
クエリファンアウトとは?仕組みからLLMO対策まで実務で使える全知識を解説
この記事でわかること
-
クエリファンアウトの意味と、AIがサブクエリを生成→並列検索→統合する動作の流れ
-
クエリファンアウトとLLMOの関係性、および従来のSEOとの違い
-
AIに参照されやすいページの特徴と、すぐに着手できる実務5施策
-
クエリファンアウト時代の効果測定で見るべき指標と、よくある誤解の正し方

GoogleのAI OverviewsやAIモードが普及し、「自社サイトがAIに引用されない」「従来のSEO施策だけでは成果が見えにくい」と感じている方は多いのではないでしょうか。その原因を理解するために押さえておきたいのが、クエリファンアウト(Query Fan-out)という技術です。
本記事では、クエリファンアウトの仕組みをわかりやすく解説した上で、LLMO(大規模言語モデル最適化)との関係、AIに拾われやすいページの特徴、すぐに着手できる実務施策、そして効果測定の方法までを一気通貫で紹介します。AI検索時代のコンテンツ戦略を見直すための実践的なガイドとして、ぜひお役立てください。

【SEO・LLMO対策でお困りではないですか?】
株式会社アドカルはSEO対策・LLMO対策に強みを持った企業です。
貴社のパートナーとして、少数精鋭で担当させていただくので、
「LLMO対策について詳しく知りたい」
「現状のSEO対策で成果が出ていない」
「LLMO対策でAI検索からの集客を強化したい」
とお悩みの方は、ぜひ弊社にご相談ください。
貴社のご相談内容に合わせて、最適なご提案をさせていただきます。
サービスの詳細は下記からご確認ください。無料相談も可能です。
目次
クエリファンアウトとは?
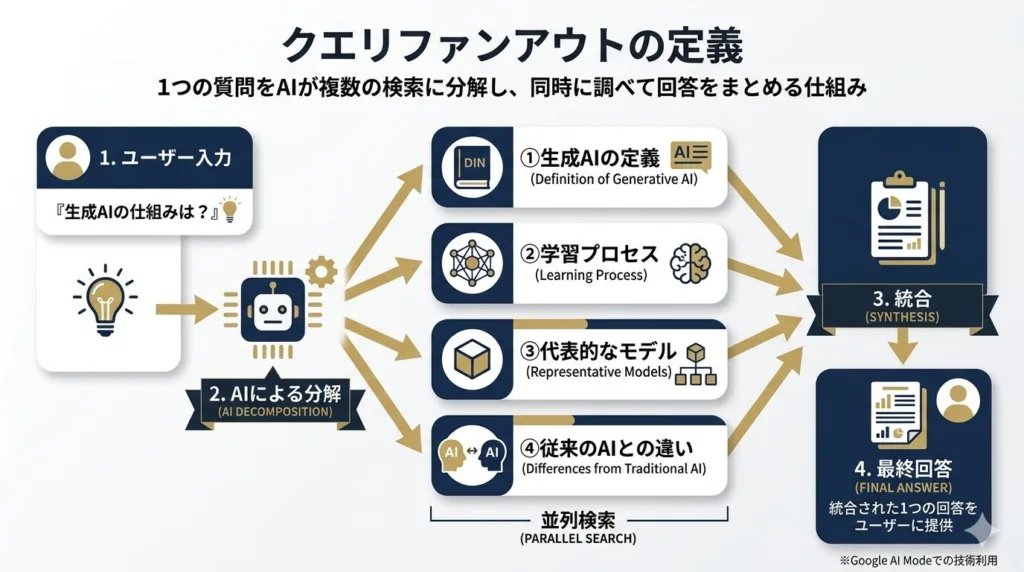
クエリファンアウトは、GoogleのAI検索で使われている情報取得の仕組みです。ここでは定義や語源、Google公式の説明、従来検索との違いを整理します。
クエリファンアウトの定義と「扇状に広がる」検索の意味
クエリファンアウト(Query Fan-out)とは、1つの質問をAIが複数の小さな検索(サブクエリ)に分解し、同時に調べて回答をまとめる仕組みです。GoogleはAI Modeでこの技術を使うと説明しています。「Fan-out」は英語で「扇状に広がる」という意味があり、1つの質問から複数の問いが扇のように広がっていく動作を表しています。
たとえば「生成AIの仕組みを教えて」と検索した場合、AIは裏側で「生成AIの定義」「学習プロセス」「代表的なモデル」「従来のAIとの違い」など、複数の観点を自動的に立てて並列に情報を集めます。こうして得られた各結果を統合し、1つのまとまった回答としてユーザーに返すのがクエリファンアウトの基本的な流れです。
Google公式が説明するAI Overviews・AIモードでの役割
Googleは公式情報の中で、AI OverviewsやAIモードにおいて、質問をサブトピックに分解して複数の関連検索を行い回答を構築する仕組みを説明しています。
GoogleのSearch Central公式ドキュメントには、「AI OverviewsとAIモードはクエリファンアウト技術を使い、サブトピックやデータソースにまたがる複数の関連検索を発行してレスポンスを構築することがある」と記載されています。GoogleのVP of Product for SearchであるRobby Stein氏は下記の動画で、AIを活用した検索体験が月間約15億人のユーザーに提供されていると述べており、この技術の影響範囲は非常に大きいといえます。
従来のキーワード検索との本質的な違い
従来の検索エンジンでは、ユーザーが入力したキーワードとWebページ上のテキストの一致度合いを中心に評価し、関連性の高いページを一覧で返す仕組みでした。つまり「1つのクエリに対して1セットの検索結果」という直線的な処理が基本です。
一方、クエリファンアウトでは1つの質問から複数のサブクエリが生成され、それぞれが異なる観点・異なるデータソースから情報を取得します。両者の違いを表にまとめると、次のようになります。
| 比較項目 | 従来のキーワード検索 | クエリファンアウトを用いるAI検索 |
|---|---|---|
| 検索の起点 | 1つのクエリをそのまま処理 | 1つのクエリを複数のサブクエリに分解 |
| 情報収集の方法 | 単一の検索結果セットを表示 | 複数の関連検索を並列実行して統合 |
| ユーザーへの返し方 | リンク一覧中心 | 要約・統合回答中心 |
| 評価されやすい要素 | キーワード一致、被リンク、ページ評価 | 関連性、網羅性、信頼性、文脈適合 |
| コンテンツ設計の考え方 | キーワード単位 | トピック・論点・サブクエリ単位 |
このように、評価の軸がキーワードの出現頻度や被リンク数だけでなく、情報の網羅性や文脈的な関連性、情報源の信頼性へと広がっています。その結果、ページ全体の順位だけでなく、ページ内の特定トピックについて明確に説明されているかどうかも、これまで以上に重要になっていると考えられます。この変化は、コンテンツの設計思想そのものを見直すきっかけになるでしょう。
なぜ今クエリファンアウトが注目されているのか
クエリファンアウトへの関心が急速に高まっている背景には、AI検索の普及と検索行動の変化があります。
第一に、AI Overviews・AIモードの利用が世界的に拡大しています。Googleは2025年5月時点でAI Overviewsを200以上の国と地域、40以上の言語に展開したと発表しました。(参照:Google公式ブログ「AI Overviews expand to over 200 countries and territories」)さらにAIモードも2025年5月に米国で正式にリリースされ、より高度なAI検索体験が一般ユーザーに届き始めています。
第二に、従来の「1キーワード=1検索=1セットの結果」という発想では、AI検索でのコンテンツ露出が難しくなってきています。クエリファンアウトでは1つの質問が複数のサブクエリに展開されるため、サイト側も複数のサブトピックに対応できるコンテンツ設計が必要です。
こうした背景から、SEO担当者やWebサイト運営者にとってクエリファンアウトの理解は「知っていると有利」ではなく「知らないと対策が立てられない」レベルの基礎知識になりつつあります。
クエリファンアウトの動作プロセスを具体例で理解する
クエリファンアウトがどのように動作するのか、処理の流れ・サブクエリの種類・具体例の3つの切り口で解説します。
サブクエリ生成→並列検索→情報統合の3ステップ
クエリファンアウトの動作は、大きく3つのステップで構成されています。
第1ステップは「サブクエリ生成」です。ユーザーの入力をLLMが意味的に解析し、質問の背後にある複数の意図や関連トピックを抽出します。そこから、それぞれの意図に対応する具体的なサブクエリを自動生成します。GoogleはAIモードの基盤としてGeminiのカスタム版を用いていると説明しており、その上で複数の関連検索を組み合わせて回答を構築しています。
第2ステップは「並列検索」です。生成された複数のサブクエリが同時に実行され、Web検索結果だけでなく、ナレッジグラフ、Googleショッピング、ニュース、動画、地図情報など多様なデータソースから横断的に情報を収集します。複数の専門チームが同時に調査を進めるようなイメージです。
第3ステップは「情報統合」です。各サブクエリから得られた情報について、関連性や信頼性の評価、重複情報の排除、整合性の検証が行われます。その上でLLMが自然言語として回答を再構成し、ユーザーに提示します。必要に応じて再検索が実行されるケースもあります。
サブクエリの代表的な分類パターン
クエリファンアウトで生成されるサブクエリは、その目的によっていくつかのパターンに分類できます。Googleの公開特許や各種分析でも、関連する複数クエリを生成して検索精度を高める考え方が確認されています。ここでは実務上の理解に役立つ代表的な分類を整理します。
| 分類パターン | 目的 | 例 |
|---|---|---|
| 同義・言い換えクエリ | 同じ意図を別表現で補う | 「LLMOとは」→「大規模言語モデル最適化とは」 |
| 潜在ニーズの明示化 | ユーザーが明言していない疑問を補う | 「LLMO対策 何から始める」→「LLMO 手順」「LLMO 必要な体制」 |
| 詳細の深掘り | 基本情報を具体化する | 「LLMO 効果測定」「LLMO 事例」 |
| 曖昧さの解消 | 意図のブレを補正する | 「AI最適化」→ SEOなのか、広告なのか、LLMOなのか |
| 関連トピックへの拡張 | 周辺知識も集める | 「LLMO」とあわせて「SEOとの違い」「RAGとの関係」 |
これらのパターンが組み合わされることで、1つの質問に対して多角的な情報収集が実現します。LLMO対策を考える上では、自社コンテンツがどのパターンのサブクエリに対応できるかを意識することが重要です。
実例で見る:1つの質問がどのように複数検索へ分解されるか
ここでは、「LLMO対策 何から始める」という検索を例に、クエリファンアウトがどのように機能するかを見てみましょう。
AIはまずこの質問を意味的に解析し、「LLMOの定義を知りたい」「具体的な対策手順を知りたい」「SEOとの違いを理解したい」「必要なツールや体制を把握したい」「効果測定の方法を知りたい」といった複数の潜在的な疑問を推測します。それぞれに対応するサブクエリが生成され、たとえば「LLMOとは」「LLMO対策の手順」「LLMO SEO 違い」「LLMO 効果測定 方法」などが並列に検索されます。
各サブクエリの検索結果から関連性の高い情報が抽出され、統合処理を経て「LLMOとは大規模言語モデルに自社情報を正しく参照させる施策で、最初に取り組むべきは……」といった包括的な回答が生成されます。ここで注目すべきは、AIが参照する情報は、必ずしも従来の検索順位だけで決まるわけではないという点です。サブクエリごとの関連性や情報の明確さも重要になるため、特定のサブトピックに対して質の高い情報を提供できているかどうかが鍵を握ります。
クエリファンアウトとLLMOの関係をわかりやすく整理する
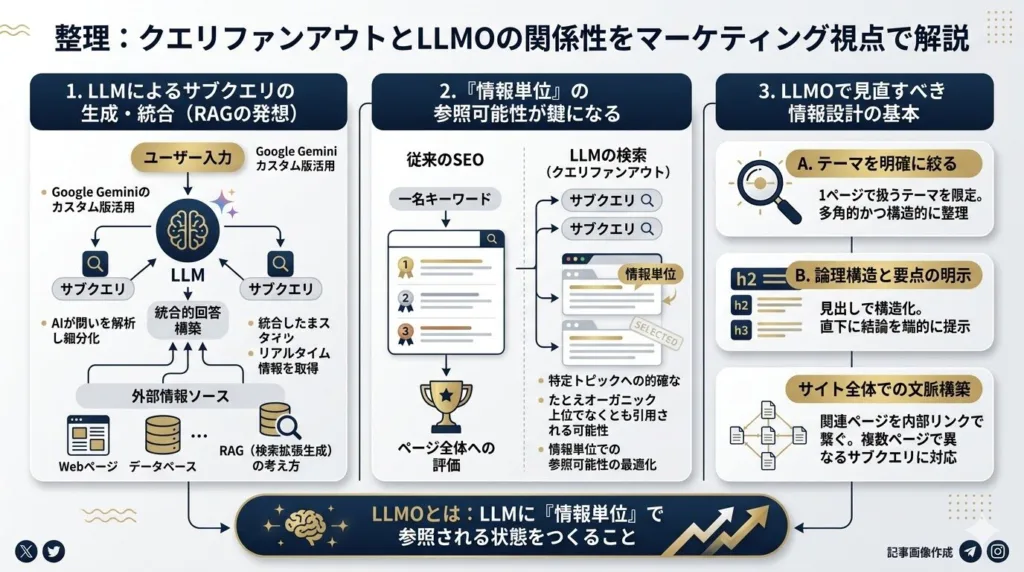
クエリファンアウトの仕組みがわかると、LLMO(大規模言語モデル最適化)で何を意識すべきかが見えてきます。ここでは両者の関係を3つの視点で整理します。
▶LLMOの概要についてはこちらの記事をご覧ください。
LLMがサブクエリを生成・統合する仕組み
クエリファンアウトにおいてサブクエリの生成と統合を担っているのは、LLM(大規模言語モデル)です。GoogleはAIモードの基盤としてGeminiのカスタム版を用いていると説明しており、ユーザーの入力を受け取ると、まずLLMが質問の意図を解析してサブクエリを自動生成します。各サブクエリの検索結果はLLMのコンテキスト内に取り込まれ、信頼性や関連性を評価した上で統合的な回答が構築されます。
この一連のプロセスは、RAG(Retrieval-Augmented Generation:検索拡張生成)と呼ばれる技術の考え方に近いものです。LLMの内部知識だけに頼らず、外部のWebページやナレッジグラフからリアルタイムに情報を取得して回答を生成する仕組みであり、クエリファンアウトはその「検索」の部分をより高度化した技術だと捉えることができます。
なぜ「検索順位」だけでなく「情報単位の参照」が重要になるのか
従来のSEOでは、ターゲットキーワードで検索結果の上位に表示されることが最大の目標でした。しかしクエリファンアウトの登場により、この前提が変わりつつあります。
LLMはサブクエリごとに最適な情報を探しますが、その際にページ全体のランキングだけでなく、ページ内の特定トピックについて明確に説明されているかどうかも評価に影響していると考えられます。あるサブクエリに対して的確な説明があれば、たとえそのページがオーガニック検索で上位にいなくても、AIの回答に引用される可能性があります。
この変化が意味するのは、「ページ単位のランキング最適化」だけでなく「情報単位での参照可能性の最適化」も重要になっているということです。LLMOとは、まさにこの「LLMに情報単位で参照される状態」をつくるための施策であり、クエリファンアウトの仕組みを理解することがLLMO対策の出発点になります。
LLMOで見直すべき情報設計の考え方
クエリファンアウトを前提としたLLMOでは、コンテンツの情報設計を「LLMがサブクエリの回答として参照しやすいか」という観点で見直す必要があります。
具体的には、1つのページで扱うテーマを明確に絞り、そのテーマについて多角的かつ構造的に情報を整理することが求められます。見出し(h2・h3)で論理構造を明示し、各見出しの直下でその問いに対する結論や要点を端的に示すことで、LLMが情報を抽出しやすくなります。
また、個々のページをバラバラに最適化するのではなく、関連するページ同士を内部リンクでつなぎ、テーマの文脈をサイト全体で構築する視点も欠かせません。LLMはサブクエリごとに異なるページから情報を収集するため、サイト内の複数ページが異なるサブクエリに対応できる状態が理想的です。こうした「サイト全体でLLMの問いに応える」設計こそが、これからのLLMOにおける情報設計の基本になります。
クエリファンアウトがSEO・LLMOに与える影響
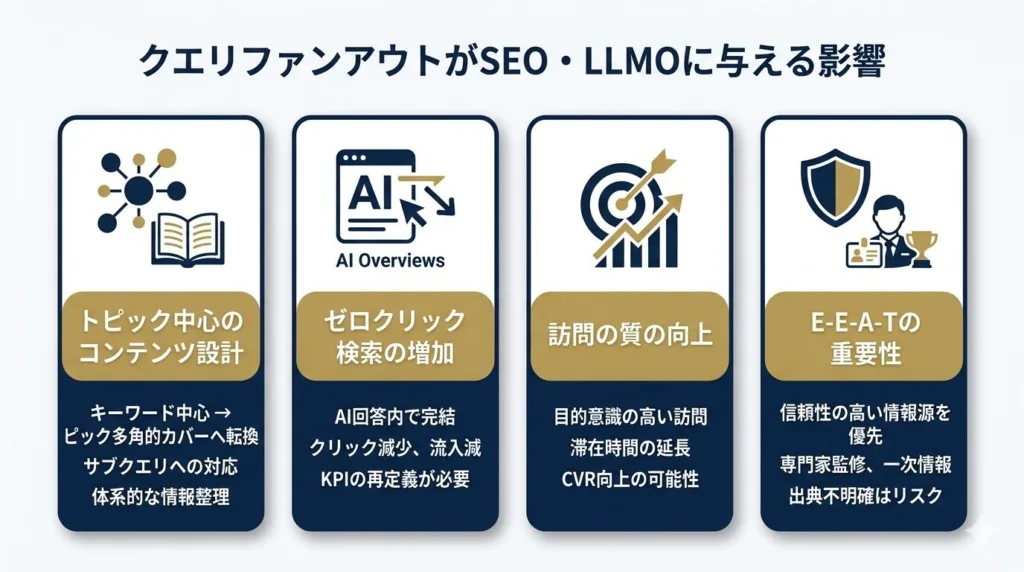
クエリファンアウトの登場は、SEOとLLMOの両面にさまざまな影響を及ぼしています。ここでは実務に直結する4つの変化を整理します。
トピック中心のコンテンツ設計が求められる
クエリファンアウトにより、AIは1つの検索から複数のサブクエリを展開して情報を収集します。この仕組みのもとでは、単一キーワードに最適化した記事よりも、あるトピックを多角的にカバーしたコンテンツのほうがサブクエリに対応しやすくなります。
たとえば「LLMOとは」だけを短く説明したページよりも、LLMOの定義・SEOとの違い・具体的な対策手順・効果測定の方法までを関連ページ群で体系的に整理したサイトのほうが、複数のサブクエリに対応できます。これは「キーワード中心」から「トピック中心」への設計転換を意味しており、SEO・LLMOの双方で重要な変化です。
ゼロクリック検索の増加と流入構造の変化
クエリファンアウトを搭載したAI OverviewsやAIモードでは、従来なら追加検索や記事クリックが必要だった情報もAIの回答内で完結するケースが増えています。これにより、いわゆる「ゼロクリック検索」が拡大しています。
検索結果ページ上でユーザーのニーズが満たされるため、Webサイトへのクリックが発生しにくくなるのです。特に情報収集型のクエリでは、AI回答の充実度が高いほど流入減の影響が大きくなります。サイト運営者にとっては、自然検索からの流入数だけをKPIにする従来の考え方を見直す必要があるでしょう。
クリック数より「訪問の質」が重要になる可能性
一方で、AIの回答を見た上であえてサイトを訪問するユーザーは、より目的意識の高い訪問になる可能性があります。Googleの公式ドキュメントでも、AI Overviewsを経由したクリックについて「ユーザーがサイトに長く滞在する傾向がある」と言及されています。
基本的な情報はAIが回答済みの状態でサイトに来るため、訪問者は「より詳しい専門情報が欲しい」「具体的なサービスを検討したい」「実際に行動に移したい」といった、一歩進んだ意図を持っていることが考えられます。そのため、サイトによっては滞在時間やコンバージョン率(CVR)などの質的指標に改善が見られることもあるでしょう。流入「量」の減少を悲観するだけでなく、流入「質」の変化にも注目する視点が重要です。
E-E-A-Tの重要性がさらに高まる
クエリファンアウトでは、サブクエリごとにAIが「どの情報源を優先的に参照するか」を判断します。その際に重要な判断材料になると考えられているのがE-E-A-T(経験・専門性・権威性・信頼性)です。
複数の情報源から同様の情報が見つかった場合、AIはより信頼性の高いソースを優先して回答に組み込む傾向があるとされています。そのため、専門家の監修や著者情報の明示、一次情報に基づく記述、出典の記載といったE-E-A-Tを高める取り組みは、クエリファンアウト時代のSEO・LLMOにおいてこれまで以上に効果を発揮するでしょう。逆に、出典が不明確な情報や、信頼性を裏付ける要素がないコンテンツは、AIの参照対象から外れやすくなるリスクがあります。
下記の記事も合わせてご覧ください。
E-E-A-Tとは?Googleが重視する4つの評価基準と具体的な強化方法を徹底解説
クエリファンアウトで拾われやすいページの特徴
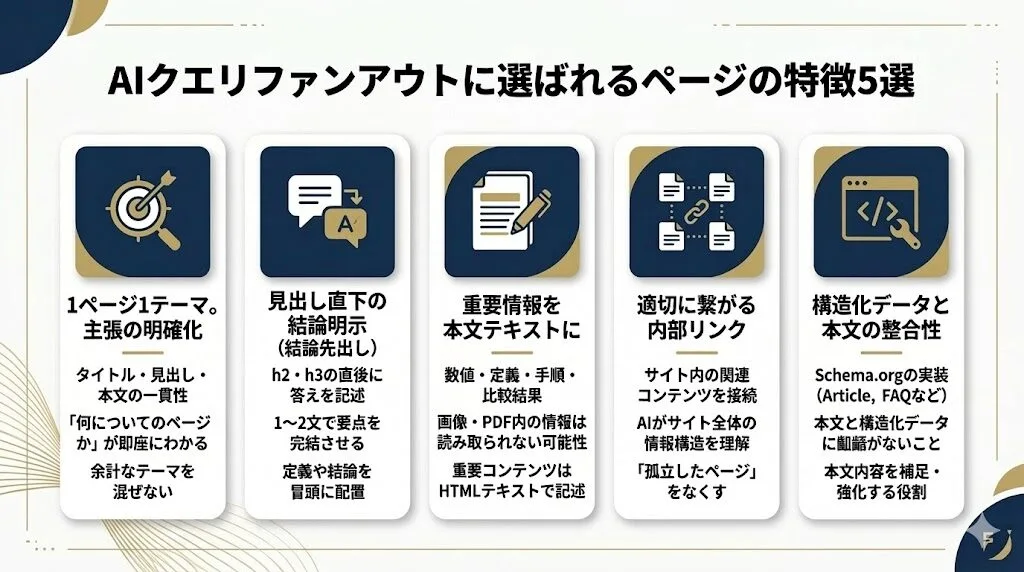
クエリファンアウトでAIに参照されやすいページにはいくつかの共通点があります。ここでは5つの特徴を解説します。
1ページ1テーマで主張が明確になっている
AIがサブクエリごとに情報を抽出する際、ページのテーマが明確であるほど「このページは何について書いているか」の判定精度が高まります。1つのページに複数の無関係なテーマが混在していると、どのサブクエリにも中途半端にしか対応できず、結果として参照されにくくなります。
拾われやすいページは、タイトル・見出し・本文が一貫して同じテーマについて述べており、各セクションの主張が明確です。ページ冒頭で「このページでは何を解説するか」が端的に示されていることも、AIの理解を助ける要因になります。
各見出しの直下で結論が明示されている
AIにとって情報を抽出しやすいページに共通するもう1つの特徴は、各見出し(h2・h3)の直下に結論や要点が明示されていることです。最初の1〜2文で問いに対する答えが完結していると、ユーザーにもAIにも理解されやすくなります。
具体的には、「○○とは、△△のことです」のように定義や結論を冒頭で端的に述べ、続く段落でその根拠や詳細を展開する構成が効果的です。Google Search Centralでも、重要コンテンツをアクセシブルなHTMLテキストとして見せることの重要性が案内されており、「結論先出し」はこの方針にも合致します。
重要情報が本文テキストで明示されている
LLMが情報を抽出する対象は、主にHTMLの本文テキストです。画像内の文字、PDFに埋め込まれた表、JavaScriptで動的に生成されるコンテンツなどは、AIが正確に読み取れないケースがあります。
そのため、数値・定義・手順・比較結果といった重要な情報は、必ず本文のテキストとして記述しておくことが重要です。画像や図表を使う場合も、その内容を本文中に要約として併記しておくと、AIが情報を取得しやすくなります。
関連ページ同士が内部リンクでつながっている
クエリファンアウトでは、サブクエリごとに異なるページが参照される可能性があります。このとき、サイト内の関連ページが内部リンクで適切に接続されていると、AIがサイト全体の情報構造を理解しやすくなります。
たとえば「LLMOの定義」を解説するページから「LLMO対策の具体的手順」のページへリンクされていれば、LLMはこれらのページが同一テーマの関連コンテンツであると認識しやすくなります。孤立したページよりも、文脈的なつながりを持つページ群のほうが、複数のサブクエリに対してサイト全体で対応できる構造になります。
構造化データが本文の内容と整合している
構造化データ(Schema.org)は、ページの内容を機械的に読み取りやすい形式でGoogleに伝えるための仕組みです。Article、FAQPage、HowToなどのスキーマを適切に実装することで、AIがページの内容や構造をより正確に把握できるようになります。
ただし、構造化データと本文の内容に齟齬がある場合、逆にAIの評価を下げるリスクがあります。たとえばFAQスキーマに記載した質問と回答が本文中に存在しない、あるいは本文の記述と構造化データの内容が矛盾しているといった状態は避けなければなりません。構造化データはあくまで本文の内容を補足・強化するものであり、実態と整合していることが前提です。
クエリファンアウトを踏まえて見直したいSEO・LLMOの実務5施策
前章で解説した「拾われやすいページの特徴」を踏まえ、実務レベルで着手できる5つの施策を紹介します。まず全体像を表で整理し、各施策の詳細を解説します。
| 施策 | 目的 | 実務でやること |
|---|---|---|
| トピッククラスター設計 | サブクエリ網羅性を高める | ピラー記事と関連ページ群を設計する |
| 1ページ1論点 | 情報の焦点を明確にする | タイトル・見出し・冒頭文で主張を揃える |
| 内部リンク最適化 | ページ間の文脈を伝える | 関連記事を具体的なアンカーテキストで接続する |
| E-E-A-T・エンティティ整備 | 信頼される情報源になる | 著者情報、会社情報、実績、外部言及を整備する |
| 構造化データ整合 | 機械可読性を高める | 本文と一致したschemaを実装・保守する |
トピッククラスター設計でサブクエリに網羅的に対応する
トピッククラスターとは、中心テーマを扱うピラーページと、関連するサブトピックを個別に深掘りするクラスターページで構成するコンテンツ設計手法です。クエリファンアウトでは複数のサブクエリが同時に生成されるため、サイト内にサブクエリに対応するページ群が用意されていると、複数のサブクエリに対して自社サイトが参照候補に入りやすくなります。
実務では、まず自社の主要テーマについて想定されるサブクエリをリストアップし、それぞれに対応するクラスターページを計画します。すべてを1つのページに詰め込むのではなく、テーマを適切に分割してページごとの焦点を明確にすることがポイントです。
1ページ1論点で情報の焦点を絞る
トピッククラスターの各ページは、1ページ1論点に絞ることが効果的です。AIが情報を抽出する際、1つのページで多くの論点を浅く扱うよりも、特定の論点を深く掘り下げたページのほうが、該当するサブクエリに対して強い対応力を持ちます。
具体的には、ページタイトルとh2見出しで「このページは何について書いているか」を明示し、本文の冒頭で結論や要点を端的に述べます。続く段落でその根拠や詳細を展開する構成にすると、AIが抽出しやすい情報が自然に生まれます。
内部リンクで関連コンテンツの文脈を接続する
クラスターページ同士、およびピラーページとクラスターページの間を内部リンクで接続することで、サイト内のテーマの文脈をAIに伝えやすくなります。リンクを設置する際は、アンカーテキスト(リンクの表示文字列)にリンク先のテーマを具体的に含めることが重要です。
「詳しくはこちら」のような汎用的な表現ではなく、「LLMOの効果測定方法はこちらで解説しています」のように、リンク先の内容がわかるアンカーテキストを使うことで、AIとユーザーの両方にとってページ間の関係性が明確になります。
E-E-A-Tとエンティティ情報を整備する
E-E-A-Tを実務で高めるためには、記事への著者情報・監修者情報の記載、著者の専門性や経歴を示すプロフィールページの整備、企業情報・実績ページとの内部リンク接続が有効です。
加えて、自社や自社サービスの「エンティティ情報」を整理することも重要です。エンティティとは、検索エンジンやLLMが認識する固有の概念(企業名、サービス名、人名など)を指します。公式サイトにおける企業情報の充実、構造化データ(Organization、Personスキーマ)の実装、外部メディアでの言及やサイテーションの獲得により、AIが自社を正しく認識・評価する基盤を構築できます。
▼参考記事
エンティティとは?LLMOで欠かせない基礎知識と今すぐ始める4つの最適化戦略
構造化データと本文テキストの整合性を確認する
構造化データの実装においてまず確認すべきは、本文の内容と構造化データの記述が一致しているかどうかです。Googleは構造化データのガイドラインで「マークアップは、ユーザーに表示されるコンテンツを反映している必要がある」と明記しています。
実務では、Article・FAQPage・HowToなど、自社コンテンツの形式に適したスキーマを選択し、本文中に実際に記載されている情報のみを構造化データに反映します。定期的にGoogleのリッチリザルトテストやSchema Markup Validatorでエラーがないかを確認し、本文の更新時には構造化データも合わせて更新する運用ルールを設けておくと整合性を維持しやすくなります。
▼参考記事
【初心者向け】構造化データとは?メリットやSEO・LLMOへの効果と実装手順を解説
クエリファンアウト対策で誤解されやすいポイント
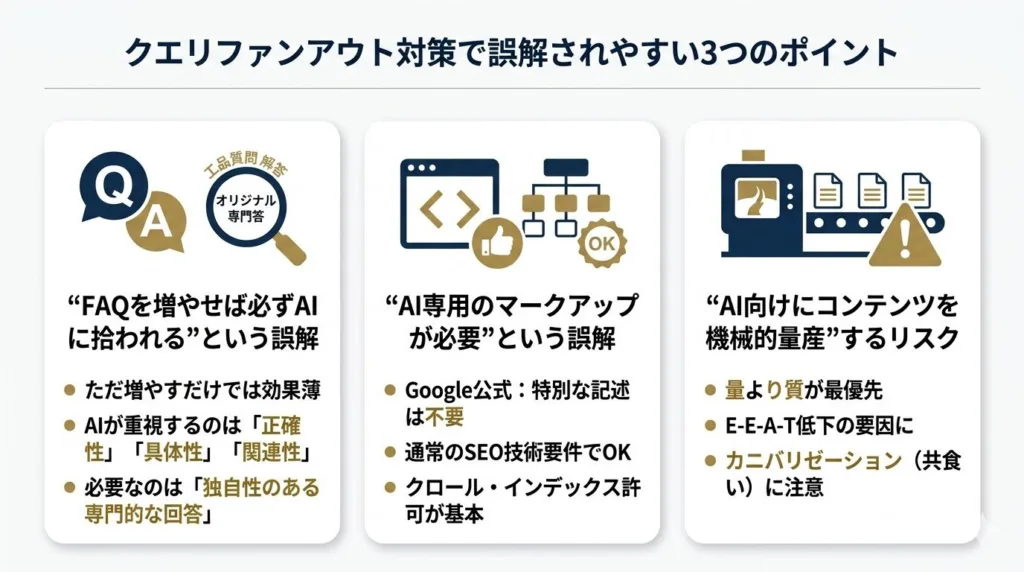
クエリファンアウトへの対策を進める際、よくある誤解が3つあります。間違った方向に労力を使わないよう、正しく理解しておきましょう。
FAQを増やせば必ずAIに拾われるわけではない
「FAQ形式のコンテンツはAIに拾われやすい」という情報から、とにかくFAQセクションを量産すれば良いと考えるケースがあります。しかし、FAQの数を増やすだけでAIに引用されるわけではありません。
AIが情報を抽出する際に重視するのは、回答の正確性・具体性・テーマとの関連性です。形式的にQ&Aの体裁を取っていても、内容が薄い一般論や他サイトの焼き直しであれば、サブクエリへの対応力は低いままです。FAQを設置する場合は、自社の専門知識や実体験に基づいた独自性のある回答を用意し、そのFAQが記事全体のテーマと整合していることが前提になります。
特別なAI向けマークアップは不要とGoogleが明言している
「AI検索に表示されるためには、AI専用の特別なマークアップやファイルが必要」という誤解も見受けられます。この点について、GoogleはSearch Centralの公式ドキュメントで明確に否定しています。
Googleの公式ドキュメントでは「新しい機械可読ファイルやAI用テキストファイル、特別なマークアップを作成する必要はない」「追加すべき特別なschema.org構造化データもない」と記載されています。AI OverviewsやAIモードに表示されるための要件は、通常のGoogle検索に表示されるための技術要件と同じです。クロールが許可されていること、インデックス可能であること、スニペット表示が許可されていることが基本条件であり、それ以上のAI固有の対策は不要です。
AI向けにコンテンツを機械的量産すると逆効果になる
クエリファンアウトがサブクエリごとに情報を収集するという仕組みを知ると、「サブクエリに対応するページを大量に作ればいい」と考えがちです。しかし、機械的にコンテンツを量産するアプローチは逆効果になるリスクがあります。
Googleは検索におけるAI生成コンテンツについて、「作り方」ではなく「有用性」が重要であるという立場を示しています。AIツールで大量生成した薄いコンテンツは、E-E-A-Tの評価を下げる要因になりえます。また、同じテーマについて類似の内容を複数ページに分散させると、サイト内でのカニバリゼーション(共食い)が発生し、どのページもサブクエリに対する対応力が中途半端になってしまいます。量より質を優先し、各ページが明確な固有の論点を持つ状態を維持することが重要です。
参照:Google Search Central Blog「Google Search’s guidance about AI-generated content」
クエリファンアウトを前提にしたSEO・LLMOの効果測定
クエリファンアウト時代の効果測定では、従来の順位・クリック数に加えて新しい指標の活用が求められます。ここでは3つの測定アプローチを解説します。
Search Consoleの「Web」検索タイプで全体傾向を把握する
GoogleはSearch Centralの公式ドキュメントで、AI Overviews・AIモードからのトラフィックがSearch Consoleのパフォーマンスレポートにおいて「Web」検索タイプに含まれる形で報告されることを明記しています。現時点ではAI経由のクリックだけを分離して確認する機能は提供されていませんが、「Web」検索タイプの全体傾向をモニタリングすることで、AI検索の影響を含めたトラフィック変化を把握できます。
特に注目すべきは、表示回数とクリック数の推移、そしてクリック率(CTR)の変化です。AI Overviewsの拡大に伴い表示回数が増加する一方でCTRが低下する傾向が見られた場合、ゼロクリック検索の影響を受けている可能性があります。こうした傾向の早期発見が、施策の見直し判断に役立ちます。
順位だけでなく滞在時間・CV・回遊を重視する
AI経由での流入では、従来よりも目的意識の高い訪問が増える可能性があります。そのため、検索順位やクリック数だけでなく、Google Analyticsなどで滞在時間、コンバージョン率(CVR)、サイト内の回遊行動を測定することが重要です。
クエリファンアウト時代のKPIとしては、流入数の増減だけでなく「流入あたりのコンバージョン数」や「ページ/セッション」「エンゲージメント率」といった質的な指標を組み合わせて評価することが効果的です。流入量が減少しても、CVRや滞在時間が向上していれば、AI検索時代に適応できている兆候と捉えることができるでしょう。
指名検索外の複合クエリの増減をモニタリングする
クエリファンアウトの影響を間接的に測定するもう1つの手段は、Search Consoleで「指名検索(ブランド名を含む検索)」以外の複合クエリ(2語以上の検索語句)の動向を追うことです。
AIがサブクエリを生成する際、従来のユーザー検索では使われにくかった複合的・具体的なクエリが発生します。こうしたサブクエリに自社ページが対応できていれば、今まで表示されなかったロングテールの検索語句でインプレッションが発生し始めるケースがあります。Search Consoleの検索パフォーマンスレポートで「クエリ」フィルターを活用し、新たに表示回数が増加している複合クエリを定期的に確認しましょう。これらのクエリは、クエリファンアウトによるサブクエリとの一致を示す手がかりになります。
LLMO対策の効果測定については下記の記事も合わせてご覧ください。
LLMOの効果測定とは?追うべき5つのKPI・GA4での計測方法・改善の進め方を解説
まとめ:クエリファンアウトとLLMOの理解がAI検索時代の基盤になる
クエリファンアウトとは、ユーザーの1つの質問をAIが複数のサブクエリに分解し、並列に検索・統合して回答を生成する技術です。GoogleはAI OverviewsとAIモードの両方でこの仕組みを採用しており、検索エンジンの情報取得構造は大きく変化しています。この変化に対応するためには、従来のキーワード単位のSEOだけでなく、トピック中心のコンテンツ設計、情報単位で参照されることを意識した構造の整備が欠かせません。LLMO(大規模言語モデル最適化)は、こうしたAI検索時代に自社の情報がLLMに正しく参照される状態をつくるための施策であり、クエリファンアウトの仕組みを理解することがその出発点になります。特別なAI向けの技術は不要であり、質の高いコンテンツ、E-E-A-Tの充実、構造化データの整備といった基本の徹底こそが、AI検索時代においてもっとも効果的な対策です。
【SEO・LLMO対策でお困りではないですか?】
株式会社アドカルはSEO対策・LLMO対策に強みを持った企業です。
貴社のパートナーとして、少数精鋭で担当させていただくので、
「LLMO対策について詳しく知りたい」
「現状のSEO対策で成果が出ていない」
「LLMO対策でAI検索からの集客を強化したい」
とお悩みの方は、ぜひ弊社にご相談ください。
貴社のご相談内容に合わせて、最適なご提案をさせていただきます。
サービスの詳細は下記からご確認ください。無料相談も可能です。

