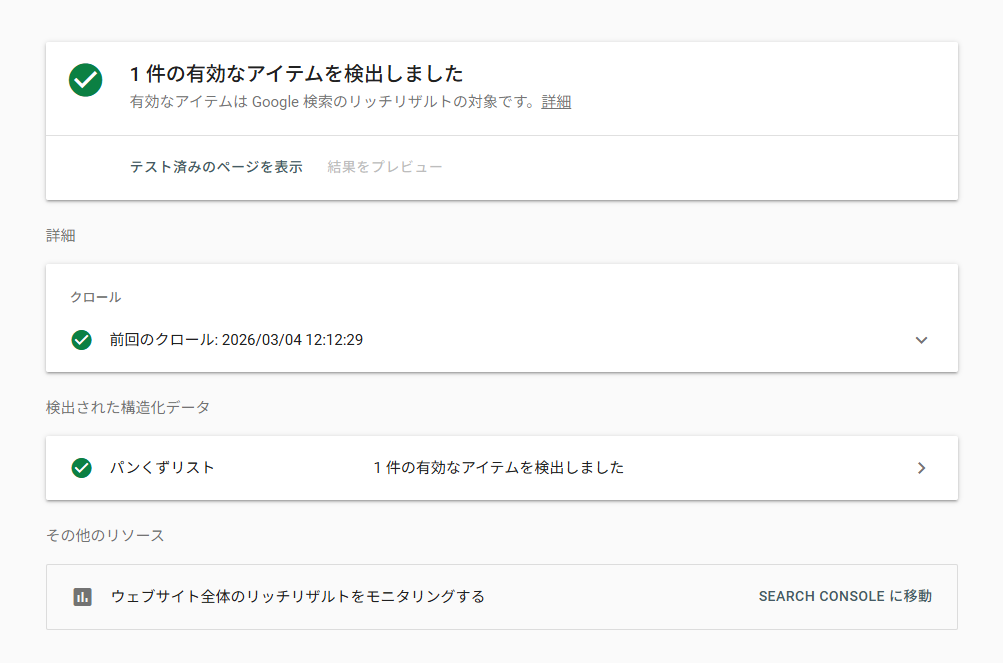
②テスト結果が表示されたら内容を確認しましょう。エラーが検出された場合は、その詳細も確認できるので、必要に応じて修正を行います。
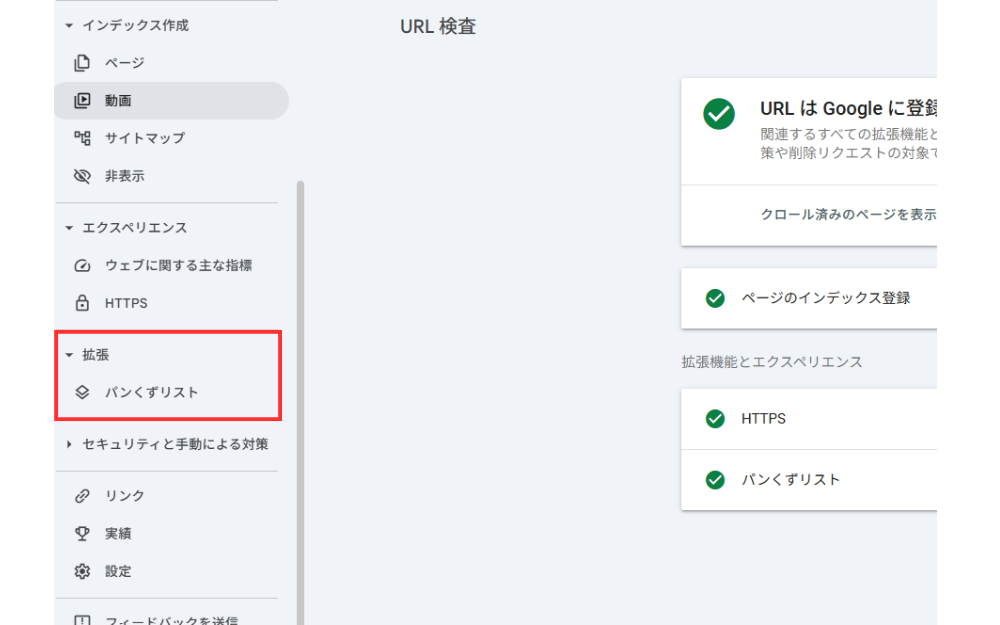
Google Search Consoleでエラーを確認・修正する手順
構造化データを本番環境に実装した後は、Google Search Consoleで継続的にエラーを監視することが重要です。Search Consoleの左メニュー「拡張」セクションには、サイトで検出された構造化データのタイプ別にリッチリザルトレポートが表示されます(構造化データが未実装の場合は「拡張」自体がメニューに表示されません)。
なお、Googleは検索結果ページの簡素化に伴い、2026年1月よりCourse Info・Claim Review・Estimated Salaryなど一部の構造化データタイプについてSearch Consoleでのレポート対応を終了しています(出典:Google Search Central Blog「検索結果ページの簡素化に向けた取り組みの最新情報」2025年11月)。Article・Product・BreadcrumbListなどの主要タイプは引き続きレポート対象ですが、今後もサポート範囲が変更される可能性があるため、Google Search Centralの変更ログを定期的に確認しておきましょう。
エラーが検出された場合は、「アイテムが無効な理由」欄に具体的な問題内容が表示されます。該当ページを特定し、構造化データのコードを修正した後、「修正を検証」ボタンをクリックしてGoogleに再クロールを依頼しましょう。検証には数日かかることがありますが、ステータスが「合格」に変われば修正完了です。
特にテーマやプラグインの更新後、あるいは新しいテンプレートを導入した直後はエラーが発生しやすいタイミングです。定期的にSearch Consoleをチェックする運用習慣をつけておくと、問題の早期発見・対応が可能になります。
Googleの構造化データガイドライン(やってはいけない例)
Googleは構造化データに関するポリシーを公開しており、違反すると手動による対策(ペナルティ)の対象になる場合があります。以下のような行為は明確なガイドライン違反です。
コンテンツとの不一致
・ページに表示されていない情報を構造化データに記述する(例:架空のFAQや存在しないレビュー)
・ページの主題と関係のないタイプでマークアップする(例:木材工芸の手順をレシピとしてラベル付けする)
誤解を招くマークアップ
・実際とは異なる価格・在庫状況・評価を記載する
・ユーザーに見えないコンテンツを構造化データでマークアップする
クロール関連の問題
・構造化データを含むページをrobots.txtやnoindexでブロックしている
・構造化データだけを保持するための空ページを作成する
なお、ガイドライン違反による手動対策が実施された場合、リッチリザルトの表示が停止されますが、Google公式によれば通常の検索順位には影響しないとされています。とはいえ、リッチリザルトの機会損失は大きいため、常にページ内容と構造化データの整合性を保つことが基本原則です。
導入時に失敗しやすいケースと対処法
構造化データの実装では、初心者が特につまずきやすい実務的なミスがいくつかあります。よくある失敗パターンと対処法を以下に整理しました。
・構文エラー(カンマ・カッコ抜け):JSON-LDはカンマやカッコの位置が厳密に決まっており、1つの抜け漏れでコード全体が無効になる。スキーマ マークアップ検証ツールで実装前に必ず文法チェックを行うこと
・必須プロパティの欠落:たとえばArticleタイプで「headline」を記述し忘れるとリッチリザルトの対象外になる。Google Search Centralの各タイプ別ガイドで必須プロパティを確認してから実装に着手すること
・ページ更新時のメンテナンス漏れ:記事内容を更新したのに「dateModified」を変更しない、商品価格が変わったのに構造化データは旧価格のまま、といったケースはコンテンツとの不一致を引き起こす。ページ更新時に構造化データも合わせて修正するワークフローを整備すること
これらのミスはいずれも「事前のチェック」と「運用ルールの整備」で防ぐことができます。特に複数人でサイトを運営している場合は、構造化データの更新手順をマニュアル化しておくと、メンテナンス漏れのリスクを大幅に減らせるでしょう。
まとめ:構造化データを正しく実装してSEOの成果を高めよう
構造化データは、Webページの内容を検索エンジンに正確に伝えるためのデータ形式であり、schema.orgの共通規格に従ってJSON-LD形式で実装するのが現在の標準的な方法です。直接的なランキング要因ではないものの、リッチリザルト表示によるクリック率向上、検索エンジンのページ理解精度の向上、さらにはAI検索時代への備えとして、その重要性は今後ますます高まると考えられます。導入にあたっては、BreadcrumbListやOrganizationなど低コストで全ページに適用できるタイプから着手し、リッチリザルトテストやSearch Consoleでの検証を怠らないことが大切です。構造化データを正しく整備し、検索エンジンとの”共通言語”を構築することで、中長期的なSEO成果の底上げにつなげていきましょう。
【SEO・LLMO対策でお困りではないですか?】
株式会社アドカルはSEO対策・LLMO対策に強みを持った企業です。
貴社のパートナーとして、少数精鋭で担当させていただくので、
「LLMO対策について詳しく知りたい」
「現状のSEO対策で成果が出ていない」
「LLMO対策でAI検索からの集客を強化したい」
とお悩みの方は、ぜひ弊社にご相談ください。
貴社のご相談内容に合わせて、最適なご提案をさせていただきます。
サービスの詳細は下記からご確認ください。無料相談も可能です。

