
AIクローラーとは?種類一覧・ブロック方法・LLMO対策まで解説
この記事でわかること
-
AIクローラーの定義と従来クローラーとの違い
-
3つの種類と主要ボット一覧・推奨対応
-
確認方法とrobots.txtでのブロック/許可の判断
-
AIに引用されるためのLLMO/GEO対策


ChatGPTやGeminiに質問すれば、AIが複数のWebサイトを横断して答えを一つにまとめてくれる——そんなAI検索が急速に広がっています。この回答を裏側で支えているのが、Webを巡回して情報を集める「AIクローラー」です。自社サイトにも、GPTBotやClaudeBot、OAI-SearchBotといったボットが日々アクセスしていますが、それがサーバー負荷という脅威なのか、AI検索からの引用・集客という好機なのかは、正体を正しく理解しなければ判断できません。
本記事では、AIクローラーとは何かという定義から、3つの種類、自社に来ているかの確認方法、robots.txtによるブロック・許可の制御、そしてAIに引用されるためのLLMO/GEO対策までを、公式情報をもとに企業のWeb担当者・マーケティング担当者向けに体系的に解説します。先に結論をお伝えすると、AIクローラーは「一括で拒否するもの」ではなく、「役割ごとに許可と拒否を使い分けるもの」です。守り(負荷・権利の保護)と攻め(AI検索からの引用獲得)を両立させる考え方を、定義から実際の設定例まで一気に押さえていきましょう。
目次
AIクローラーとは?仕組みと従来クローラーとの違い
AIクローラーとは、生成AIの学習データ収集・AI検索の回答生成・ユーザーの要求への応答のためにWebページを取得するプログラムの総称です。本章ではまず、その仕組みと従来の検索エンジンクローラーとの違い、そして重要性が高まる背景を整理します。
AIクローラーは生成AIの学習・検索・回答生成のためにWebを取得するプログラム
AIクローラーとは、ChatGPTやClaude、Perplexity、Geminiといった生成AIサービスが、自社の機能を支えるためにWeb上の情報を自動または半自動で取得するプログラムを指します。重要なのは、その目的が一つではない点です。AIクローラーは「基盤モデルを訓練するため」「AI検索の回答を組み立てるため」「ユーザーが指定したページを即座に読むため」という、性質の異なる複数の目的で動いています。「AIの学習や回答生成のために巡回するもの」と一括りにせず、目的の異なる複数の取得活動の集合体として捉えることが、正しい第一歩になります。この理解が、後述する制御の判断ミスを防ぎます。
従来の検索エンジンクローラーとの違いは「順位付け」か「回答生成」かにある
従来の検索エンジンクローラー(Googlebotなど)とAIクローラーの本質的な違いは、取得した情報の使われ方にあります。Googlebotは、ページをインデックス化し検索結果で「順位付けして並べる」ために巡回し、ユーザーはそのリンクをクリックしてサイトを訪問します。一方でAIクローラーは、取得した内容を理解し、AIの回答の中で「再構成・要約・引用する」ために情報を取得します。従来は「リンクを表示してもらう」ことが目的でしたが、AI検索時代には「回答の中で引用される」こと自体が新たな露出の形になっています。
AI検索やAIエージェントの普及でAIクローラーの重要性が高まっている
検索行動が対話型インターフェースへと移行するなか、AIクローラーへの対応はマーケティング上の重要課題になりつつあります。Gartnerの予測では、AIチャットへの移行により従来型の検索ボリュームが2026年までに約25%減少するとされています。とりわけBtoB領域では影響が大きく、商談前の段階でAIが提示する候補に入っているかどうかが受注を左右するという指摘もあります。AI検索の回答に引用される情報源になれるかどうかが、検索順位とは別の流入チャネルを決めるようになっているのです。なお、引用される対策についてはLLMOとは何か、SEOとの違いもあわせて参照すると理解が深まります。
AIクローラーの主な3つの種類|学習用・検索用・ユーザー主導
AIクローラーは「学習用」「検索用」「ユーザー主導フェッチャー」の3つに分類でき、それぞれ巡回量・送客への寄与・推奨対応が異なります。本章では、この分類と主要なユーザーエージェントの一覧を整理します。
学習用クローラーは基盤モデルの訓練データ収集に使われる
学習用クローラーは、生成AIの基盤モデルを訓練するためのデータを収集するボットです。代表例はOpenAIのGPTBot、AnthropicのClaudeBot、Common CrawlのCCBot、ByteDanceのBytespiderなどです。これらは網羅的に大量のページを巡回するためサーバー負荷が高い一方で、取得した内容が直接ユーザーをサイトへ送客するわけではありません。Cloudflareの計測では、AIボットの活動の大部分が学習用のクローリングで占められていると報告されており、負荷の割に見返りが乏しいのが特徴です。自社コンテンツを訓練データに使われたくない場合、最初に制御を検討する対象がこの学習用クローラーです。
検索用クローラーは回答生成や引用・検索結果表示に使われる
検索用クローラーは、AI検索の回答生成・引用表示・検索結果への掲載のために情報を取得するボットです。OpenAIのOAI-SearchBot、AnthropicのClaude-SearchBot、PerplexityのPerplexityBotに加え、Google検索・AI Overviewsの前提となるGooglebot、Microsoft Bing/Copilotの検索基盤となるbingbotなどが該当します。これらをブロックするとAI検索の回答源から外れ、引用・露出の機会を失います。学習用とは目的が真逆であり、集客を狙うなら原則として許可しておきたいカテゴリーです。たとえばOAI-SearchBotをブロックすると、ChatGPTの検索回答に自社が表示されなくなります。
ユーザー主導フェッチャーはユーザー操作に応じてURLを取得する
ユーザー主導フェッチャーは、ユーザーがチャットでURLを入力したり「このページを読んで」と指示したりした際に、その都度オンデマンドで取得するボットです。ChatGPT-User、Claude-User、Perplexity-Userが該当し、自動で巡回するわけではなく、モデルの学習には使われません。ここで実務上重要な違いがあります。OpenAIはChatGPT-Userについて、PerplexityはPerplexity-Userについて「robots.txtの指示が適用されない場合がある」と説明している一方、Anthropicは3つのボット(Claude-User含む)すべてがrobots.txtを尊重すると明記しています。ベンダーごとに挙動が異なる点に注意が必要です。
主要なAIクローラーとユーザーエージェント・推奨対応の一覧
以下は、各社の公式情報(OpenAI・Anthropic・Perplexity・Google)をもとにした主要AIクローラーの一覧です。User-Agent(クローラーが名乗る識別名)と分類、推奨対応を整理しました。推奨対応はあくまで一般的な目安であり、自社の方針によって変わります。
表1:主要AIクローラーと推奨対応の一覧(スマートフォンでは横にスクロールできます)
| 開発元 | User-Agent / トークン | 分類 | 主な用途 | 推奨対応の目安 |
|---|---|---|---|---|
| OpenAI | OAI-SearchBot | 検索用 | ChatGPT Searchでの表示・引用 | 原則許可 |
| OpenAI | GPTBot | 学習用 | 基盤モデルの学習データ収集 | 方針により拒否可 |
| OpenAI | ChatGPT-User | ユーザー主導 | ユーザー操作・GPTでの取得 | 別枠で判断(robots.txt非適用の場合あり) |
| Anthropic | Claude-SearchBot | 検索用 | Claudeの検索結果・引用 | 引用を狙うなら許可 |
| Anthropic | ClaudeBot | 学習用 | Claudeモデルの学習データ収集 | 方針により拒否可 |
| Anthropic | Claude-User | ユーザー主導 | ユーザー要求に応じた取得(robots.txt尊重) | 別枠で判断 |
| Perplexity | PerplexityBot | 検索用 | Perplexity検索での表示・リンク | 原則許可 |
| Perplexity | Perplexity-User | ユーザー主導 | ユーザー質問時の取得(通常robots.txt無視) | 別枠で判断 |
| Googlebot | 検索・AI検索基盤 | Google検索、AI Overviews/AI Modeの前提 | 基本許可 | |
| Google-Extended | AI利用制御トークン | Gemini/Vertex AIの学習・グラウンディング制御 | 方針により拒否可 | |
| Common Crawl | CCBot | 学習データ供給元 | オープンWebデータセット構築 | 方針により拒否可 |
| ByteDance | Bytespider | 学習用とされる | AI関連データ収集 | 負荷・方針により拒否可 |
※Google-ExtendedはHTTPで独立して動くクローラーではなく、Googlebotが取得した内容をGeminiの学習・グラウンディングに使うかを制御するrobots.txt用トークンです(Google検索の順位には影響しません)。旧称のanthropic-ai/Claude-Webは廃止され、上記のClaude系3ボットに置き換え済みです。
AIクローラーが自社サイトに来ているか確認する方法
AIクローラーが自社に来ているかは、サーバーログのUser-Agent確認から始め、IP照合で本物かを検証し、頻度や転送量で負荷を把握する、という3段階で確認できます。本章では、制御を決める前に行うべき現状把握の手順を解説します。
サーバーログのUser-AgentでGPTBotやClaudeBotを確認する
最も基本的な確認方法は、Webサーバーのアクセスログを開き、User-Agent欄に特定の文字列が含まれていないかを検索することです。具体的には、GPTBot・OAI-SearchBot・ClaudeBot・Claude-SearchBot・PerplexityBotといった名称でログを絞り込みます。どのボットが、どのページに、どれくらいの頻度で訪れているかを把握できれば、どのAIサービスが自社を情報源として見ているかが見えてきます。CDNやレンタルサーバーの管理画面でアクセスログをダウンロードできる場合が多いため、まずはここから着手するとよいでしょう。
偽装対策としてIPアドレスや逆引きDNSで本物か見分ける
User-Agentは誰でも名乗れるため、文字列だけで本物と判断するのは危険です。実際に「GPTBot」と名乗りながら無関係な業者がスクレイピングしている例も報告されています。本物かどうかは、各社が公開しているIPレンジや逆引きDNSとの照合で検証します。OpenAIはgptbot.json等でIPレンジを公開しており、Googleも逆引きDNSと公開IPレンジでの確認を推奨する考え方を示しています。なお、Anthropicは公開IPレンジを提供しておらず、IPでのブロックではなくrobots.txtでの制御を推奨しています。User-AgentとIPの両方を突き合わせるのが、最も確実な検証方法です。
クロール頻度やステータスコード・転送量で負荷を把握する
来訪の有無が分かったら、次は負荷の度合いを定量的に把握します。確認すべき指標は以下のとおりです。
負荷把握でチェックすべき指標
- クロール頻度:短時間に大量アクセスが集中していないか
- ステータスコード:403や429の多発はWAF・レート制限による誤遮断のサイン
- 転送量:特定ボットが帯域を圧迫していないか
とくに429(Too Many Requests)の多発には注意が必要です。許可しているつもりでも、WAFやレート制限が検索用ボットを誤って弾き、結果としてChatGPTに引用されないという典型的な失敗につながります。「許可設定をしたのに引用されない」場合は、まずこのステータスコードを疑うとよいでしょう。
AIクローラーがWebサイトに与えるメリットとデメリット

AIクローラーには「AI検索からの引用・送客」というメリットと、「サーバー負荷や無断学習」というデメリットの両面があります。本章では両者を整理し、すべてを拒否するのではなく役割ごとに使い分ける考え方を示します。
メリットはAI検索からの引用や認知・送客の機会を得られること
最大のメリットは、検索順位に依存しない新しい流入チャネルを得られることです。検索用クローラーを許可しておくと、ChatGPT Search・Perplexity・Google AI Overviewsなどの回答に自社コンテンツが引用され、そこから認知や送客が生まれる可能性があります。AI検索では、ユーザーが比較・選定・調査など具体的な文脈で質問することも多く、従来のキーワード検索とは異なる接点を作れる可能性があります。従来のSEOで上位を取れていないサイトでも、AIに引用されやすい状態を整えることで、新たな露出の機会につながる場合があります。
デメリットはサーバー負荷や無断学習・コンテンツ利用のリスク
一方のデメリットは、主に学習用クローラーに由来します。学習用ボットは網羅的に巡回するため、サーバー負荷とインフラコストが増大しがちです。Cloudflareの計測では、学習用クローラーは多数のページを巡回しても送客にはほとんどつながらない、という負荷と見返りの非対称性が指摘されています。さらに、独自に作成したコンテンツや調査データが、許可なく訓練データとして取り込まれ、競合優位性が損なわれるリスクもあります。負荷とコンテンツ保護の両面で、無条件に開放することは避けたいところです。
すべてを拒否せず役割ごとに許可と拒否を分けるのが基本
ここで誤りやすいのが「不安だから全部ブロックする」という対応です。AIクローラーを一括で拒否すると、負荷は減らせても、成長著しいAI検索経由の送客チャネルから自社が完全に消えてしまいます。現実的な解は「学習用は制限しつつ検索用は許可する」という非対称制御で、守り(負荷・権利の保護)と攻め(引用・流入の獲得)を両立させることです。具体的な判断軸は次章で詳しく扱います。
AIクローラーはブロックすべきか許可すべきかのサイト別判断基準
ブロックか許可かの答えは、サイトの種類によって変わります。本章では「BtoB・サービスサイト」「メディア・独自調査サイト」「会員制・機密ページ」という3つの類型ごとに、判断の軸を示します。
BtoB・サービスサイトは検索用クローラーを許可するメリットが大きい
BtoB企業やサービス紹介を主とするサイトでは、検索用クローラーを許可するメリットが大きくなります。BtoBの購買検討ではAI検索によるベンダー調査が一般化しており、商談前にAIの回答へ自社が引用されることが、そのままリード獲得につながるためです。コンテンツ自体を有料の資産として販売しているわけではない多くのサービスサイトにとって、検索用ボットを閉じる理由は乏しいといえます。AI検索経由の新規接点を積極的に取りにいく方針が合理的です。
メディア・独自調査サイトは学習用クローラーの扱いを慎重に判断する
記事・独自調査・データそのものが収益源となるメディアでは、判断がより慎重になります。コンテンツが資産である以上、学習用クローラーに無償で取り込まれることは、長期的な競合優位性や収益機会の喪失につながりかねないためです。実際、大手メディアの多くが学習用途の利用に対して訴訟やライセンス契約で対応を進めています。一方で検索用ボットまで閉じるとAI検索からの流入を失うため、「学習用は拒否、検索用は許可」を軸に、権利方針・収益方針に応じて判断します。
会員制や機密ページはrobots.txtではなく認証やWAFで守る
会員制ページや機密情報を含むページは、robots.txtで守ろうとしてはいけません。robots.txtはあくまで「クロールしないでください」という紳士協定であり、アクセスを物理的に止める仕組みでも、検索結果からページを隠す仕組みでもないためです。従わないクローラーや偽装も存在します。本当に守るべき非公開ページは、ログイン認証・アクセス制御・WAF(Web Application Firewall)といった、強制力のある手段で保護するのが正解です。robots.txtと認証・WAFは役割がまったく異なる、と理解しておきましょう。
AIクローラーをブロック・制御する具体的な方法
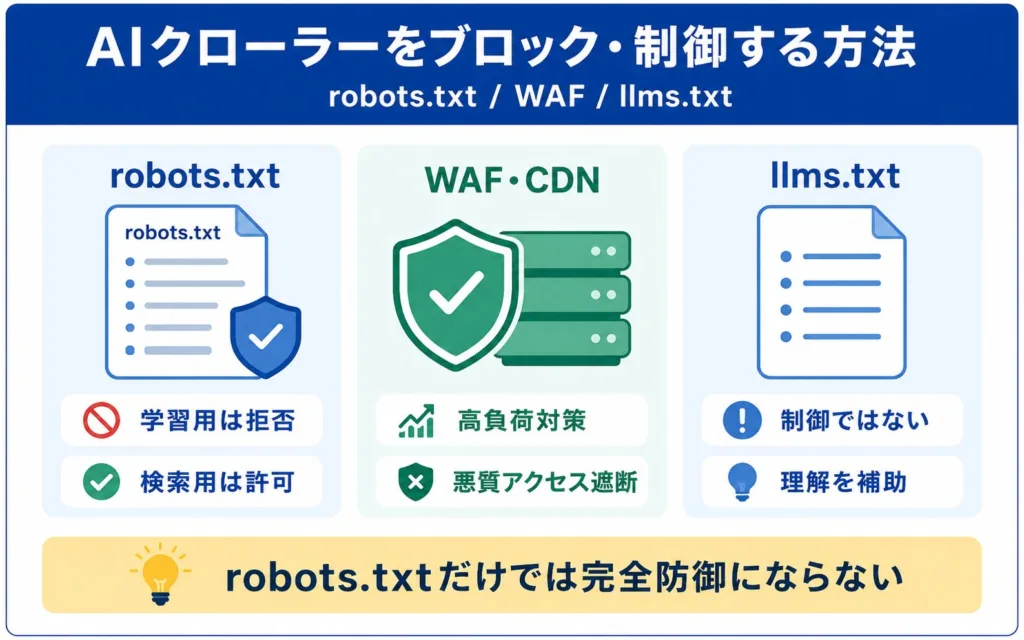
AIクローラーの制御は、robots.txtでのUser-Agentごとの設定を基本とし、必要に応じてWAF・IP制限を併用します。本章では具体的な設定例と、robots.txtの限界、llms.txtの正しい位置づけまでを解説します。
robots.txtでUser-Agentごとに許可と拒否を設定する
最も基本的な制御手段は、サイトのルートに設置するrobots.txtで、User-AgentごとにAllow(許可)とDisallow(拒否)を書き分けることです。考え方はシンプルで、「学習用はDisallow、検索用はAllow」が基本形になります。以下は、AI検索の引用は獲得しつつ学習利用は拒否したいBtoB企業向けのテンプレートの一例です。
# ChatGPT Searchへの表示は許可
User-agent: OAI-SearchBot
Allow: /
# OpenAIの学習利用は拒否
User-agent: GPTBot
Disallow: /
# Perplexity検索への表示は許可
User-agent: PerplexityBot
Allow: /
# Claude検索への表示は許可
User-agent: Claude-SearchBot
Allow: /
# Claudeの学習利用は拒否
User-agent: ClaudeBot
Disallow: /
# Common Crawlは方針により拒否
User-agent: CCBot
Disallow: /
Sitemap: https://example.com/sitemap.xmlこのテンプレートを使う前に必ず確認してください
- これはBtoB・サービスサイト向けの一例である。メディア・EC・会員制サイト・独自データを保有するサイトでは、権利方針や収益方針により判断が異なる
- WAFやCDNのAIボット一括ブロック設定が、OAI-SearchBotやPerplexityBotなど検索用クローラーまで弾いていないか、設定後にサーバーログで必ず確認する
- robots.txtは強制的なセキュリティ対策ではない。非公開情報の保護にはログイン認証やアクセス制御(WAF等)を使う
CDNやWAF・IP制限で高負荷や悪質なクローラーを遮断する
robots.txtを無視するボットや、高負荷を引き起こす悪質なアクセスに対しては、CDN・WAF・IP制限といった強制力のある手段で遮断します。CloudflareなどのCDNには「AIスクレイパー一括ブロック」のトグルが用意されている場合があります。ただし注意点として、このトグルがrobots.txtの個別Allowルールを上書きし、許可したはずの検索用ボットまで403で弾いてしまうことがあります。設定後はエッジ側のダッシュボードで挙動を必ず確認してください。なお、IPアドレスでのブロックは、クラウドの共有IPや、robots.txt自体の読み取りを妨げる問題から不安定になりやすく、Anthropicも非推奨としています。
robots.txtだけでは完全な防御にならない点に注意する
制御方法を実装するうえで、robots.txtの限界を正しく理解しておくことが欠かせません。前述のとおりrobots.txtは強制力のない紳士協定です。第三者の調査では、AIによるスクレイピングの相当割合がrobots.txtの設定を無視して実行されていたと報告されており、ユーザー主導フェッチャーの不遵守率はとくに高い水準にあります。加えて、他サイトからの被リンク経由でURLが拾われることもあります。robots.txtは「意思表示」として有効ですが、それだけで完全に防御できるわけではない、という前提で設計する必要があります。
llms.txtは制御ではなくAIに読ませる情報を整理する補助ファイル
近年話題のllms.txtは、アクセスを「制御」するファイルではなく、AIにサイトを理解させるための「補助」ファイルです。これはJeremy Howard氏が2024年に提唱したMarkdown形式の提案仕様で、サイトの重要コンテンツへのリンクや要約を一箇所にまとめ、LLMが効率的に内容を把握できるようにするものです。ただしW3CやIETFが定めた正式な標準ではなく、強制力もありません。2026年時点で主要AI企業が本番システムでの参照を公式に約束しているわけでもない点には留意が必要です。robots.txtが「アクセス可否の指示」であるのに対し、llms.txtは「AIに読んでほしい情報の整理」と位置づけて使い分けましょう。作成手順はllms.txtの作成方法と設置手順で詳しく解説しています。
AIクローラーに引用されるためのGEO・LLMO対策
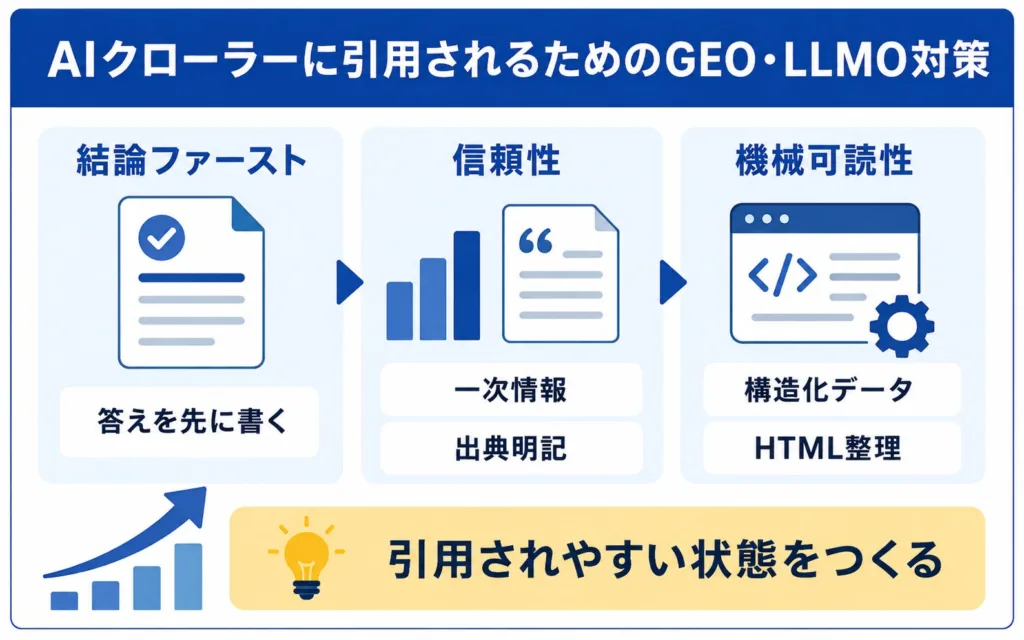
AIクローラーに引用されやすくするには、結論ファーストの構造・一次情報による信頼性・機械可読なHTMLという3点が鍵になります。これらはGoogle専用の裏技ではなく、ChatGPT Search・Perplexity・ClaudeなどAI検索全体で「引用されやすい状態」に近づけるための考え方です。
結論ファーストで回答に使われやすい文章構造にする
GEO(生成エンジン最適化/Generative Engine Optimization)やLLMO(大規模言語モデル最適化)とは、AIの回答に引用・参照されやすい状態をつくる最適化を指します。特定の検索エンジン専用の手法ではなく、AI検索全般に共通する考え方です。その核心の一つが、結論を先に書く文章構造です。プリンストン大学やジョージア工科大学などの共同研究(GEO, ACM KDD 2024、1万件のクエリで検証)では、ユーザーの問いに対する直接的な結論をページ上部に置く構成が、AI検索での引用率の向上と相関すると報告されています。各見出しの冒頭や本文の最初の200語以内に、2〜3文で独立して意味が通る「引用されやすい一文」を配置することが有効とされます。AIがそのまま抜き出せる明快な一文を用意するほど、引用される確率を高められる可能性があります。
一次情報や統計・専門家の見解・出典で信頼性を高める
同研究では、文章に加える「中身」によって引用率が大きく変わることも報告されています。とくに効果が高かったのは以下の要素です。
引用率を高めやすい要素
- 外部ソースの明記:信頼できる出典・外部リンクを付す
- 専門家の直接引用:実在する専門家や論文の言葉を引用フレーズで組み込む
- 具体的な統計データ:曖昧な表現を避け、数値・割合・実数で示す
研究では、上位の3戦術(出典明記・引用追加・統計追加)がいずれもAI検索での引用率を約30〜40%押し上げ、検索順位が低いサイトでは出典明記が最大115%の改善をもたらしたと報告されています。逆に、キーワードの詰め込みや過度な平易化、中身のない水増しは効果がない、もしくは悪化させることも示されました。これらは保証ではなくあくまで研究で観測された傾向ですが、「引用する価値がある」とAIに判断されやすい、密度の高い記述が有効と考えられます。
構造化データとセマンティックHTMLで機械可読性を高める
どれだけ良いコンテンツでも、機械が読み取れなければ引用されにくくなります。そこで土台になるのが、構造化データとセマンティックHTMLによる機械可読性の確保です。ただし、構造化データはAI検索への掲載や引用を直接保証するものではありません。Article・FAQ・OrganizationなどのJSON-LDで主題・著者・組織情報を明示し、見出し階層(h1〜h4)を飛ばさずに整えることで、検索エンジンやAIシステムがページ内容を理解しやすくなり、通常のSEOとLLMOの土台として有効になります。実際、Google検索のAI Overviews / AI Modeについては、Google公式が「特別なAI向け最適化や専用ファイル・スキーマは不要で、クロール可能性・インデックス・スニペット表示可否・コンテンツ品質といった通常のSEOの基本が前提になる」と説明しています。「構造化データを入れれば引用される」「llms.txtを置けばAI検索に出る」といった保証はない、という前提で取り組むのが安全です。
もう一つ見落とされやすいのが、多くのAIクローラーはJavaScriptを実行しないか、処理に大きな遅延が生じる点です。価格・製品情報・FAQなどの中核コンテンツは、クライアントサイドの動的生成ではなく、サーバーサイドレンダリング(SSR)または静的生成であらかじめHTMLに含めておくことが望まれます。具体的な点検項目はLLMOチェックリストで自社サイトを確認するもご活用ください。なお、ChatGPTでの引用獲得に特化した施策はChatGPTに引用されるためのLLMO対策、オウンドメディア向けの観点はオウンドメディアのLLMO対策で補足しています。
AIクローラーに関するよくある質問
ここでは、AIクローラーの制御を検討する担当者からよく寄せられる疑問に、簡潔に回答します。設定判断の最終確認にお役立てください。
AIクローラーをブロックするとSEO順位に影響しますか
学習用ボット(GPTBotやClaudeBotなど)のブロックは、Google検索の順位に直接の悪影響を与えないとされています。ただし、GooglebotやBingbotといった検索クローラーを誤ってブロックすると、検索流入そのものを失います。「学習用を拒否するつもりが、検索用まで巻き込んで弾いてしまう」設定ミスには十分注意してください。
GPTBotをブロックするとChatGPT Searchに表示されなくなりますか
いいえ。GPTBot(学習用)とOAI-SearchBot(検索用)は別物で、設定も独立しています。GPTBotを拒否しても、OAI-SearchBotを許可していればChatGPT Searchへの表示・引用の可能性は残ります。OpenAIも、この使い分けを正常な選択肢として公式に案内しています。
OAI-SearchBotとGPTBotの違いは何ですか
OAI-SearchBotはChatGPT Searchで表示・引用するための検索用クローラー、GPTBotは基盤モデルの学習用クローラーで、目的が異なります。引用による露出を狙うならOAI-SearchBotは許可、学習利用を避けたいならGPTBotは拒否、という組み合わせが定番の考え方です。
robots.txtとllms.txtの違いは何ですか
robots.txtはアクセスの許可/拒否を伝えるファイルです(ただし強制力はありません)。一方のllms.txtは制御ファイルではなく、AIにサイトの要点を理解させるための補助ファイルです。図書館にたとえるなら、robots.txtが「立入禁止の棚の表示」、llms.txtが「おすすめ図書のリスト」にあたります。
Google-ExtendedをブロックするとAI Overviewsに表示されなくなりますか
Google-Extendedは、GooglebotのようにHTTPリクエストで独立して動くクローラーではなく、Googleが取得したコンテンツをGeminiやVertex AIの学習・グラウンディングに使うかを制御するrobots.txt用トークンです。Google公式は、Google-Extendedの設定はGoogle検索への掲載やランキングには影響しないと説明しています。ただし、Google検索のAI機能への表示可否は通常のGooglebotによるクロール・インデックス・スニペット表示可否などに依存するため、Googlebotを誤ってブロックしないよう注意が必要です。
WordPressでAIクローラーを制御するにはどうすればいいですか
robots.txtを編集できるプラグインや、サーバー・CDN側の設定で制御できます。注意点として、テーマやプラグインがJavaScript依存だと本文がAIに読まれない場合があるため、本文がHTMLとして出力されているかをあわせて確認しましょう。CDNの一括ブロック設定がrobots.txtを上書きしていないかの点検も忘れないでください。
まとめ:AIクローラーは役割ごとに許可と拒否を使い分けよう
AIクローラーは「脅威か好機か」で一括判断するものではなく、役割ごとに使い分けるものです。基本は、学習用クローラーはブロックして負荷と権利を守り、検索用クローラーは許可してAI検索からの引用・流入を狙うという「守りと攻めの両立」にあります。そのうえで、結論ファーストの文章・一次情報・機械可読なHTMLというLLMO/GEOの基本を整えれば、引用される確率を高められる可能性があります。まずは自社のサーバーログとrobots.txtを確認し、どのボットが来ているか、設定に漏れや誤遮断がないかを点検することから始めましょう。判断や設定にお悩みの際は、株式会社アドカルへお気軽にご相談ください。
参考にした主な公式情報・一次情報
本記事の作成にあたり参照した、各社の公式ドキュメントおよび一次情報は以下のとおりです。最新の仕様は各リンク先で必ずご確認ください。
- OpenAI — Overview of OpenAI Crawlers(GPTBot / OAI-SearchBot / ChatGPT-User)
- OpenAI — Publishers and Developers FAQ(OAI-SearchBot許可・GPTBot拒否の考え方)
- Anthropic — クローラーに関する公式ヘルプ(ClaudeBot / Claude-SearchBot / Claude-User)
- Perplexity — Perplexity Crawlers(PerplexityBot / Perplexity-User)
- Google — Google クローラの概要(Googlebot / Google-Extended)
- Google — AI features and your website(AI Overviews / AI Mode)
- Gartner — 検索ボリューム25%減少予測(2024年プレスリリース)
- Cloudflare — AIクローラーのクロール対送客比率に関するレポート
- Aggarwal et al. — GEO: Generative Engine Optimization(arXiv / ACM KDD 2024)


