
LLMO対策のプロンプト設計とは?AI回答に登場する質問・判断軸・根拠情報の作り方
この記事でわかること
- LLMO対策のプロンプト設計とSEO・プロンプトエンジニアリングとの違い
- AI回答に登場するための4つの構成要素(ユーザー状況・選定基準・根拠資産・回答面)
- 4要素をコンテンツに落とし込む実装の進め方
- 観察すべき軸と、現場で起こりがちな3つの失敗パターン


ChatGPTやGemini、Perplexityといった生成AIに直接相談して比較候補を絞り込むユーザーが増え、「自社がAI回答の中でどう扱われるか」が新規接点の分岐点になりつつあります。そこで重要になるのが、AIへの命令文の書き方を磨く作業ではなく、市場のユーザーがAIに投げかける質問場面を先回りで定義し、その回答に自社がどう登場すべきかを設計するLLMOプロンプト設計という考え方です。
本記事では、SEOキーワード設計やプロンプトエンジニアリングとの違いを整理した上で、ユーザー状況・選定基準・根拠資産・回答面の4要素を連動させる設計の考え方から、コンテンツへの落とし込み方、観察軸、典型的な失敗パターンまでを通しで解説します。BtoB SaaSやオウンドメディアを運営するマーケティング・SEO担当者の方が、AI回答に自社を登場させるための情報設計を体系的に整えるための材料としてご活用ください。

【SEO・LLMO対策でお困りではないですか?】
株式会社アドカルは主に生成AIを活用したデジタルマーケティング支援やマーケティングDXに強みを持った企業です。
貴社のパートナーとして、少数精鋭で担当させていただくので、
「LLMO対策について詳しく知りたい」
「現状のSEO対策で成果が出ていない」
「LLMO対策でAI検索からの集客を強化したい」
とお悩みの方は、ぜひ弊社にご相談ください。
貴社のご相談内容に合わせて、最適なご提案をさせていただきます。
サービスの詳細は下記からご確認ください。無料相談も可能です。
目次
LLMO対策のプロンプト設計とは|AIに「何を聞かれた時に選ばれたいか」を定義する作業
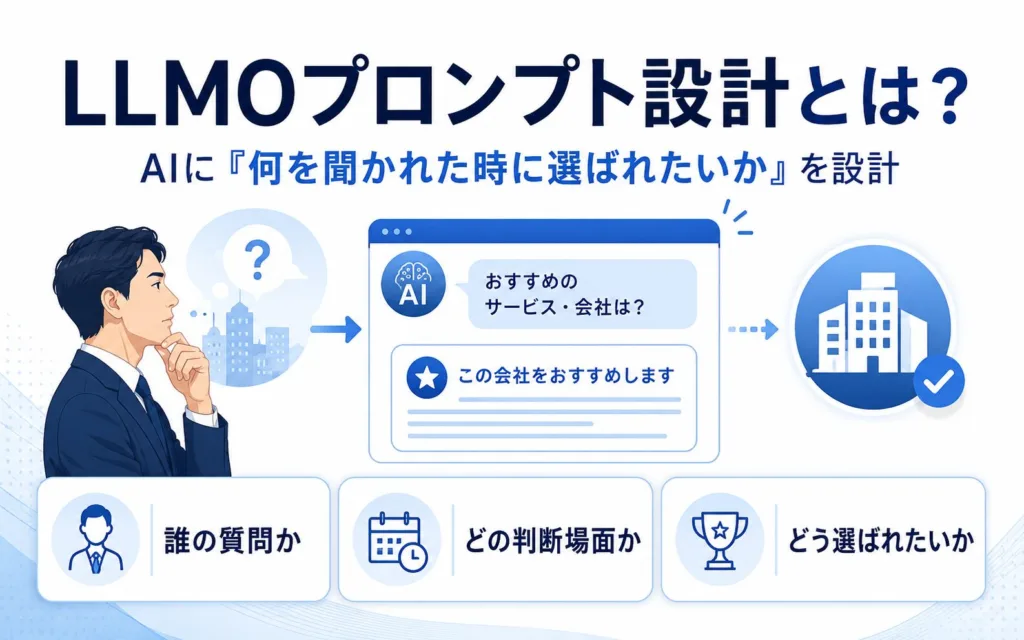
LLMOプロンプト設計とは、AIへの命令文の書き方を磨く作業ではなく、市場のユーザーがAIに投げかける質問場面を先回りで定義し、その回答に自社がどう登場すべきかを設計する取り組みです。本章ではSEOキーワード設計やプロンプトエンジニアリングとの違いを整理し、最初に決めるべき対象を明らかにします。
SEOキーワード設計との違いは「検索語」ではなく「判断場面」を設計する点
SEOキーワード設計は、検索ボリュームや順位という指標を起点に、検索窓に入力される語そのものを最適化単位として扱う発想です。一方、LLMOプロンプト設計が対象とするのは、検索語そのものではなく「ユーザーがどの判断局面でAIに相談したか」という質問のシーンそのものです。
たとえば「CRM 比較」という単語ではなく、「Gmailと連携できて、十数名規模のスタートアップが半年以内に導入できるCRMはどれか」という、文脈と前提を含む一連の判断場面が単位になります。検索語の最適化が単語の獲得競争であるのに対し、LLMOプロンプト設計は「自社が選ばれるべき判断場面そのものを定義する作業」だと整理できます。検索ボリュームが見えにくい代わりに、購買意思決定に直結する場面を起点に設計できる点が、SEOキーワード設計との本質的な違いです。LLMOそのものの位置づけから整理しておきたい場合は、SEOとの違いを含めたLLMOの基礎を解説した記事もあわせてご確認ください。
プロンプトエンジニアリングとの違いは「AIへの入力」ではなく「市場の質問」を設計する点
プロンプトエンジニアリングは、自社の業務担当者がAIから期待する出力を引き出すために、入力プロンプトを最適化する技術です。最適化の対象は「AIに何をどう入力するか」であり、自社のコントロール下にある作業です。
これに対しLLMOプロンプト設計が扱うのは、自社ではなく市場のユーザーがAIに対して投げる質問群です。「導入規模を抑えたいから安価なツールを教えてほしい」「導入実績の多いベンダーを比較したい」といった、自社が直接書き換えることのできない外部の質問が対象になります。自社で書ける入力を磨く作業ではなく、自社のコントロール外で発生する質問を観察し、その質問に対してAIが組み立てる回答の中に、自社がどう登場するかを設計する作業である点が、プロンプトエンジニアリングとの決定的な違いです。
LLMOプロンプト設計で最初に決めるべき3つの対象
LLMOプロンプト設計を始めるにあたり、まず明確にしておきたい対象が3つあります。手順を決める前に、対象そのものを言語化することが先決です。
- 誰の質問を獲りに行くか:業界・規模・職種を含む具体的なユーザー像を定義する
- どの判断局面の質問を獲りに行くか:比較段階か導入段階かなど検討フェーズを特定する
- AIに何と答えてほしいか:推薦されたい文脈と並び方を事前に決めておく
この3点を曖昧にしたまま施策を進めると、出てきた質問リストの粒度がばらつき、根拠資産の整備先も定まりません。なお本記事では、AEO・GEO・LLMOの関係について、AEOを「AI回答での直接的な引用獲得」、GEOを「生成エンジン上での可視性最適化」、LLMOを「ブランド推薦・引用を含む継続的な最適化」と、実務上の整理として独自に定義しています。確立された分類というよりも、本記事の議論の土台として共有しておきたい区分です。用語の使い分けを掘り下げたい場合は、LLMO・AIO・GEOの違いを整理した記事も参考になります。
LLMO対策のプロンプト設計の4つの構成要素|質問・判断軸・根拠・回答面の設計図

LLMOプロンプト設計は、独立した4つの構成要素の組み合わせとして整理できます。4要素は単独で機能するものではなく、連動させてはじめてAI回答に登場する可能性を高められる構造になっています。
ユーザー状況:誰がどの意思決定段階で質問するか
ユーザー状況(User Situation)は、「誰が、どんな業界・規模・予算・意思決定段階で、何に悩んでAIに質問するか」を具体的に描く要素です。ペルソナだけでも、検討段階だけでも足りず、両者を文脈と一緒に組み合わせて定義する必要があります。
たとえば同じ「人事評価制度」というテーマでも、従業員数百名規模の上場準備中の企業の人事責任者が制度刷新を検討している場面と、十数名の創業期スタートアップが評価制度を初めて導入しようとしている場面とでは、AIが返すべき回答も、自社が登場すべき推薦文脈も変わります。ユーザー状況を曖昧に置いたまま設計を進めると、後続の選定基準や根拠資産が一般論で薄く広がり、AI回答に採用されにくい状態に陥ります。検索語の発想からAI回答を意識した質問候補に視野を広げる考え方は、AI回答を意識したキーワード選定でも詳しく解説しています。
選定基準:AIが比較・推薦に使う評価軸を洗い出す
選定基準(Selection Criteria)は、特定のユーザー状況において、AIが「候補に挙げる/挙げない」を分ける判断軸です。価格帯、対応規模、業種特化、導入難易度、サポート体制、実績、契約形態など、評価のものさしとなる軸群を指します。
AIは複数の引用ソースから繰り返し言及される判断軸を採用しやすい傾向が観測されています。逆に言えば、自社が満たしているのに公開情報として書かれていない判断軸は、AIにとって存在しない強みと見なされます。たとえば「日本語圏特化のサポート」を強みとしているのに、公式サイトやFAQでその点を明示していなければ、AIは比較表に並べることができません。選定基準の洗い出しは「自社の強みのうち、外部に発信されている軸はどれか」を点検する作業でもあります。
根拠資産:自社の一次情報と第三者言及を組み合わせて整理する
根拠資産(Evidence Assets)は、AIに引用させたい情報の所在と中身を指します。ここで重要なのは、自社サイト内の情報だけで完結させない点です。根拠資産は次の2層を組み合わせて初めて機能します。
- 自社の一次情報層:調査データ、導入実績、事例、機能・価格、FAQ、監修者情報など
- 第三者言及層:比較メディア、業界記事、PR、レビュー、コミュニティ上の言及など
実際のAI回答では、自社サイトの記述に加えて、第三者サイト上の言及が組み合わさって採用される傾向が観測されています。自社サイトをいくら整えても、第三者の言及が薄ければ、AIにとっては「合意の取れていない主張」に見えてしまいます。KDD 2024で発表されたAggarwalらの論文「GEO: Generative Engine Optimization」では、統計データの提示や引用、専門家コメントといった要素を組み合わせることで、生成エンジン上の可視性が最大40%程度改善し得るという結果が報告されています。本記事はこの数値を断定的に当てはめるのではなく、根拠資産の整備が可視性に寄与し得るという傾向の参考として位置づけます。SNSや業界コミュニティ上の言及をLLMOにどう接続するかという観点は、LLMO×SNS対策でも整理しています。
回答面:AI回答に出したい表現・比較軸・URLを設計する
回答面(Answer Surface)は、AI回答の中で自社が「どう登場すべきか」のゴール像を定義する要素です。並び順、推薦文の長さ、競合と並ぶ比較軸、引用されるURLなどを、施策前にあらかじめ言語化しておきます。
回答面を定義しないまま施策を進めると、AI回答に登場すること自体が目的化しやすく、望ましくない文脈で登場してしまうリスクがあります。たとえば「最安値の選択肢のひとつ」として並ぶのではなく「導入実績の豊富な選択肢」として推薦されたい場合は、その登場文脈に対応する根拠資産と比較軸を逆算して整える必要があります。回答面は、ユーザー状況・選定基準・根拠資産の3要素を統合する終着点であり、設計の出発点として最初に言語化しておくことが望ましい要素です。
LLMO対策のプロンプト設計をコンテンツに落とし込む方法|質問から根拠情報まで整備する
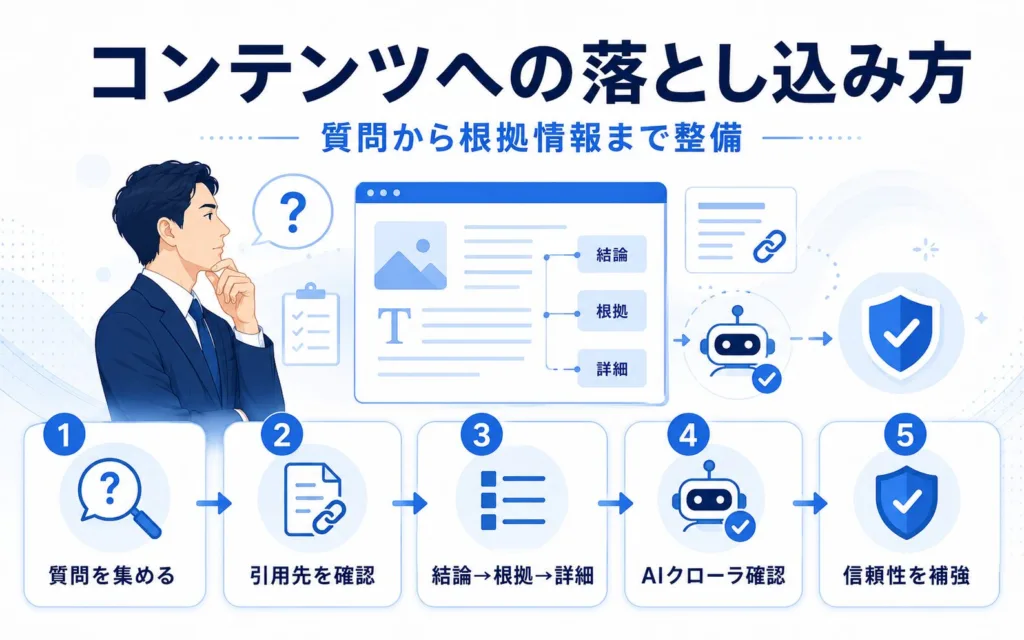
ここからは、4要素を実装としてコンテンツに落とし込むための整備の進め方を扱います。質問の集め方、引用の逆算、コンテンツの組み立て方、技術的なアクセス性、信頼性の補強という5つの観点から整理します。
顧客の声を比較・導入・乗り換え・費用対効果の4場面で整理する
質問を集める起点として最も有用なのは、自社が既に保有している顧客接点の記録です。問い合わせフォーム、商談ログ、失注理由、カスタマーサクセスの面談メモ、サイト内検索のログなどから、ユーザーが実際に使っている語彙を採取します。SEOキーワードからの転換は補助手段に位置づけ、まずは生の言葉を優先します。
採取した質問は、検討段階ではなく「意思決定の論点」で整理します。具体的には次の4場面に振り分けると扱いやすくなります。
- 比較:複数候補のうちどれが自社に合うかを問う場面
- 導入:導入手順や前提条件を問う場面
- 乗り換え:既存サービスからの移行可否を問う場面
- 費用対効果:投資対効果や継続価値を問う場面
この4場面に揃えると、後続の根拠資産の整備先が論点単位で明確になります。
AIが引用している競合URLを確認し、自社に足りない根拠情報を洗い出す
本記事で最も重視したい観点が、この引用ギャップ分析です。「自社が何を書くべきか」を社内資源だけで考えるのではなく、「AIが今この瞬間に何を引用しているか」を外から逆算して観察する視点です。
具体的には、整理した想定質問をChatGPT、Gemini、Perplexityなどに実際に投げ、回答内に登場するURLを記録します。自社が登場しない場合、あるいは登場しても弱い扱いに留まっている場合、AIが代わりに引用している情報源を分解して観察します。観察対象は、競合の公式サイト、比較メディアの記事、業界の解説記事、FAQページ、レビューサイト、SNS、業界コミュニティ、Q&Aサイトなどです。
引用元を観察する際は、(1)どんな判断軸が使われているか、(2)どんな根拠データが採用されているか、(3)どんな第三者言及が引かれているか、の3点を分解します。そのうえで、自社サイトに不足している情報、第三者言及として整えるべき情報を特定します。引用ギャップ分析は、コンテンツ企画より前に置くべき前提作業として位置づけたい観点です。AIが何を引いているかを見ずに新しい記事を書いても、AIに採用される保証はありません。
結論・根拠・詳細の順にコンテンツをチャンク化する
AIは長文を全体としては引用せず、結論を含むまとまり(チャンク)を抽出して回答に組み込む傾向が観測されています。そのため、見出し直下に2〜3文の結論サマリーを置き、その後に根拠データ、最後に詳細という順番でコンテンツを組み立てると、AIにとって採用しやすい構造になります。
各段落は、前後の文脈に依存せず単体で意味が通じる書き方が望ましいといえます。「前述の通り」「これを踏まえると」といった照応表現が多いと、段落だけを切り出した際に意味が崩れ、抽出に不利になる傾向があります。比較表や条件分岐、FAQ形式など、構造化された情報の形式を組み合わせると、論点単位での抽出にも対応しやすくなります。既存記事をAI回答で引用されやすい構造へ見直す観点については、オウンドメディアのLLMO対策でも解説しています。
AIクローラが重要ページにアクセスできる状態を確認する
どれだけ良質なコンテンツを整えても、AIクローラがページを取得できなければ引用候補に入りません。マーケ担当として持っておきたいのは、技術的詳細ではなく、情シスやエンジニアに相談する際の問題意識です。
確認しておきたい観点は次の3点です。
- JavaScript依存の解消:重要情報をHTML上に展開して配置する
- セキュリティ設定の見直し:AIクローラを意図せず遮断していないか確認する
- サーバーログの観察:主要クローラのアクセス状況を点検する
JavaScript依存のアコーディオンやタブ、モーダル内に重要情報を入れている場合、クローラによっては取得されない可能性があります。FAQや料金、機能比較といったAIに読ませたい情報は、最初からHTML上に展開された状態が望ましい配置です。Cloudflareなどのセキュリティサービスの初期設定で、特定のAIクローラを遮断しているケースもあるため、ビジネス上の意図に沿った許可設定になっているかを確認します。
主要なAIクローラの挙動や許可設定は、各社が公開している公式ドキュメントで確認できます(OpenAIのクローラ仕様、PerplexityBotの公式ドキュメント、Googleのクローラ一覧)。
サイト構造そのものや改修時に押さえておきたいポイントは、サイトリニューアル時のLLMO対策でも整理しています。
一次情報・監修・更新日・構造化データで信頼性を補強する
信頼性の補強は、単独のテクニックを並べる作業ではなく、AIに「信頼できる情報源」と認識させるための土台づくりとして位置づけます。観点は4点に集約できます。
- 一次情報の明示:自社調査、独自事例、導入実績などを公開する
- 監修者の実名と経歴:監修ページや外部プロフィールと接続する
- 更新日の管理:定期的な内容更新と更新日表記を整える
- 構造化データの実装:Article、FAQPage、Person、Organizationを適切に設定する
他では読めない一次情報は、AIに引用される傾向が観測されています。監修者の実名・経歴と外部プロフィールが接続されていると、AIにとって「実在する専門家による情報」として解釈しやすくなります。構造化データは、記事と組織と人物のエンティティ間の関係性をAIが整理する手がかりになります。仕様はSchema.orgで、実装上の留意点はGoogleの構造化データドキュメントで確認できます。4点が揃って初めて信頼性の土台が成立する、という前提で運用していくことが望ましい姿勢です。
LLMO対策のプロンプト設計の確認方法|順位ではなく回答内での扱われ方を見る
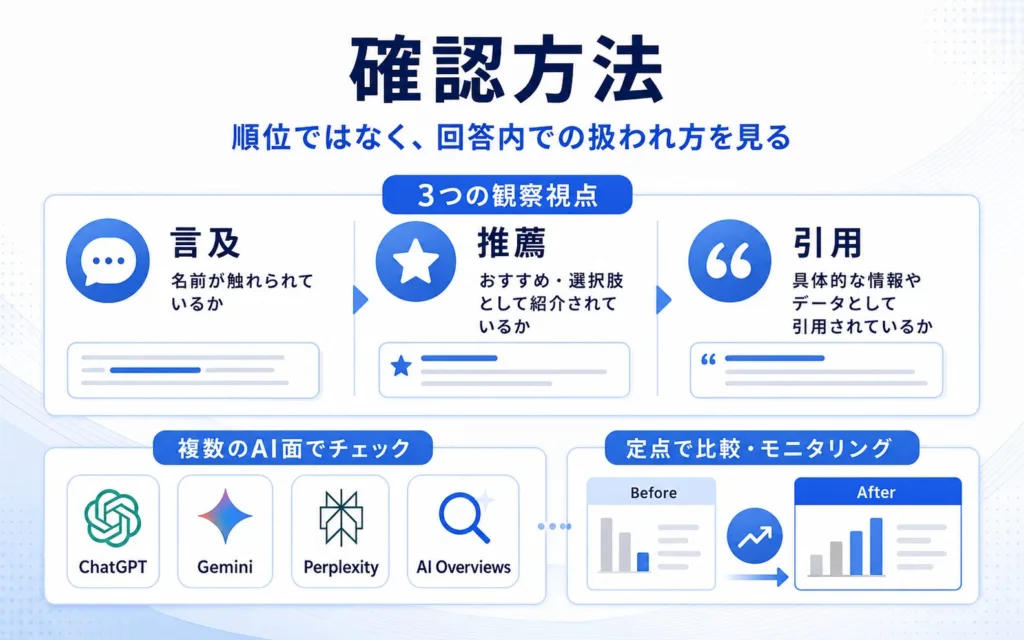
LLMOの観察では、検索順位のような単一の指標だけでは判断材料が不足します。本章では、何を分離して見るかという観察軸の整理に絞って扱います。
言及・推薦・引用を分けて観察する
AI回答における自社の扱われ方は、単一の指標で把握できるものではありません。最低限、次の3つを別物として分けて見る必要があります。
- 言及:回答本文に自社名が登場している状態
- 推薦:候補として薦められている文脈で登場している状態
- 引用:参照元として自社URLが採用されている状態
自社が推薦されていても、引用ソースに自社URLが採用されていないケースは頻繁に観測されます。逆に、引用ソースには載っていても、回答本文の推薦には自社名が出ていない場合もあります。3つを混同したまま「AI回答に出ている」とだけ捉えると、改善すべき先がコンテンツなのか、第三者言及なのか、構造化データなのかを切り分けられません。言及・推薦・引用をどのように記録し、どこまで分けて捉えるかについては、LLMOの効果測定でも詳しく整理しています。
AI検索面ごとに回答・引用の出方を分けて観察する
ChatGPT、Gemini、Perplexity、Google AI Overviewsなど、AI検索面ごとに回答の組み立て方や引用ソースの選好には違いがある傾向が観測されています。同じ質問を投げても、ある面では自社が推薦され、別の面では競合だけが並ぶ、という状況も珍しくありません。
各面の具体的な挙動を断定的に決めつけて施策を最適化するのではなく、「面ごとに違いがあるため、面別に観察する必要がある」という運用思想を持つことが重要です。観察対象の面と、その面でどの質問を観察するかを最初に決めておき、面ごとに別シートで結果を記録していくと、施策の効果が面ごとに分解して評価できます。
施策前後で「根拠の採用状況」を確認する
観察すべきは、自社が登場した回数の増減だけではありません。施策後に、自社が新たに公開した根拠資産(事例、調査、第三者言及など)が、AI回答内で実際に引かれているかどうかを確認することが重要です。
たとえば新しく公開した導入事例ページが、想定質問のAI回答で引用されているか、新たに獲得した比較メディアでの掲載が、AIが参照する情報源として採用されているか、を1件ずつ確認します。露出が増えた・減ったという量的な変化だけでなく、AIが何を引いて自社を推しているかという質的な観察まで含めることで、コンテンツ・PR・プロダクト整備のどこに次の投資をすべきかが見えてきます。
LLMO対策のプロンプト設計で失敗しやすい3つのポイントと対策
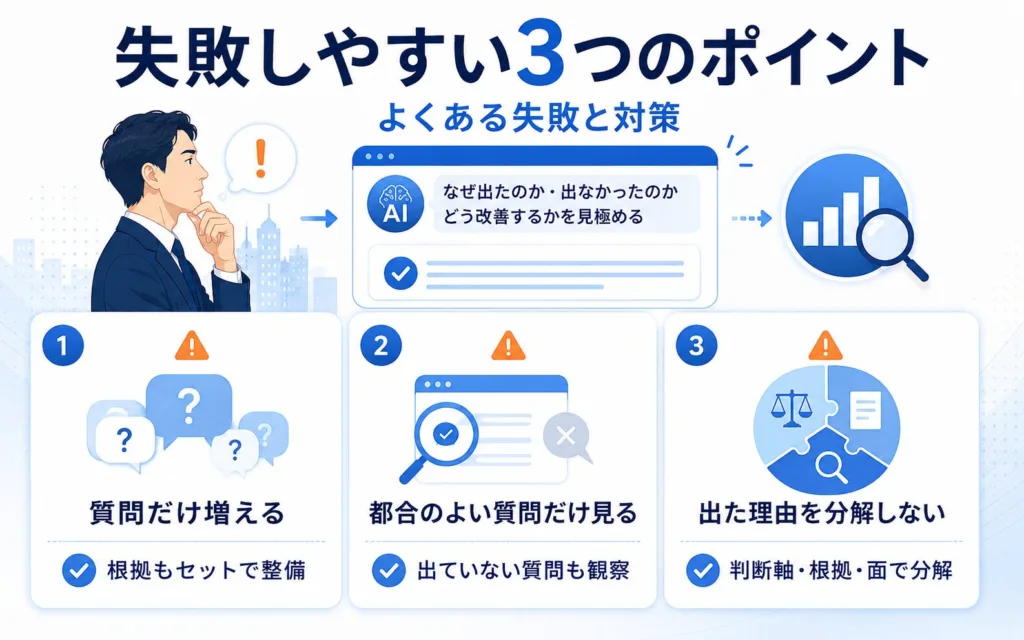
LLMOプロンプト設計の現場で頻繁に見られる失敗は、量や頻度の問題ではなく、設計の組み立て方そのものに起因する構造的なものが中心です。本章では3つの典型に絞って整理します。
質問文だけを増やし、根拠情報の整備まで進まない
最も典型的な失敗が、想定質問の一覧表だけが社内で膨らみ、それを支える根拠情報の整備が進まない状態です。質問リストを作ること自体が成果物として扱われ、AIが引用すべきコンテンツが社内に存在しないままに留まります。
対策としては、想定質問を起こす段階で、必ずペアで「この質問に答えるための根拠は自社のどこにあるか」「不足している根拠は何か」を1件ずつ書き出します。根拠が見当たらない質問が大量に出てくる場合は、コンテンツ未整備の領域が可視化されたと捉え、コンテンツ計画と第三者言及獲得の優先順位づけに直接つなぎます。質問と根拠を1対1で並走させる運用ルールを最初に決めておくことが、量だけが増える状態を防ぐ歯止めになります。自社サイトの現状を一通り点検したうえで優先順位を決めたい場合は、LLMOチェックリストを活用するのも有効です。
自社に都合のよいプロンプトだけを観察してしまう
2つ目の失敗は、自社が登場する質問だけを観察対象に選んでしまうケースです。自社名を含む質問や、自社が強い領域の質問ばかりを並べた結果リストを眺めても、AI回答内での扱われ方は良く見えますが、改善余地はほとんど見えません。
本来観察すべきは、自社が登場すべきなのに登場していない質問群です。市場のユーザーが本当に投げているであろう質問のうち、自社が候補として並ぶべき領域で並んでいない質問を意図的にリスト化し、AIが代わりに引いている情報源を分解する観点が必要になります。観察対象に「自社が出ていない質問」を一定割合含めるルールを置いておくと、観察結果が自社に都合よく偏ることを避けられます。
AI回答に出た理由を分解せず、施策の改善先を誤る
3つ目の失敗は、AI回答に登場した/しなかったという事実だけを集計し、その背景を分解しないまま施策の改善先を判断してしまうケースです。登場の有無だけでは、改善すべき先が自社サイトのコンテンツなのか、外部の第三者言及なのか、判断軸の言語化なのかを切り分けられません。
対策は、登場した/しなかった結果に対して、(1)どの判断軸でAIが選んだか、(2)どの根拠資産が引かれた/引かれなかったか、(3)どの面で起きた変化か、という3つの観点で分解することです。この分解を挟むことで、コンテンツ強化・PR強化・プロダクト訴求の整理など、次の打ち手の候補が論点ごとに分かれて見えてきます。結果だけを集計してダッシュボード化しても、施策の改善には直接つながらないという前提で運用設計を組むことが重要です。
まとめ:LLMO対策のプロンプト設計はAI時代の市場理解と情報設計である

LLMOプロンプト設計は、プロンプトエンジニアリングでもSEOキーワード設計でもなく、市場の判断場面と自社の情報設計を結ぶ独立した取り組みです。ユーザー状況・選定基準・根拠資産・回答面の4要素を連動させ、自社サイトの整備、第三者言及の獲得、AIクローラへの取得性確保までを一体で進めることで、AI回答で扱われやすい状態を体系的に作っていけます。SEOで培ってきた検索意図の読解力やコンテンツ設計力は、LLMOにおいてもそのまま強力な土台として活きます。自社の業界・商材に合わせてLLMOプロンプト設計を整理したい場合は、LLMO対策・コンサルティングサービスの無料相談をご活用ください。
【SEO・LLMO対策でお困りではないですか?】
株式会社アドカルは主に生成AIを活用したデジタルマーケティング支援やマーケティングDXに強みを持った企業です。
貴社のパートナーとして、少数精鋭で担当させていただくので、
「LLMO対策について詳しく知りたい」
「現状のSEO対策で成果が出ていない」
「LLMO対策でAI検索からの集客を強化したい」
とお悩みの方は、ぜひ弊社にご相談ください。
貴社のご相談内容に合わせて、最適なご提案をさせていただきます。
サービスの詳細は下記からご確認ください。無料相談も可能です。


