
Transformer モデルを5ステップで完全理解!わかりやすく解説
この記事でわかること
- Transformer モデルの仕組みと特徴
- Transformerの基本構造
- Transformerの核心・Attention Mechanismについて
- 主要なTransformer派生モデルを比較
- 実践的なTransformer活用事例や最新動向

ChatGPTをはじめとする最新AI技術の根幹を担う「Transformer モデル」。2017年に登場して以来、自然言語処理や画像認識の分野に革命をもたらした技術は、今やAI開発の標準アーキテクチャとなっています。構造や仕組みを理解するのは初心者に容易ではありません。本記事では、Transformer モデルの基本から最新の応用例まで、5つのステップで体系的に解説します。AIエンジニアはもちろん、ChatGPTの仕組みが気になる方や最新技術トレンドを追いたい方にも理解しやすい内容です。最先端AI技術の核心に迫りましょう。
目次
Transformer モデルとは?初心者にもわかる仕組みと特徴
今や ChatGPT をはじめとする、生成 AI の基盤技術となっている Transformer(トランスフォーマー)モデル。この画期的な深層学習の仕組みを知ることで、最新の AI 技術への理解が一気に深まります。まずは基本から見ていきましょう。
「Attention is All You Need」から始まった革新の歴史

Transformer は 2017 年、Google の研究チームが発表した論文「Attention is All You Need」で提案されたニューラルネットワークです。当初は機械翻訳のための技術として開発されましたが、その革新性はすぐに注目を集めました。従来の手法では難しかった「文脈の理解」を可能にした新しいアプローチだったからです。
Transformer の登場から約 1 年後には、GPT(Generative Pre-trained Transformer)や BERT(Bidirectional Encoder Representations from Transformers)といった派生モデルが次々と発表され、自然言語処理の性能を飛躍的に向上させました。さらに注目すべきは、Transformer がテキストだけでなく、Vision Transformer(ViT)のような画像処理や音声処理など、多様なデータ形式に応用できる汎用性の高さです。わずか数年で AI 技術の基盤を一変させた革命的技術と言えるでしょう。
従来の深層学習モデルとTransformerの決定的な違い
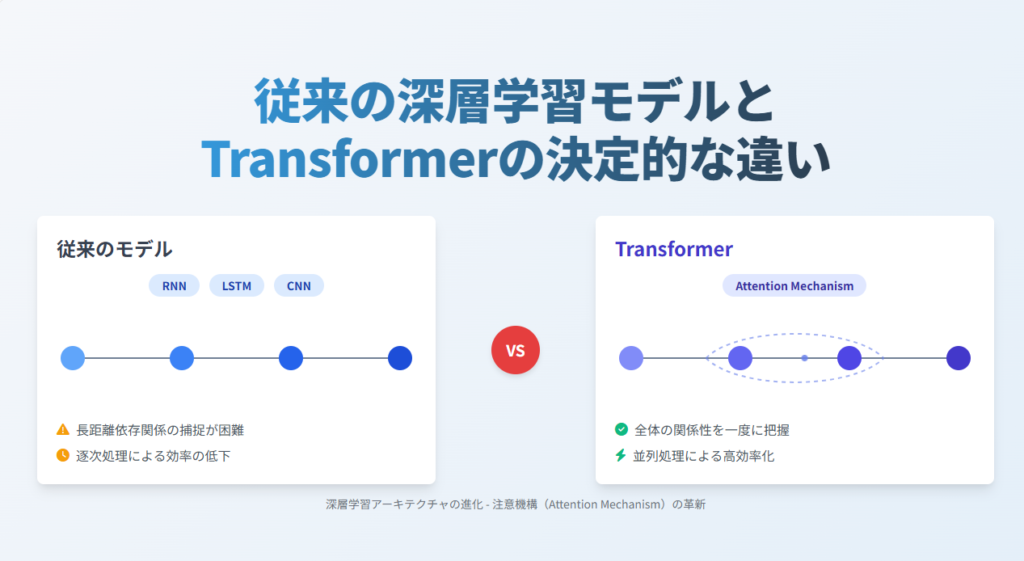
Transformer 以前の深層学習モデルには、主に二つの主流がありました。一つは RNN(再帰型ニューラルネットワーク)とその発展形の LSTM で、もう一つは CNN(畳み込みニューラルネットワーク)です。
RNN は文章のような系列データを処理するのに適していますが、一つ大きな弱点がありました。単語を一つずつ順番に処理する必要があり、長い文章になると「最初の方の単語」と「後ろの方の単語」の関係性を捉えるのが難しく(勾配消失問題)、並列処理もできませんでした 。
CNN は画像処理を得意としますが、局所的な特徴抽出に強い反面、文章全体のような長距離の関係性を捉えるのは不得意でした 。
Transformer はこれらの問題を「注意機構(Attention Mechanism)」という仕組みだけで解決しました 。どの単語とどの単語が関連しているかを直接計算することで、文章全体の関係性を一度に把握できるようになったのです 。さらに並列処理が可能になり、計算効率も大幅に向上しました 。
自然言語処理を変革したTransformerの基本概念
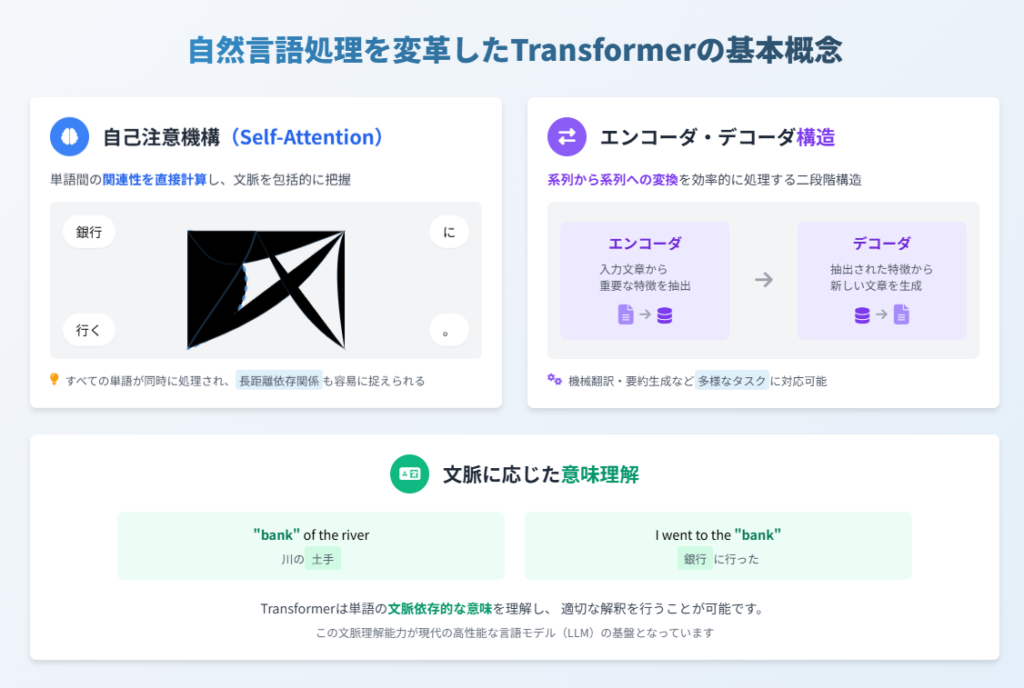
Transformer の最大の特徴は「自己注意機構(Self-Attention)」と呼ばれる仕組みです 。これは文章中のすべての単語同士の関連性を計算し、各単語がどの単語と強く関連しているかを数値化します。例えば「銀行に行く」という文では、「銀行」と「行く」の関連性が高いと判断されます。
もう一つの特徴は「エンコーダ・デコーダ構造」です 。エンコーダは入力された文章から重要な特徴を抽出し、デコーダはその特徴をもとに新しい文章を生成します。この構造により、機械翻訳や要約生成など、ある系列から別の系列への変換タスクを効率的に処理できるようになりました 。
Transformer はこれらの仕組みにより、単語の表層的な意味だけでなく文脈に応じた適切な解釈が可能になりました。例えば英語の「bank」という単語は文脈によって「銀行」や「土手」など異なる意味を持ちますが、Transformer はその違いを理解できるのです 。この文脈理解能力こそが、現代の高性能な言語モデルを支える基盤となっています。
ステップ1: エンコーダとデコーダから理解するTransformerの基本構造
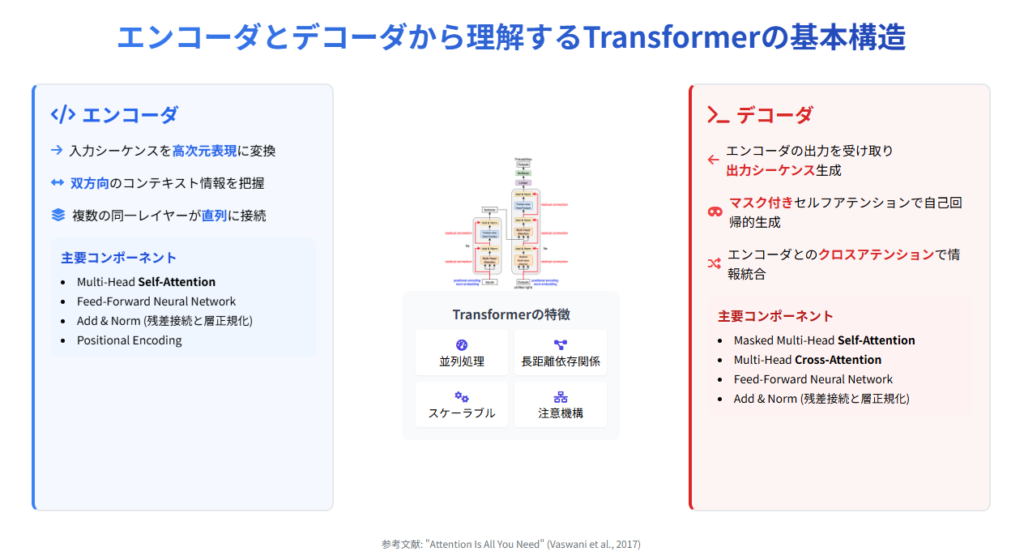
Transformer の仕組みを理解するための最初のステップは、その基本構造を知ることです。Transformer は大きく分けて「エンコーダ」と「デコーダ」という二つの部分から構成されています 。この構造がどのように情報を処理し、高度な言語理解と生成を実現しているのか見ていきましょう。
双方向の情報処理を可能にするエンコーダ・デコーダ構造
Transformer のエンコーダとデコーダは、それぞれ明確に分かれた役割を持っています。エンコーダは「入力系列の重要な特徴を抽出する」役割を担い、デコーダは「エンコーダが抽出した特徴をもとに、系列を生成する」役割を担います 。
例えば機械翻訳では、エンコーダが「こんにちは」という日本語の文を分析して特徴ベクトルに変換し、デコーダがそのベクトルから「Hello」という英語を生成します。この過程で重要なのは、エンコーダが単語を独立に処理するのではなく、文全体の文脈を考慮している点です 。
エンコーダは複数の層から構成され、各層で入力された単語ベクトルをさらに洗練していきます 。各単語の表現は、他のすべての単語との関係性を含む情報に徐々に変化していくのです。このエンコーダによる入力シーケンス全体の双方向的な情報処理により、単語の意味だけでなく文脈の理解が可能になります 。
言語情報を数値化する埋め込み処理の仕組み
Transformer による処理の第一歩は、言語情報を数値化する「埋め込み(embedding)」です。まず、入力文章は「トークン化」と呼ばれる処理で単語や部分語に分割されます 。例えば「機械学習はすごく面白い」という文は、「機械学習」「は」「すごく」「面白い」といったトークンに分けられます。
次に、各トークンは固定長のベクトル(多次元の数値の配列)に変換されます。このベクトルが「埋め込みベクトル」です 。同じような意味を持つ単語は、ベクトル空間でも近い位置に配置されるよう学習されます 。
また、Transformer では単語の順序情報を保持するために「位置エンコーディング」も埋め込みに加えられます 。これにより、同じ単語でも文中の位置によって異なる表現が得られます。これらの埋め込みベクトルがエンコーダへの入力となり、文章の意味を数値的に表現する基盤となるのです。
Transformerアーキテクチャの全体像と動作フロー
Transformer の全体アーキテクチャは、複数のエンコーダ層と複数のデコーダ層が積み重なる形で構成されています。元々の論文では6層ずつ使用されていました 。
一つのエンコーダ層は、主に二つの部分からなります。まず「自己注意機構」で各単語間の関連性を計算し、次に「フィードフォワードネットワーク」で各単語の表現をさらに変換します 。これらの処理の間には「残差接続」と「層正規化」という仕組みが挿入され、学習の安定化を図っています 。
一方、デコーダ層は三つの主要部分から構成されます。「自己注意機構」に加え、「エンコーダ-デコーダ注意機構」でエンコーダの出力情報を取り込み、最後に「フィードフォワードネットワーク」で処理します 。デコーダでは、自己注意機構に「マスキング」という処理が加わり、未来の単語情報を参照できないようになっています 。
最終的に、デコーダの出力は「ソフトマックス層」という部分で確率分布に変換され、次に生成すべき単語が決定されます 。このような複雑な処理フローにより、Transformer は高度な言語理解と生成を実現しているのです。
ステップ2: Transformerの核心・Attention Mechanismを掘り下げる
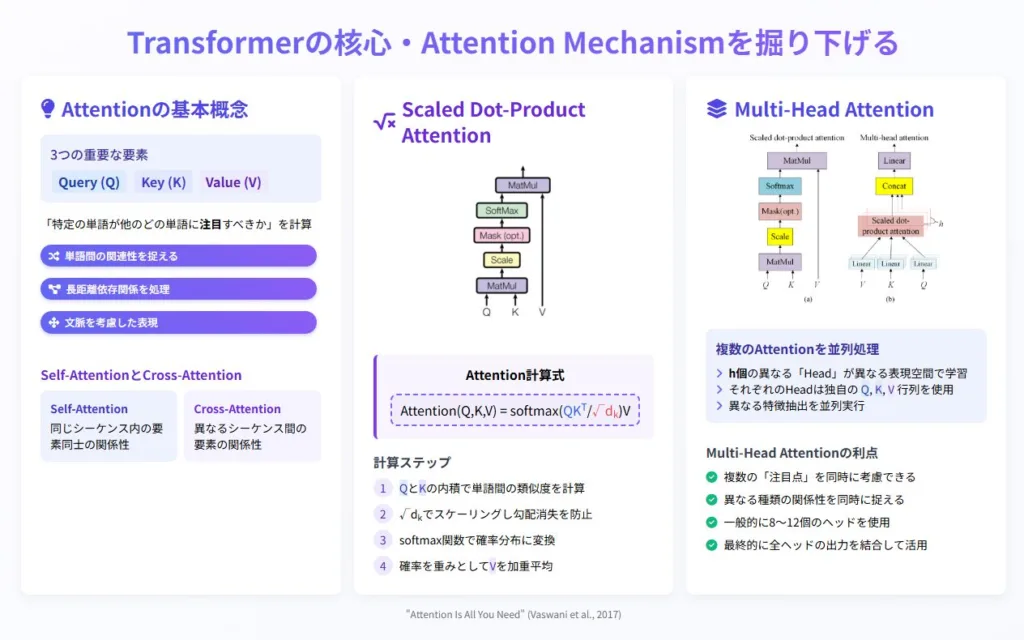
Transformer の革新性を支える中核技術が「Attention Mechanism(注意機構)」です。この仕組みこそが、Transformer が従来のニューラルネットワークを凌駕する性能を発揮できる秘密です。ここでは、その核心部分を段階的に掘り下げていきましょう。
「自己注意機構」が言語理解に革命をもたらした理由
自己注意機構(Self-Attention)は、Transformer の最も重要な要素です 。これは、入力された系列(例えば文章)の中で、各要素(単語)が他のすべての要素とどれだけ関連しているかを直接計算する仕組みです 。
従来の RNN では、「今日は天気がよいので散歩に行きます」という文を処理する場合、「散歩」と「天気」の関係性を捉えるには、間にある単語をすべて順番に処理する必要がありました 。しかし自己注意機構では、「散歩」と「天気」の関連性を直接計算できるのです。
この仕組みにより、文章中の離れた位置にある単語同士の関係性も効率よく捉えられるようになりました 。さらに、すべての単語の関連性を一度に計算できるため、並列処理が可能になり計算効率も大幅に向上しました 。これが自己注意機構が言語理解に革命をもたらした最大の理由です。
クエリ・キー・バリューモデルによる計算プロセス
自己注意機構の計算には「クエリ(Query)」「キー(Key)」「バリュー(Value)」という3つのベクトルが使われます 。この仕組みは、検索エンジンの動作に似ています。
まず、各単語の埋め込みベクトルから、学習可能な線形変換(重み行列)を経て、3種類のベクトル(Q、K、V)が生成されます。例えば「猫が好きです」という文では、「猫」「が」「好き」「です」それぞれに対して3種類のベクトルが作られます。
次に、ある単語のQベクトル(クエリ)と、すべての単語のKベクトル(キー)との内積を計算します。この内積を、キーの次元数 dk の平方根 dk で割ることでスケーリングします。このスケーリングは、内積の値が大きくなりすぎることによる勾配消失を防ぎ、学習を安定させるために重要です 。これにより、その単語と他のすべての単語との関連度(アテンションスコア)が得られます。この関連度はソフトマックス関数により0~1の間の確率値(アテンションウェイト)に変換されます 。
最後に、この確率値を重みとして、すべての単語のVベクトル(バリュー)の加重平均を計算します 。これが、文脈を考慮した新しい単語表現です。例えば「猫」という単語の新しい表現は、「好き」との関連性が強く反映されたものになります。
マルチヘッド注意機構による多角的な情報処理
Transformer はさらに「マルチヘッド注意機構(Multi-Head Attention)」という拡張を導入しています 。これは、自己注意機構を複数(元論文では8個 、一般的には8~16個)並列で実行する仕組みです。
各「ヘッド」は独自のQ、K、V射影行列を持ち、入力埋め込みを異なる低次元空間に射影してから、異なる側面の関係性を学習します 。例えば、あるヘッドは文法的関係(主語と述語の関係など)に注目し、別のヘッドは意味的関係(「犬」と「動物」のような概念的関係)に注目するといった具合です。
マルチヘッド注意機構のメリットは、単語間の関係性を多角的に捉えられる点です 。人間が文章を理解する際も、文法、意味、文脈などさまざまな側面から解釈しています。この多角的な情報処理能力こそが、Transformer が高度な言語理解を実現できる理由の一つです。
各ヘッドの出力は最終的に結合され、さらに線形変換を経て、より豊かな表現へと変換されます 。この複合的な注意機構により、Transformer は複雑な言語の微妙なニュアンスまで捉えることができるのです。
ステップ3: GPTからBERTまで、主要なTransformer派生モデルを比較

Transformer アーキテクチャの登場後、その優れた性能を活かしたさまざまな派生モデルが開発されました。特に注目を集めているのが、GPT、BERT、Vision Transformer の3つです。これらのモデルがどのように Transformer を応用し、異なる強みを持つようになったのかを見ていきましょう。
ChatGPTの基盤となったGPTシリーズの進化と特徴
GPT(Generative Pre-trained Transformer)は、2018年に OpenAI が発表したモデルで、Transformer のデコーダ部分のみを使用しています 。GPT の最大の特徴は、大量のテキストデータで事前学習した後、特定のタスク用にファインチューニングする「転移学習」アプローチです 。
GPT-1(1億1700万パラメータ )から始まり、GPT-2(15億パラメータ )、GPT-3(1750億パラメータ )と発展するにつれ、モデルサイズと生成能力は飛躍的に向上しました。特に GPT-3 は、少数の例示だけでさまざまなタスクを実行できる「few-shot learning」能力を示し、大きな注目を集めました 。
ChatGPT は GPT-3.5/4 をベースに、「人間からの指示に従い、有用で安全な応答を生成する」よう調整されたモデルです 。自己回帰的に一度に一つの単語を生成していくという GPT の基本的な仕組みは、会話のような自然な文章生成に適しています 。このモデルは特に創造的な文章生成、コード作成、対話応答などの分野で優れた性能を発揮します 。
双方向性を活かしたBERTモデルの強み
BERT(Bidirectional Encoder Representations from Transformers)は、2018年に Google が発表したモデルです 。Transformer のエンコーダ部分のみを使用しています 。BERT の最大の特徴は、文章の双方向(前後両方)の文脈を同時に考慮できる点です 。
GPT が「今日は天気が…」と入力された場合、次の単語を左側の文脈だけから予測するのに対し、BERT は単語の前後両方の文脈を参照できます。これは主に2つの事前学習タスクによって実現されています。一つは「マスク言語モデル(Masked Language Model, MLM)」で、文中のランダムな単語を で置き換え、その単語を予測する課題を解かせます 。もう一つは「次文予測(Next Sentence Prediction, NSP)」というタスクで、2つの文が連続しているかどうかを予測することで、文と文の関係性を学習します 。これらの事前学習により、BERTは深い双方向の文脈理解を獲得します。
BERTには主に2つのサイズがあり、BERT-Baseは12層のエンコーダ、隠れ層サイズ768、12個の自己注意ヘッドを持ち、総パラメータ数は約1億1000万です。一方、BERT-Largeは24層のエンコーダ、隠れ層サイズ1024、16個の自己注意ヘッドを持ち、総パラメータ数は約3億4000万です 。
BERT モデルの特徴的な機能として、 トークンを使った文書分類があります。入力テキストの先頭に特殊な トークンを配置し、このトークンの最終的な表現を文書全体の特徴として利用します 。この仕組みにより、BERT は特に質問応答、感情分析、固有表現抽出などのタスクで高い性能を発揮します 。
Vision Transformerで広がる画像処理への応用
Vision Transformer(ViT)は、2020年にGoogleの研究者らが「An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale」という刺激的なタイトルの論文(ICLR 2021で発表 )で発表したモデルです。ViT は Transformer を画像認識タスクに応用した革新的な事例です 。
ViT の基本的なアイデアはシンプルですが斬新です。画像を小さなパッチ(通常 16×16 ピクセル)に分割し、それぞれのパッチを自然言語処理における「単語」のように扱います 。これらのパッチは埋め込み層を通して特徴ベクトルに変換され、位置情報も付与されます。そして、これらのベクトルに Transformer のエンコーダを適用するのです 。
興味深いことに、ViT は従来の畳み込みニューラルネットワーク(CNN)に匹敵する、あるいはそれを上回る性能を達成しました 。特に大規模なデータセットで事前学習した場合、その効果は顕著です。これは、ViTがCNNよりも画像固有の帰納的バイアス(局所性や並進不変性など)が少なく、これらのパターンをデータから学習するため、より多くのデータを必要とするためです 。
ViT の成功により、Swin Transformer(階層的な画像処理が可能)や ViViT(動画認識向け)など、さまざまな発展型モデルも登場しています 。これらのモデルは医療画像診断や自動運転など、さまざまな実用分野での応用が期待されています。
Transformer というアーキテクチャの汎用性の高さは、これらの多様な派生モデルが生まれたことからも明らかです。共通の基礎技術から、テキスト生成や言語理解、画像認識という異なる分野のモデルが発展していることは、AIの発展における Transformer の重要性を示しています。
ステップ4: 実践的なTransformer活用事例とその成果

Transformer の技術的な仕組みを理解したところで、この革新的な技術がどのように実社会で活用され、どのような成果を生み出しているのかを見ていきましょう。理論から実践へと視点を移すことで、Transformer の真の価値がより明確になるはずです。
機械翻訳から要約生成までの自然言語処理応用
Transformer の最初の実用化は機械翻訳の分野でした。Google翻訳や DeepL などの翻訳サービスは、 Transformer モデルを採用することで、以前の統計的手法や RNN ベースのモデルと比較して大幅に翻訳品質を向上させました 。特に文脈を考慮した適切な訳語選択や、長文での一貫性の維持などで優れた性能を発揮しています 。
文書要約の分野でも Transformer は大きな進展をもたらしました。長い文書から重要なポイントを抽出し、元の意図を保ちながらコンパクトにまとめる能力は、ビジネスレポートや学術論文の効率的な把握に役立っています 。例えば、会議の議事録を自動的に要約するツールや、ニュース記事のダイジェストを生成するサービスが実用化されています。
質問応答システムもTransformerの重要な応用分野です。大量の文書から関連情報を抽出し、自然な形で回答を生成できるようになりました 。これは企業の FAQ システムやヘルプデスクの自動化、あるいは学術研究の支援ツールとして活用されています。例えば、法律文書や医学文献のような専門的な内容でも、関連する回答を迅速に見つけ出せるようになりました。
ChatGPTに見るTransformerの潜在能力
ChatGPT の爆発的な普及は、Transformer ベースのモデルが持つ潜在能力を広く世に知らしめました。特に注目すべきは、高度な文脈理解能力と自然な対話の実現です 。ユーザーの質問や指示を理解し、文脈に沿った適切な応答を生成できることで、人間とAIの対話の新たな可能性を開きました。
ChatGPT の活用範囲は非常に広く、プログラミング支援や創作活動、学習サポート、ビジネス文書作成など多岐にわたります 。
例えば、
・プログラマーがコードの問題解決やデバッグのアドバイスを求める
・マーケターが広告コピーのアイデアを得る
・学生が難解な概念の説明を求める
といったさまざまな場面で活用されています。
一方で、ChatGPT の限界も認識されています。「幻覚(ハルシネーション)」と呼ばれる、事実と異なる情報を自信を持って提示してしまう問題や、最新情報への対応、専門性の高い領域での正確性などに課題があります 。それでも、人間の監督のもとで適切に活用することで、多くの業務プロセスの効率化や創造的タスクの支援ツールとして大きな価値を発揮しています。
ハルシネーションへの対策については『生成AIのハルシネーション対策とは?原因や対策、プロンプトを紹介』の記事で詳しく解説しております。
企業におけるTransformer導入の実例とメリット
Transformer 技術の企業導入は、さまざまな業種・部門で進んでいます。カスタマーサポート部門では、問い合わせの自動分類や初期対応の自動化により、サポート品質の向上と対応時間の短縮を実現しています。例えば、メールやチャットでの顧客問い合わせに対して、適切な回答候補を生成したり、担当部署への自動振り分けを行うシステムが導入されています。
マーケティング部門では、コンテンツ生成の効率化や市場動向分析に活用されています。ブログ記事や SNS 投稿の下書き作成、コピーライティングの支援、競合分析など、クリエイティブ作業と分析作業の両面で価値を発揮しています。
製造業では技術文書の作成・管理や、設計プロセスの効率化に役立てられています。例えば、製品マニュアルの多言語展開や、過去の設計ドキュメントからの知識抽出などで活用されています。
導入のメリットとしては、
1.業務効率の向上(手作業の自動化による時間短縮)
2.品質の一貫性(人的ばらつきの低減)
3.創造的業務へのリソースシフト(単純作業からの解放)
4.ナレッジの効率的活用(暗黙知の形式知化)
などが挙げられます。
一方で、導入時の課題として、データセキュリティの確保やモデルのカスタマイズコスト、社内での適切な利用ルール策定などが指摘されています。これらの課題に適切に対処しながら、Transformer 技術の恩恵を最大化する取り組みが各企業で進められています。
ステップ5: Transformerの最新動向と将来性
Transformer モデルは誕生から約8年が経過した現在も進化し続けています。技術的な限界を克服するための研究や、より効率的なモデルの開発、新たな応用分野の開拓など、さまざまな方向に発展しています。ここでは、Transformer の最新動向と将来性について探ってみましょう。
効率化を目指す最新研究トレンド
Transformer モデルの性能向上と実用化に向けて、効率化を目指す研究が活発に行われています。注目すべきトレンドの一つが「Sparse Transformer(疎結合 Transformer)」です。従来の Transformer ではすべての単語ペアについて注意機構の計算(計算量 O(n2))を行っていましたが、これを重要なペアだけに絞ることで計算量を O(nn) に削減するアプローチです。
もう一つの重要なトレンドは「モデル蒸留(Knowledge Distillation)」です。これは大規模なモデル(教師モデル)の知識を、より小さいモデル(生徒モデル)に転移させる手法です。例えば、BERT の小型版である DistilBERT は、元のモデルの 40% のパラメータ数でありながら、性能は 97% を維持しています。
さらに「量子化(Quantization)」や「プルーニング(Pruning)」といった技術も重要です 36。量子化はパラメータの数値精度を下げる(例:32ビット浮動小数点数から8ビット整数へ)ことでメモリ使用量を削減し、推論を高速化します 。プルーニングは重要度の低いパラメータ(個々の重みやアテンションヘッド全体など)を削除することでモデルをスリム化します 36。これらの技術により、モバイルデバイスやエッジデバイスでも、 Transformer ベースのモデルが動作できるようになってきています。
Transformerモデルの大規模化と計算資源の課題
一方で、Transformer モデルの大規模化も急速に進んでいます。GPT-3(1750億パラメータ 5)、PaLM(5400億パラメータ 49)など、パラメータ数は指数関数的に増加しており、これに伴って性能も向上しています。しかし、この大規模化にはさまざまな課題も存在します。
最も重要な課題は計算資源の問題です。大規模モデルの学習には数千台のGPUやTPUを数週間稼働させる必要があり、そのコストは数百万ドルにも達します。この結果、大規模モデルの開発は一部の大企業や研究機関にしか行えないという不平等性が生まれています。
また、環境負荷の問題も深刻です。大規模モデルの学習には膨大な電力が消費され、それに伴う炭素排出量も無視できません。そのため、「パラメータ効率のよい微調整(Parameter-Efficient Fine-Tuning, PEFT)」や「メモリ効率の改善技術」など、限られた資源でより効率的に学習・推論を行う技術の開発が進められています 51。PEFTには、LoRA、QLoRA、Prefix-Tuning、P-tuningなどの手法があります。
大規模化と効率化は一見相反する方向性のように思えますが、両方のアプローチがTransformerの発展には不可欠です。将来的には、タスクや状況に応じて適切な規模のモデルを選択できる柔軟な枠組みが重要になるでしょう。
Transformerの限界を超える次世代モデルの展望
Transformer の素晴らしい性能にも関わらず、現在のモデルには複雑な推論能力や世界モデルの構築など、いくつかの限界があります。これらの限界を克服するための次世代モデルの研究も進んでいます。
一つの方向性は「マルチモーダルモデル」の発展です。文章だけでなく、画像、音声、動画など複数の情報モダリティを統合的に処理できるモデルの開発が進んでいます。例えば OpenAI の GPT-4V や Google の Gemini などは、テキストと画像を同時に理解できる能力を持っています。
もう一つの方向性は「AIエージェント」の発展です。単なる質問応答を超えて、計画を立て、外部ツールを使用し、環境と相互作用しながら目標を達成するシステムの研究が活発化しています。これにより、より複雑なタスクの自動化や問題解決が可能になると期待されています。
また、長い文脈を処理する能力の向上も重要なトレンドです。従来の Transformer モデルは文脈窓の制限がありましたが、これを克服するための「長文脈モデル」の研究が進んでいます。例えば、Anthropic の Claude モデル群(Claude 2.1で20万トークン、Claude 3ファミリーでは初期20万トークンから最大100万トークン超の処理能力を持つものも登場 65)や Google の Gemini モデル群(Gemini 1.5 Proで最大200万トークン、Gemini 1.5 Flashで100万トークン 55)など、数十万から数百万トークンという非常に長い文脈を処理できるモデルが実用化されています。
これらの進化により、Transformer をベースとした AI システムは、より柔軟で汎用的な知的作業の支援ツールへと発展していくでしょう。単純な自然言語処理タスクを超えて、創造的な問題解決や意思決定支援など、より高次の知的活動をサポートする方向へと進化を続けています。
まとめ:Transformer入門から実践活用までの道筋
Transformer モデルは現代の AI 技術の中核を担う革新的アーキテクチャです。本記事では、その基本構造から実践的な活用まで、5つのステップで解説してきました。Transformer の強みは「注意機構」という仕組みで、これにより文脈を考慮した高度な言語理解が可能になりました。エンコーダとデコーダという二つの主要部分が連携することで、翻訳や要約、文章生成などの複雑なタスクを実現しています。GPT や BERT などの派生モデルがさまざまな分野で活躍しており、企業における業務効率化や創造的活動の支援ツールとして大きな可能性を秘めています。技術は日々進化し続けていますが、基本原理を理解することで、生成 AI を自社の課題解決に効果的に活用するための洞察が得られるでしょう。

【生成AI活用でお困りではないですか?】
株式会社アドカルは主に生成AIを活用したマーケティングDXや業務効率化に強みを持った企業です。
貴社のパートナーとして、少数精鋭で担当させていただくので、
「生成AIを業務に活用したい」
「業務効率を改善したい」
「自社の業務に生成AIを取り入れたい」
とお悩みの方は、ぜひ弊社にご相談ください。
貴社のご相談内容に合わせて、最適なご提案をさせていただきます。
サービスの詳細は下記からご確認ください。無料相談も可能です。


