
ChatGPTに引用されるLLMO対策とは?Bing対策・効果測定まで解説
この記事でわかること
- ChatGPTのLLMO対策の定義と引用・言及・推薦のKPI設計
- OAI-SearchBot・GPTBot・ChatGPT-UserとBingの違い
- 引用されやすい状態を作る実務7ステップ
- GA4とShare of Modelによる効果測定の方法


「ChatGPTで自社が引用されないのはなぜか」「Google SEOは整えているのに、AI回答内ではまったく言及されない」――こうした課題を相談するWeb担当者・マーケターは増えています。生成AIを検索手段として使うユーザーは2026年2月時点で37.0%に達し、ChatGPTは検索行動で利用される生成AIサービスのなかでも最多の利用率を維持しています。AI回答内で自社がどう扱われるかは、もはやブランド可視性とビジネス成果に直結する経営課題です。
本記事では、ChatGPTに特化したLLMO(Large Language Model Optimization)対策を、OpenAIの公式仕様・国内外の一次情報・最新研究、そして株式会社アドカルのLLMO診断で得られた実務知見をもとに体系的に解説します。クローラーの違い、Bingでの発見性、引用されやすい記事構成、誤解されやすい点、そしてShare of Modelによる効果測定まで、実務でそのまま使える内容に絞ってお伝えします。
ChatGPTのLLMO対策で重要なポイントは次の5つです。
- OAI-SearchBot(ChatGPT Searchなどの検索用クローラー)をブロックせず、ChatGPT Searchの引用候補に入る前提条件を整える
- Bing Webmaster Toolsでインデックス状況を確認し、ChatGPTが参照しやすい検索基盤上での発見性を高める
- 見出し直下に40〜80字程度の直接回答を置き、AIが引用しやすい文章構造にする
- 統計・出典・一次情報・著者監修者情報を明示し、AIが検証しやすい信頼シグナルを増やす
- GA4のchatgpt.com流入と主要プロンプトでの引用率・言及率を定点観測する
目次
ChatGPTのLLMO対策とは?AI回答内で引用・言及・推薦される状態を作る最適化
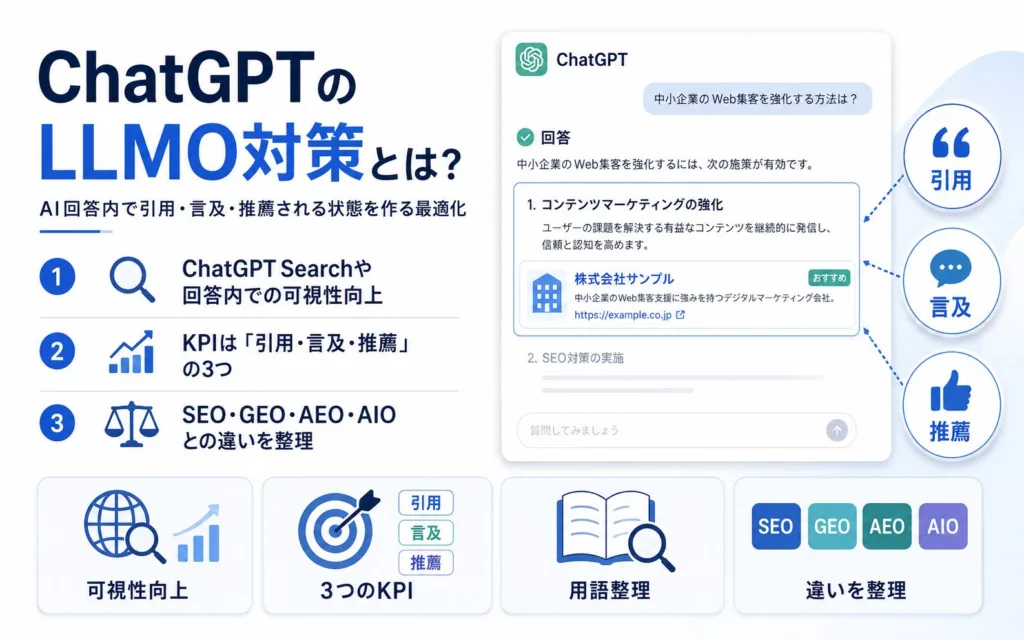
ChatGPTのLLMO対策とは、ChatGPT SearchやChatGPTの回答内で、自社サイト・自社ブランド・自社サービスが正しく引用・言及・推薦される状態を作るための最適化施策の総称です。本セクションでは、LLMO対策の定義、3つのKPIの考え方、関連用語との違いを順に整理します。
ChatGPTのLLMO対策の定義と目的
ChatGPTのLLMO対策とは、ChatGPTの回答画面で自社の名前やURLが「正しく・好意的に・繰り返し」現れる状態を作るための、コンテンツ設計と技術設定の組み合わせです。従来のSEOがGoogle検索結果の上位表示を目的にしていたのに対し、LLMO対策が目指すのは「AI回答内に居場所を持つこと」です。
従来のSEOでは、検索結果の1ページ目に入ることが第一目標でした。一方、ChatGPTのLLMO対策では、ユーザーが検索エンジンを開かずChatGPT上で疑問を解消する場面が増えているため、青いリンクの順位ではなく「AIが回答を組み立てる際に自社をどう扱うか」が成果指標になります。具体的には、ChatGPTが回答に含める出典リンク、本文中で言及するブランド名、比較・おすすめ候補として提示するサービス名のすべてが対象になります。
目的は3層で整理すると分かりやすくなります。第一に、AI回答内で自社が「正しく」表現されること(誤情報や古い情報を回避する)。第二に、競合と並んで「公平に」言及されること(比較・推薦の場で候補に上がる)。第三に、ユーザーがその回答経由で自社サイトを訪問したり、自社サービスを選んだりするまでつながること(ビジネス成果へ寄与する)です。この3層を意識すると、施策が「引用されるためのテクニック」だけに偏らず、ブランド全体の整合性を高める方向に向かいます。
本記事はChatGPTに特化した解説のため、LLMOそのものの全体像から押さえたい場合は、関連記事の「LLMOとは」もあわせて確認してください。
「引用・言及・推薦」の3つに分けて考えるKPI設計
ChatGPTのLLMO対策では、AI回答内での扱われ方を「引用・言及・推薦」の3つに分けてKPIを設計するのが実務的です。同じ「AIに出てくる」でも、出典として表示されるのか、文章内でブランド名だけ言及されるのか、おすすめとして提示されるのかで、必要な施策と価値が変わるためです。
| 分類 | 目的 | 主な施策の方向性 |
|---|---|---|
| 引用される | 自社URLが出典として表示される | クロール許可・Bingでの発見性・直接回答型の構成 |
| 言及される | 自社名・サービス名が回答内に現れる | 第三者メディア掲載・PR・比較記事内露出 |
| 推薦される | 比較・おすすめ候補として提示される | レビュー・実績・専門性訴求・独自データ |
引用は技術的な土台が整っていれば獲得しやすい一方、推薦は外部評価や独自データに大きく依存します。アドカルのLLMO診断でも、まず「引用・言及・推薦」のどの段階で詰まっているかを切り分けてから、足りない要素を優先的に補強するアプローチを取っています。各KPIの具体的な測定方法は本記事後半の効果測定セクションで詳しく扱います。
SEO・GEO・AEO・AIOとの違いと使い分け
LLMOと近接する用語にGEO・AEO・AIOがありますが、業界での用語定義はまだ統一されておらず、本質的に重なり合う概念として理解するのが現実的です。厳密な線引きよりも、施策の目的を明確にする方が重要になります。
SEO(Search Engine Optimization)は検索エンジンの順位最適化、GEO(Generative Engine Optimization)は生成AI全般の回答内最適化、AEO(Answer Engine Optimization)は回答エンジン全般、AIO(AI Optimization)はAI最適化の総称として使われる傾向があります。LLMOは特にLLM(大規模言語モデル)の回答内最適化を指す呼称で、ChatGPTやClaudeなどLLMベースのチャットサービスに対する施策と捉えられることが多くなっています。
用語の違いをさらに詳しく整理したい場合は、「LLMO・AIO・GEOの違い」を解説した記事も参考になります。本記事ではChatGPTに焦点を当てるため、引用・言及・推薦の3つを獲得するための施策をLLMO対策と呼んで整理していきます。

【SEO・LLMO対策でお困りではないですか?】
株式会社アドカルは主に生成AIを活用したデジタルマーケティング支援やマーケティングDXに強みを持った企業です。
貴社のパートナーとして、少数精鋭で担当させていただくので、
「LLMO対策について詳しく知りたい」
「現状のSEO対策で成果が出ていない」
「LLMO対策でAI検索からの集客を強化したい」
とお悩みの方は、ぜひ弊社にご相談ください。
貴社のご相談内容に合わせて、最適なご提案をさせていただきます。
サービスの詳細は下記からご確認ください。無料相談も可能です。
なぜ今ChatGPTのLLMO対策が必要なのか

生成AIを検索の代わりに使うユーザーは全世代で拡大しており、ChatGPTは検索行動で使われる生成AIサービスの中でサービス別利用率が最多です。AI回答が比較・購買にまで影響し始めている今、ChatGPT内での可視性は無視できない経営課題となっています。本セクションでは、最新データをもとに対策の必要性を整理します。
検索行動で生成AIを使うユーザーが拡大している
検索行動の場面で生成AIを利用するユーザーは、過去9か月で2倍近くに伸長し、もはや一部の層だけの動きではなくなっています。検索エンジンを開く前にChatGPTに質問する行動が、全世代に広がりつつあります。
サイバーエージェントGEOラボが2026年2月に実施した「生成AIのユーザー利用実態調査 第三弾」(10代〜60代の男女9,278名対象、2026年3月公表)によると、検索手段として生成AIを利用するユーザーは37.0%に達しました。2025年10月の前回調査(31.1%)から5.9ポイント、2025年5月の第一弾調査(21.3%)からは約9か月で15.7ポイントの上昇です。同調査では、特に50代(+7.7pt)、40代(+6.7pt)、20代(+6.6pt)の伸びが大きく、若年層だけの現象ではなく、全世代に普及が進んでいることが示されています。
この変化は、企業のWeb流入の経路そのものが変わりつつあることを意味します。検索エンジン経由の流入だけを最適化する従来型の発想では、3人に1人以上が利用する新しい情報接点を取りこぼすことになります。
ChatGPTが生成AI検索の主要利用先となっている
生成AIを使った検索行動において、ChatGPTは主要な利用先の一つであり、サービス別利用率では最多となっています。LLMO対策を進めるうえで、まずChatGPTを優先的に押さえる合理性がここにあります。
サイバーエージェントGEOラボの第三弾調査では、検索行動で利用する生成AIサービスの内訳としてChatGPTが29.1%、Google検索のAIモードが21.0%、Geminiが15.6%と報告されています。Google AIモードはGemini単体とは性質が異なる「Google検索内に組み込まれたAI機能」ですが、生成AIサービス単体としてはChatGPTがサービス別の最多利用率を維持しています。さらに第一弾調査では、検索行動で生成AIを使うユーザーのうちChatGPTを使う割合が77.6%と圧倒的なシェアを占めていることも示されていました。サービス全体に対する利用率(29.1%)と、生成AI利用者のうちChatGPTを選ぶ割合(77.6%)は分母が異なる別の数字ですが、いずれの切り口でもChatGPTが軸になっていることに変わりはありません。
つまりLLMO対策を始める際、ChatGPTを最初の対象に据えるのは、ユーザー接点の最大化という観点で投資対効果が高い選択になります。Google検索内のAI体験への対応については、「Google AI Mode対策」の記事で別途詳しく解説しています。Gemini・Perplexity・Claudeなど他のAIへの対応も含め、ChatGPTで土台を固めた後に横展開していくのが現実的です。
AI回答が比較・購買行動に影響しはじめている
AI回答はもはや「情報を読むだけの場」ではなく、ユーザーの比較・購買行動に直接影響を与える接点になりつつあります。LLMO対策が単なる流入施策ではなく、売上に直結する施策であると位置づけられる根拠です。
同じ第三弾調査では、AI回答上に表示されるURLをクリックすることが「よくある」「時々ある」と答えたユーザーが54.4%、AIにおすすめされた商品・サービスを自分でさらに詳しく検索するユーザーが69.0%、そしてAIにおすすめされたことをきっかけに実際に商品・サービスを購入・利用した経験があるユーザーが47.5%に達しました。約半数が「AIの推薦をきっかけに購買・利用」を経験している事実は、AI回答内での扱われ方がそのまま顧客獲得に跳ね返ることを示しています。
とくにB2BやSaaSのような比較検討期間が長い領域では、検討の初期段階でChatGPTに「候補リスト」を尋ねるユーザーの行動が増えています。ここで候補に挙がるかどうかが、商談フェーズに進む前段で勝負を分けることになります。
従来SEOだけではAI回答内の可視性を測れない
従来のSEO指標(順位・自然検索流入)だけを追っていると、ChatGPT内で自社がどう扱われているかは見えません。Google上位表示とChatGPT引用は、別の測定軸として並行管理する必要があります。
順位ツールはGoogleのSERPを定点観測しますが、ChatGPTの回答内容はユーザー・タイミング・モデル・コンテキストによって変動し、同じプロンプトでも回答が完全一致しないことが知られています。さらに、後述のとおりChatGPT Searchで引用されるページはBingの上位結果と重なりやすい傾向が示唆されており、Googleでの順位がそのままChatGPT引用率に直結するわけではありません。実際に、Googleで1位を取っていてもChatGPT回答内では言及されない事例、逆にGoogle検索では2ページ目以降のページがChatGPTでは引用される事例も観測されています。
このギャップを埋めるための新しい指標が、本記事後半で扱う「Share of Model」です。Share of Modelは、自社が想定する代表プロンプト群に対して、AI回答内で自社が引用・言及・推薦される割合を競合と比較する指標で、ChatGPT特化のKPIとして従来SEO指標と並行運用する価値があります。
ChatGPTのLLMO対策で押さえるべきAI引用の仕組み

ChatGPTの回答は、学習済み知識とリアルタイム検索の組み合わせで生成されています。LLMO対策で何が効くかを判断するには、OpenAIのクローラー仕様と、ChatGPT Searchで参照されやすいBingとの関係を理解する必要があります。本セクションでは、技術仕様のレイヤーで仕組みを整理します。
ChatGPTの回答は学習済み知識と検索結果の組み合わせで生成される
ChatGPTの回答は大きく2つの情報源を組み合わせて生成されます。1つはモデルが事前学習で吸収した知識(パラメトリック知識)、もう1つはChatGPT Search機能が実行時に取得するWeb検索結果です。LLMO対策では両方を意識する必要があります。
パラメトリック知識は、モデル学習時点までの公開情報から構築されています。自社が業界メディア・Wikipedia・大手ニュースサイトなどで長期にわたって言及されてきた実績は、この層に蓄積されます。一方、ChatGPT Searchが動作する場面(最新情報を要するクエリ、ChatGPT Search有効時のセッションなど)では、AIがリアルタイムでWebを検索し、その結果から回答を組み立てます。後者で重要になるのが、後述するOAI-SearchBotとBing周辺の発見性です。
この二層構造は、施策の時間軸にも影響します。パラメトリック知識への働きかけ(外部メディア露出、PR、第三者言及)は効果が出るまでに時間がかかる一方、ChatGPT Search層への対応(クローラー許可、Bingでの発見性、構成最適化)は比較的短期で改善が反映される傾向があります。両方を並行して進めるのが基本戦略です。
OAI-SearchBot・GPTBot・ChatGPT-Userの役割の違い
OpenAIは3つの異なるクローラー/ユーザーエージェントを公開しており、それぞれ役割が違います。役割を混同してrobots.txtを誤って設定すると、ChatGPT Search経由の引用機会を意図せず失うリスクがあります。
OpenAI公式ドキュメントによると、3つのクローラーは次のように整理されます。
| クローラー / UA | 役割 | LLMO上の意味 |
|---|---|---|
| OAI-SearchBot | ChatGPT Search用 | ChatGPT Searchの表示・引用候補になる前提として許可が重要 |
| GPTBot | 生成AIモデルの学習用 | 許可しても即引用されるわけではない |
| ChatGPT-User | ユーザー操作起点のアクセス(Custom GPT、GPT Actionsなど) | 自動巡回ではなく、Search表示判定には使われない |
つまり、ChatGPT Searchで引用される可能性を残したい場合は、OAI-SearchBotを許可することが前提条件になります(許可は必要条件であり、引用そのものは保証されません)。学習に使われたくない場合は、GPTBotだけを個別に拒否することで、検索引用候補としての地位は維持しつつ学習だけを拒否する設定が可能です。OpenAI公式FAQでも、3つのエージェントを独立して制御できる旨が明記されています。また、両方を許可した場合、OpenAIはクロール結果を共有利用することで重複取得を避ける旨も最近のドキュメント更新で示されています。
なお、OpenAI以外にも、ClaudeBot・PerplexityBot・Google-Extendedなど、AIサービスごとに異なるクローラーや制御方法があります。主要AIクローラーの種類や、robots.txtでブロック・許可を分ける具体的な考え方は、AIクローラーとは?種類一覧・ブロック方法・LLMO対策まで解説で詳しく解説しています。
BingインデックスとChatGPT Searchの関係
ChatGPT Searchの引用元は、Bingの上位オーガニック結果と重なりやすい傾向が外部調査で示されています。そのため、ChatGPTのLLMO対策では、GoogleだけでなくBingでのインデックス状況や上位表示状況も確認することが重要です。
米Seer Interactiveが500件以上の引用を分析した調査では、SearchGPTで引用されたページの87%以上が、同じクエリでBingの上位オーガニック結果と一致したことが報告されています。一方、Google検索結果との一致率は56%にとどまり、相関の強さに差があったとされています。OpenAIとMicrosoftの提携関係を背景に、ChatGPT Searchの参照情報源にBingが大きく関与している可能性が示唆される結果です。
ただし、これはあくまで外部調査による相関であり、OpenAIが公式に「ChatGPT SearchはBingインデックスのみを参照する」と説明しているわけではありません。また、Seer Interactiveの分析でも、引用元はBing上位だけでなく、アフィリエイトサイト・アグリゲーター・ニュースメディア・Wikipediaなど多様な情報源にまたがっていました。LLMO対策では、Bingでの発見性・上位表示状況の把握を基本動作としつつ、外部メディア露出やコンテンツ品質といった他の要素も並行して整える発想が必要です。
ChatGPTに引用されやすいページの共通点
ChatGPTで実際に引用されているページには、いくつかの共通要素があります。技術・発見性・抽出しやすさ・信頼性・外部評価・鮮度・一貫性の7つの軸で整理すると、自社サイトの足りない要素が見えてきます。
| 要素 | 内容 |
|---|---|
| クロール可能性 | OAI-SearchBotを許可、noindex未設定、robots.txt適切、CDN/WAFでブロックしていない |
| 発見性 | Bingインデックスへの登録、サイトマップ送信、内部リンクの整備 |
| 抽出しやすさ | 見出し直下の直接回答、表、FAQ、短い段落、セマンティックHTML |
| 信頼性 | 出典明示、統計・一次データ、著者情報、監修者、会社情報 |
| 外部評価 | 第三者メディアでの言及、比較記事掲載、PR、SNS言及 |
| 鮮度 | 更新日の明示、最新情報への追従、過去記事の継続更新 |
| 一貫性 | 会社名・サービス名・強みの表現が複数チャネルで揃っている |
これらの要素は単独で機能するというより、相互に補完し合うことで効果を発揮する傾向があります。アドカルでLLMO診断を行う際も、まずは「技術的に拾われる状態か」「AI回答内で言及される外部評価があるか」「主要プロンプトで競合と比べてどの位置に出るか」の3点を分けて確認しています。技術設定が完璧でも外部からの言及がなければ「言及される」「推薦される」KPIは伸び悩み、逆にコンテンツ品質が高くてもクロール可能性が確保されていなければ前提から崩れます。次のセクションでは、この7要素を具体的なアクションに落とし込んだ7つの手順を解説します。
ChatGPTのLLMO対策で実践すべき7つの手順

ChatGPTのLLMO対策は、技術設定からコンテンツ改善、外部評価獲得、効果測定まで一気通貫で進めるのが効果的です。本セクションでは、まず「引用されない原因」を切り分けるためのチェック表を提示し、その後で実務でそのまま使える7ステップを手順ごとのチェックリストとあわせて解説します。
まずは確認したい:ChatGPTで自社サイトが引用されない主な原因
施策を一気に走らせる前に、まず「自社サイトがChatGPTに拾われない原因がどこにあるか」を切り分けると、無駄な対策を回避できます。アドカルのLLMO診断でも、最初に以下の7軸でつまずきポイントを洗い出します。
| 原因 | 確認方法 |
|---|---|
| OAI-SearchBotをブロックしている | robots.txt、WAF、CDN設定を確認 |
| Bingにインデックスされていない | Bing Webmaster Toolsで確認 |
| ページ本文がJavaScript依存 | HTMLソース・レンダリング状況を確認 |
| 結論がページ下部にある | H2/H3直下の回答文を確認 |
| 出典・統計が少ない | 主張ごとの根拠の有無を確認 |
| 外部言及が少ない | 指名検索数・被リンク・PR掲載状況を確認 |
| 競合比較記事に出ていない | 「おすすめ」「比較」系クエリで第三者記事を確認 |
このうち、上3つ(クロール・インデックス・本文表示)が満たされていないと、その後のコンテンツ改善や外部評価強化の効果がAI回答に反映されにくくなります。診断時はまず技術面のクリアを確認してから、コンテンツと外部評価に進むのが定石です。より網羅的に自社サイトを点検したい場合は、「LLMOチェックリスト」もあわせて活用してください。
手順1:OAI-SearchBotを許可しrobots.txt・noindex・CDN設定を確認する
最初の手順は、ChatGPTのクローラーが自社サイトに正常にアクセスできる状態を作ることです。ここがブロックされていると、後続のコンテンツ施策は効果が出ません。
確認すべき項目は次の通りです。
【手順1のチェック項目】
- robots.txtでOAI-SearchBotをDisallowしていないか
- 主要ページにnoindexメタタグが付与されていないか
- Cloudflare等のCDN・WAFでOpenAI公開IPを弾いていないか
- SSRまたは静的HTMLで本文が表示されているか(JavaScript完全依存になっていないか)
- 404・500エラー・無限リダイレクト等で取得失敗していないか
学習利用は拒否しつつChatGPT Searchへの表示可能性は残したい場合、robots.txtの記述例は次のようになります。
# 学習利用は拒否、ChatGPT Search表示は許可する場合の一例
User-agent: OAI-SearchBot
Allow: /
User-agent: GPTBot
Disallow: /逆に学習にも検索表示にも積極的に活用したい場合は、両方をAllowにします。ポリシーは事業判断ですが、いずれにせよ「意図しないブロック」が最も多いトラブル要因のため、運用開始前にサーバーログでクローラーアクセスを確認するのが堅実です。
手順2:Bing Webmaster Toolsでインデックス状況を整える
次の手順は、ChatGPT Searchで引用されやすい検索基盤として知られるBingに、自社サイトが正しくインデックスされている状態を作ることです。Bingインデックスの確認は、ChatGPT Search対策における優先度の高い確認項目です。
具体的には、Bing Webmaster Toolsにサイトを登録し、サイトマップを送信し、主要ページのインデックス状況を継続的にモニタリングします。Google Search Consoleを使っている企業は多くても、Bing Webmaster Toolsは未整備というケースが少なくありません。LLMO対策の文脈では、Bing側の体制を整えることが第一歩になります。
【手順2のチェック項目】
- Bing Webmaster Toolsにサイトを登録済みか
- サイトマップ(XML)をBingに送信済みか
- 主要ページがBingでインデックスされているか
- 主要キーワードでBingの上位に入っているか
- IndexNow等の即時インデックス送信プロトコルを利用できているか
Bingで発見されないページは、ChatGPT Searchでも引用候補に入りにくい可能性があるため、Bing Webmaster Toolsでの確認は早期に行うべきです。Bing側のSEO(コンテンツ品質、内部リンク、被リンク)も、LLMO対策の一部として捉えるのが現実的です。
特に内部リンクは、クローラーが重要ページを発見しやすくするだけでなく、サイト内のテーマ同士の関係性を伝える役割もあります。設計の基本は、内部リンクの貼り方と改善手順で詳しく解説しています。
手順3:見出し直下に直接回答を置き引用されやすい構成にする
技術的な前提が整ったら、コンテンツの構造を「AIが抽出しやすい形」に整えていきます。AI回答では断片的なテキストが組み合わされて表示されるため、見出し直下に短く明確な回答を置くと、AIが回答文として抽出しやすくなる可能性があります。
海外のGEO関連の実務分析では、AI回答に採用される情報がページ上部に偏る傾向があると指摘されています。厳密なランキング要因として断定はできませんが、重要な結論をページ冒頭に置く設計は、AIにも人間読者にも有効です。本記事自体も、各見出し直下に40〜80字の直接回答を置く形式を採用しています。
【手順3のチェック項目】
- 記事冒頭に結論ボックスを設けているか
- 各H2の冒頭で2〜3文の予告を入れているか
- 各H3の冒頭に40〜80字の直接回答を置いているか
- 結論を後回しにせず、要点を上部に配置しているか
- 表・箇条書き・FAQで抽出しやすい単位に分解しているか
「結論→補足説明→事例」の順序を徹底するだけでも、AI回答に短いセンテンスとして抽出される確率は上がります。一文一義を意識し、主語と述語を明確にしておくことも、抽出のしやすさに直結します。
手順4:統計・出典・一次情報で回答の根拠を強化する
4つ目の手順は、コンテンツに統計・出典・一次データを織り込み、AIが回答根拠として採用しやすい状態を作ることです。一般論だけの記事は、AI回答内では他社の専門コンテンツに上書きされやすくなります。
以下の数値は、特定のベンチマーク・生成エンジン・評価指標に基づく研究結果であり、商用サイト全般にそのまま同じ改善率が出ることを意味しない点に注意してください。Princeton大学・Georgia Tech・IIT Delhi等の研究チームがKDD 2024で発表したGEO: Generative Engine Optimizationでは、コンテンツの可視性を最大40%向上させるGEO手法が検証されました。特に統計データの追加(Statistics Addition)が41%、引用の追加(Quotation Addition)が28%、出典の明示(Cite Sources)は下位コンテンツで115%の改善を示したことが報告されています。一方でキーワードスタッフィングは逆効果で、ベースラインより10%悪化していました。
この論文自身も「効果はドメインや生成エンジンによって変動する」と明記しており、領域別の検証が必要であると示唆しています。数字を直接的な目標値として扱うのではなく、「統計・出典・一次情報を組み込む方向性に投資する価値が示唆されている」程度の温度感で参考にするのが適切です。
【手順4のチェック項目】
- 主要な主張に対して、統計データや一次情報の出典を付けているか
- 調査名・調査機関・発表年月を明示しているか
- 独自データ(自社調査、社内データ、事例)を組み込んでいるか
- 古いデータが残っていないか、定期的に見直しているか
- キーワード詰め込み的な表現になっていないか
手順5:著者・監修者・会社情報・構造化データで信頼シグナルを明示する
5つ目の手順は、コンテンツ単体ではなく「誰が書いて、誰が裏付けているのか」をAIが検証できる状態にすることです。E-E-A-T的な発想ですが、ChatGPTのLLMO対策ではより広く「AIが検証しやすい信頼シグナル」と捉えると整理しやすくなります。
具体的には、著者名・肩書・略歴・SNSや公開プロフィールへのリンク、監修者情報、運営会社情報、所在地、連絡先、調査日、更新日などをページ内に明示します。さらに、Organization・Person・Article・FAQPage・HowToといった構造化データ(Schema.org)を実装することで、機械可読な形でメタ情報を提供できます。構造化データはAIが情報を整理しやすくなる補助的な信頼シグナルとして機能し得るものの、引用獲得を確約するものではありません。
会社名・サービス名・代表者名などをAIに一貫して認識させる考え方は、「エンティティとは」の記事で詳しく解説しています。表記揺れを減らし、複数チャネルで同じ表現を使うことが、AIが企業や人物を同一エンティティとして処理する助けになります。
【手順5のチェック項目】
- 記事ごとに著者情報(氏名・肩書・略歴)を表示しているか
- 必要に応じて監修者情報を明示しているか
- 運営会社・所在地・代表者などの会社情報ページが整備されているか
- 主要な記事に公開日・更新日を表示しているか
- Article/FAQPage/Organization等の構造化データを実装しているか
手順6:第三者メディア・比較記事・PRで外部言及を増やす
6つ目の手順は、自社サイト外での言及・露出を意図的に増やすことです。AIは自社サイトの主張だけで判断するのではなく、複数の第三者ソースを横断的に参照して回答を構成します。外部評価のないブランドは、AIの回答候補に上がりにくい構造的不利を抱えます。
具体的な施策としては、業界メディアへの寄稿、PRリリース、比較記事サイト(業界別ランキング・比較メディア)への掲載、専門家としてのインタビュー対応、ウェビナーや公開セミナーでの登壇、SNSでの発信などが挙げられます。実務上は、OAI-SearchBotの許可だけで引用率が急に改善するケースは多くありません。むしろ、Bingでの発見性、ページ冒頭の回答設計、外部メディア上の言及がそろったタイミングで、AI回答内の扱われ方が変わりやすくなる傾向があります。
外部評価の考え方は、従来SEO目的の相互リンクとは別物として整理する必要があります。「LLMO時代の外部言及」の記事で、被リンクと言及・サイテーションの違い、AI検索を意識した施策の組み立て方を解説しています。
【手順6のチェック項目】
- 業界メディア・ニュースサイトでの掲載実績を継続的に作っているか
- 比較記事・ランキング記事に自社が登場しているか
- PRリリースを定期的に配信しているか
- 代表・担当者がインタビュー・登壇等で表出しているか
- SNS・YouTubeなど多チャネルで一貫した発信を行っているか
手順7:主要プロンプトで引用率・言及率・推薦率を継続測定する
最後の手順は、自社にとって重要なプロンプト群を定義し、ChatGPTでの引用率・言及率・推薦率を定点観測することです。施策を打ちっぱなしにせず、Share of Modelを継続的に測定して改善サイクルに乗せます。
測定に使うプロンプトは、ユーザーが実際に投げかけそうな自然な質問文を中心に設計します。代表例は次のようなパターンです。
・「〇〇におすすめの会社を教えて」
・「〇〇の比較ポイントを教えて」
・「〇〇ならどのサービスが良い?」
・「〇〇の専門会社を5社挙げて」
・「株式会社〇〇について、強み・弱み・評判を教えて」これらのプロンプトを月次・四半期で継続実行し、自社・競合の登場有無、登場順、文脈(ポジティブ/中立/ネガティブ)を記録していきます。同じプロンプトでも回答が毎回完全には一致しないため、複数回試行して傾向を見る運用が現実的です。どのプロンプトやクエリを優先的に測るべきかは、「LLMOキーワードの選び方」で詳しく解説しています。
【手順7のチェック項目】
- 自社の主要顧客が投げそうな代表プロンプトを20〜50本程度定義しているか
- プロンプトごとに自社・競合の登場有無を記録しているか
- 記録を月次・四半期で継続できるフォーマットになっているか
- 引用率・言及率・推薦率を分けて管理しているか
- ネガティブな言及・誤情報を発見した際の対応プロセスがあるか
具体的な測定方法とShare of Modelの活用については、本記事後半の効果測定セクションでさらに詳しく扱います。
ChatGPTでの引用・言及・推薦を測るには、確認する質問文そのものを設計しておく必要があります。詳しくはChatGPTで確認すべきプロンプト設計を参考にしてください。
【SEO・LLMO対策でお困りではないですか?】
株式会社アドカルは主に生成AIを活用したデジタルマーケティング支援やマーケティングDXに強みを持った企業です。
貴社のパートナーとして、少数精鋭で担当させていただくので、
「LLMO対策について詳しく知りたい」
「現状のSEO対策で成果が出ていない」
「LLMO対策でAI検索からの集客を強化したい」
とお悩みの方は、ぜひ弊社にご相談ください。
貴社のご相談内容に合わせて、最適なご提案をさせていただきます。
サービスの詳細は下記からご確認ください。無料相談も可能です。
ChatGPTに引用されやすい記事構成の作り方
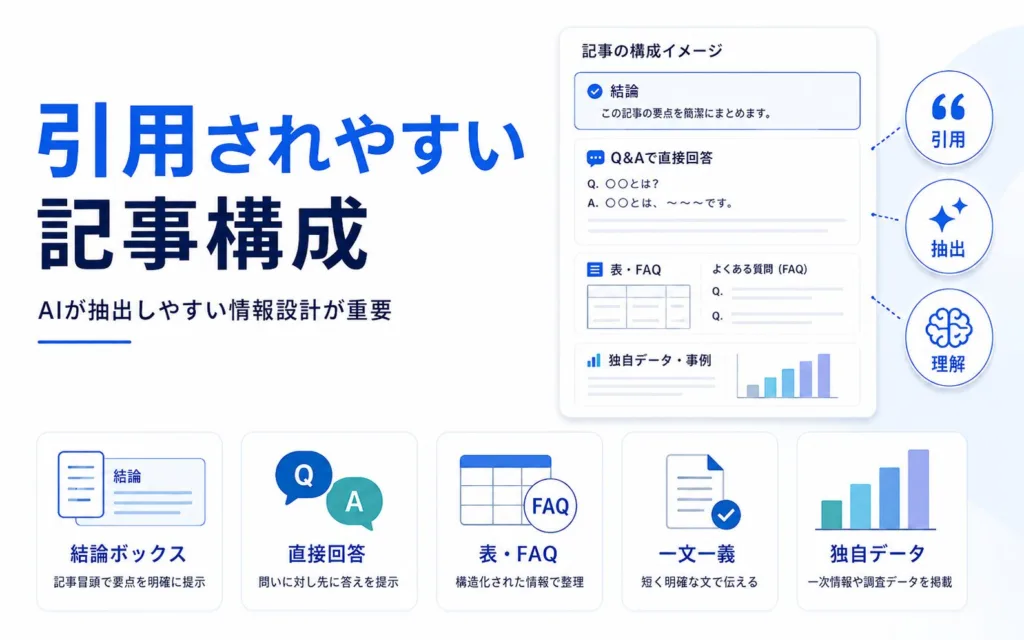
引用されやすい記事構成には共通のフォーマットがあります。冒頭の結論ボックス、見出し直下の直接回答、表やFAQによる分解、一文一義の文章、独自データの組み込み――この5要素を押さえると、AIが回答を組み立てる際に抽出しやすい記事になります。本セクションでは、各要素を具体的なテンプレートとともに解説します。
冒頭に結論ボックスを置く
記事冒頭、リード文の直後にH2の前で「結論ボックス」を置くことで、ページ上部から重要な情報をAIに渡せます。前述の通り、海外の実務分析でもAI回答に採用される情報がページ上部に偏る傾向が指摘されており、上部に重要情報を集中させる設計には合理性があります。
結論ボックスのテンプレートは次のような構造が機能しやすくなります。記事の対策キーワードを冒頭に置き、要点を3〜5つに絞って番号付きリストで提示します。それぞれの項目は1文に収め、20〜40字程度を目安にすると、AI抽出時にそのまま使われやすい長さになります。
本記事の冒頭にも結論ボックスを配置していますが、これは記事構造としての「お手本」を意図的に示しています。読者が自社記事を作成する際は、対策キーワードの直後に「重要なポイントは次の◯つです」と前置きし、箇条書きで列挙する形式から始めるのが取り組みやすい入口です。
各H2・H3直下に40〜80字の直接回答を入れる
各見出しの直下に40〜80字程度の直接回答を置くと、その見出しに対するAIの「短い答え」として抽出されやすくなります。記事全体を通して、見出し=質問、直後の文章=回答という対応関係を意識します。
テンプレートとしては「〇〇とは、△△である」「〇〇のポイントは△△と□□の2点である」「〇〇は次の3つで構成される」のように、定義・要点列挙・分類のいずれかの型で書き出すのが汎用的です。回答が長くなる場合は、最初の2〜3文で要点を提示し、その後の段落で詳細を展開する「逆ピラミッド型」を採用すると、AI抽出の効率が上がります。
本記事も各H3の冒頭でこの形式を採用しています。執筆時には「この見出しに対する1文の答えは何か」を先に決めてから、その答えを冒頭に置いて本文を組み立てるとブレません。
表・箇条書き・FAQでAIが抽出しやすい単位に分ける
表・箇条書き・FAQは、AIが情報を抽出する際の「単位」として機能しやすい形式です。長文の説明だけで進めず、複数項目を整理する場面では構造化されたフォーマットに切り替えるのが効果的です。
表は「比較」「分類」「定義一覧」に強く、本記事ではクローラー3種の整理や引用されやすいページの共通点で活用しています。箇条書きはチェックリストや手順のサマリーに向き、本記事の7手順各項で実装しました。FAQ形式は読者が抱きそうな疑問を「Q→A」の対で並べる形式で、構造化データ(FAQPage)とあわせて実装するとAIにとっても処理しやすくなります。
注意点として、過度に箇条書きや表に頼ると本文がスカスカになり、専門性の伝達が損なわれます。「文章で展開する部分」と「構造化して並べる部分」をバランスよく配置するのが理想的です。
一文一義で主語と述語を明確にする
文章レベルでは、一文一義・主語と述語の明確化・PREP法による論理展開を徹底します。1文に複数の主張を詰め込むと、AIが部分抽出した際に意味が崩れやすくなるためです。
PREP法は「Point(結論)→Reason(理由)→Example(例)→Point(再度結論)」の順で展開する書き方で、見出しごとの段落構造として有効です。「結論を先に書く→根拠を提示する→具体例で補強する→もう一度結論を確認する」という流れを段落単位で繰り返すと、AIにとっても人間読者にとっても理解しやすい記事になります。
また、一文を長くしすぎないことも重要です。日本語の場合、1文60〜80字を目安にし、それを超える場合は分割を検討します。主語が省略されがちな日本語の特性上、「誰が何をどうしたのか」を意識的に明示する習慣をつけると、AI抽出の精度も上がります。
独自データ・事例・検証結果を入れて一般論から脱却する
最後の要素は、独自データ・事例・検証結果を組み込むことです。一般論だけの記事は他社の類似記事と差別化されず、AI回答内でも置き換え可能な情報として扱われてしまいます。
独自データの形式は様々で、自社の顧客データから得た傾向、自社で実施した調査、自社事例の数値結果(CVR改善・流入推移など)、検証実験の結果などが該当します。これらを記事内で提示する際は、調査方法・対象・期間といったメソドロジーも明示することで、AIが信頼性を評価しやすくなります。
事例についても、実在する公開事例のみを使用し、出典を明記することが基本ルールです。架空の数値や匿名性の高すぎる事例は、AIの信頼シグナルとしては弱くなる傾向があります。記事を書く前段階で、「この記事だけが提供できる固有の価値は何か」を1文で定義してから取りかかると、一般論への流れを防ぎやすくなります。
ChatGPTのLLMO対策でよくある誤解と注意点
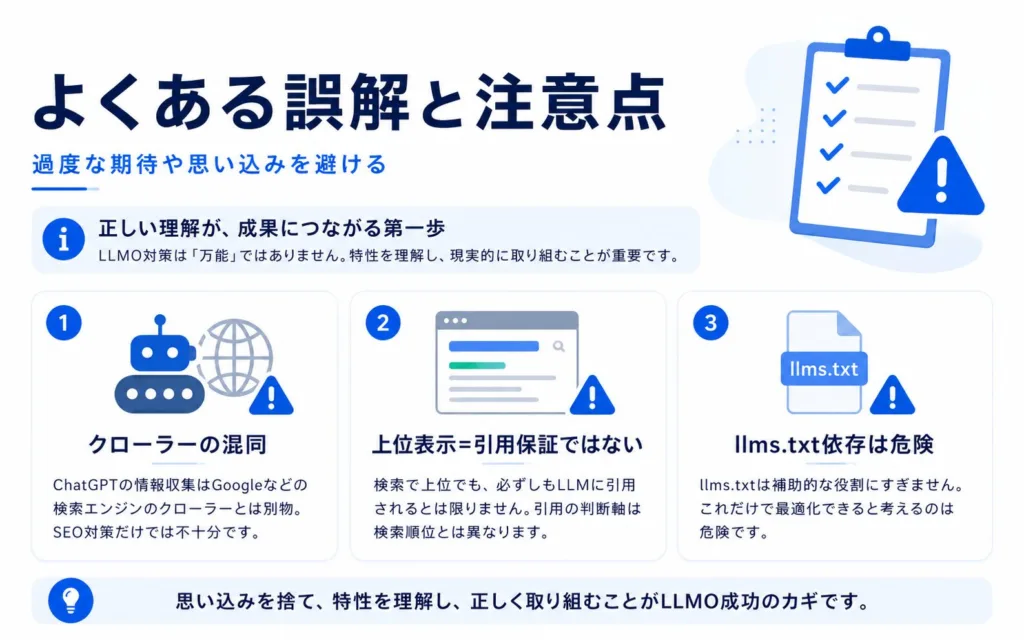
ChatGPTのLLMO対策では、効果が誇張されがちな施策や、断定的に語られがちなテクニックに惑わされないことも重要です。本セクションでは、実務でつまずきやすい誤解を整理し、施策の優先順位を健全に保つための注意点を解説します。
OAI-SearchBotとGPTBotの役割を混同するリスク
最も多い誤解が、OAI-SearchBotとGPTBotを同じものとして扱ってしまうケースです。両者は役割が完全に異なるため、設定を誤るとChatGPT Searchへの表示機会を意図せず失うことになります。
OAI-SearchBotはChatGPT Search用のクローラーで、ChatGPT Search上での表示・引用候補となる前提条件に関わります。一方GPTBotはモデル学習用で、許可してもChatGPT Searchでの引用が増えるわけではありません。「GPTBotを許可したのにChatGPTで引用されない」という相談がしばしば見られますが、GPTBotは学習用のため即時引用には寄与しないというのが正解です。逆に学習データに含めたくないがChatGPT Searchには表示されたい、というニーズには「GPTBotだけDisallow、OAI-SearchBotはAllow」という設定で対応できます。
もうひとつの注意点として、「OAI-SearchBotを許可すれば必ずChatGPTで引用される」とは限らない点があります。OpenAIは引用や上位掲載を保証しておらず、許可は引用の必要条件ではあっても十分条件ではないという理解が現実的です。
構造化データやGoogle上位が引用を保証するという思い込み
構造化データを実装すればChatGPTに必ず引用される、あるいはGoogleで1位ならChatGPTでも引用される、という思い込みは避けるべきです。どちらも引用の助けにはなり得ますが、保証要素ではありません。
構造化データ(Schema.org)は、検索エンジンがコンテンツを機械的に理解しやすくするためのマークアップで、Googleでもリッチリザルト表示は「ヒント」であって保証されないと公式に明記されています。ChatGPTでも同様で、構造化データの実装はAI処理を助ける可能性はあるものの、引用獲得を確約するものではありません。補助的な信頼シグナルとして位置づけ、過剰に期待しすぎないのが安全です。
Google上位とChatGPT引用の関係も非対称です。前述のSeer Interactiveの調査では、Bing上位との一致率が87%だったのに対しGoogle上位との一致率は56%にとどまっており、Bing側との相関の方が強い傾向が示唆されています。Google SEOで上位を取れていても、Bingで圏外であればChatGPT引用は得られにくい構造です。
このため、「Googleで1位だからLLMO対策は不要」「構造化データを入れたから対策完了」と判断するのは早計です。複数のシグナルを総合的に整える発想が必要になります。
llms.txtや単発施策への過度な依存
llms.txtや個別の流行施策に過度に依存することも、典型的な落とし穴の一つです。施策単体で「これだけやれば引用される」というショートカットは現時点では存在しないと考えるのが安全です。
Ahrefsの整理によれば、llms.txtは2024年9月にJeremy Howardが提案した規格で、AIにサイト構造を伝えるためのMarkdownファイルです。Anthropicなど一部の企業は自社サイトで公開していますが、主要LLM提供者がllms.txtを「公式に読み取って利用する」と表明している状態には至っていないとされています。Googleが2025年に発表したAgent2Agent(A2A)プロトコルでllms.txtに言及はあったものの、各社のクローラーが本格的に参照しているかは不透明な段階です。
llms.txtの基本的な書き方や設置手順は「LLMS.txtとは」で別途解説していますが、本記事で述べた通り、現時点では補助的施策として扱うのが妥当です。llms.txtを実装すること自体は将来的なメリットを期待した「保険」としては成立し得ますが、これに頼って他の施策を後回しにするのは合理的ではありません。
LLMO対策で本当に効くのは、クロール環境・Bingでの発見性・コンテンツ構造・信頼シグナル・外部評価・継続測定という基礎の積み上げです。流行施策に時間を割く前に、これらが揃っているかを点検することを優先しましょう。

LLMO対策は「実施しっぱなし」では成果が見えません。GA4でのリファラル流入、Share of Modelによる競合比較、指名検索・問い合わせの変化、AI回答内のセンチメント確認――これら4つの軸で効果を定点観測する仕組みを構築します。本セクションでは、それぞれの実務的なやり方を解説し、最後に施策の優先順位もまとめて提示します。
GA4でchatgpt.comからのリファラル流入を追跡する
ChatGPTからの実流入は、GA4で「chatgpt.com」をソースとするリファラルとして可視化できます。OpenAIが公式に明示している自動UTM付与の仕様を利用するため、追加実装なしで追跡が始められます。
OpenAI公式FAQによると、ChatGPTからの参照URLには自動でutm_source=chatgpt.comというUTMパラメータが付与されるとされています。これにより、Google Analytics 4などの解析ツールでChatGPT経由の流入を明確に切り出せます。
GA4での具体的な確認は、「集客→トラフィック獲得」または「ライフサイクル→集客」レポートでセッションのソース/メディアにchatgpt.comが含まれるかを見るのが基本です。さらに探索レポートでカスタムレポートを作り、ChatGPTからの流入のランディングページ・コンバージョン率・滞在時間を可視化すると、AI流入の「質」も把握できます。流入数だけでなく、AI流入特有のユーザー行動パターン(検討フェーズが進んでいる、特定ページに直行する等)が見えてきます。
Share of Modelは、特定の質問群に対してAI回答内で自社が引用・言及・推薦される割合を、競合と比較する指標です。GA4でわかる「流入」だけでなく、「そもそもAI回答内で自社が候補に挙がるか」という上流の可視性を測れます。
測定の手順は次の通りです。第一に、自社が獲得したいプロンプト群(20〜50本程度)を定義します。第二に、各プロンプトを月次・四半期で複数回ChatGPTに投げ、自社・競合の登場有無を記録します。第三に、登場順や言及文脈(ポジティブ/中立/ネガティブ)もあわせて記録します。第四に、競合との相対比率を算出し、時系列の推移を見ます。
測定すべき項目を表で整理すると次のようになります。
| 指標 | 意味 |
|---|---|
| 引用率 | 自社URLが出典リンクとして表示された割合 |
| 言及率 | 自社名・サービス名が回答内に出た割合 |
| 推薦率 | おすすめ候補として提示された割合 |
| 表示順位 | 複数候補の中で何番目に出たか |
| センチメント | ポジティブ・中立・ネガティブのいずれの扱いか |
| 競合比較 | 競合A/B/Cと比べた回答内シェア |
Semrushの3ヶ月調査では、ChatGPTでのReddit引用率が8月初旬の約60%から9月中旬には約10%へと急落し、Wikipediaも55%から20%未満まで下がったことが報告されています。引用元の構成は時期によって大きく変動するため、「一度引用されたら安定」と考えるのは危険で、定点観測を継続する必要があります。KPI設計や測定シートの作り方を含めた効果測定の全体像は、「LLMOの効果測定」でさらに詳しく解説しています。
指名検索・問い合わせ経路の変化からブランド浸透度を評価する
ChatGPT経由の認知拡大は、必ずしも直接流入として表れるとは限りません。AI回答を見たユーザーがその後Googleで指名検索したり、問い合わせフォームに直接来訪したりするケースも多いため、これらの間接指標も含めて評価します。
具体的には、Google Search Consoleで「会社名」「サービス名」を含むクエリの表示回数・クリック数の推移を追います。LLMO対策強化のタイミングと指名検索が連動して伸びる場合、AI回答経由でブランド名を知ったユーザーがGoogleで再検索している可能性が高いと判断できます。また、問い合わせフォームの「貴社を知ったきっかけ」項目に「ChatGPT」「AIに勧められた」といった選択肢を加えることで、定性的な裏取りも可能です。
サイバーエージェントGEOラボの調査でも、AIにおすすめされた商品・サービスをさらに自分で詳しく調べるユーザーが69.0%にのぼると示されており、AI回答が「直接の流入」よりも先に「指名検索の発火点」として機能するケースが多いことが分かります。流入の数字だけでなく、ブランド名検索の伸びまでセットで評価する習慣をつけましょう。
AI回答内の誤情報・ネガティブ表現を確認する
効果測定の最後の軸は、AI回答内で自社がどう描写されているかという質的なモニタリングです。誤情報・古い情報・ネガティブな表現を放置すると、ブランド毀損につながるリスクがあります。
確認すべき具体例としては、サービス内容に関する誤った情報(提供していない機能が提供中と書かれている、料金体系が古いままなど)、会社情報の誤り(代表者名や所在地が古い情報のまま)、競合との比較で不当に貶められている描写、すでに解決済みのトラブル事例が古い文脈で語られているケースなどがあります。これらは、ChatGPTが古い情報を学習データとして保持していたり、ネガティブな第三者ソースを優先的に参照している場合に発生します。
発見した場合の対応としては、自社サイトでの正確な情報発信を強化する(誤情報を否定する一次ソースを増やす)、当該テーマでのPR・メディア露出を増やして上書きする、可能であれば誤情報を含むサイトに修正を依頼する、といった段階的なアプローチが現実的です。即時の解決は難しいケースが多いものの、放置しないことが重要です。Share of Modelの測定とあわせて、月次でブランドモニタリングをルーチン化することをおすすめします。
ChatGPTのLLMO対策における施策の優先順位
ここまで紹介した施策を一度に走らせるのは現実的ではありません。アドカルの診断現場で多くの企業を見てきた経験から、優先順位はおおむね次のように整理できます。
| 優先度 | 施策 | 理由 |
|---|---|---|
| 高 | OAI-SearchBot・noindex・Bingインデックスの確認 | 技術的に拾われない状態を防ぐための前提条件 |
| 高 | 主要ページの結論先出し・FAQ化 | AIが回答に抽出しやすくなる |
| 中 | 著者・会社情報・構造化データ | AIが検証しやすい信頼シグナルの補強 |
| 中 | 外部メディア・比較記事への露出 | 言及・推薦に影響しやすい外部評価の獲得 |
| 中 | プロンプト定点観測(Share of Model) | 施策の効果を判断し改善サイクルを回せる |
| 低〜中 | llms.txt | 現時点では補助的施策で過信は禁物 |
「高」の2項目が満たされていない状態で「中」以下に投資しても、回答に反映されにくくなります。まずは技術前提と主要ページの構造を整え、その上で信頼シグナル・外部評価・効果測定を順に積み上げていくのが、無駄の少ない進め方です。リソースが限られる企業での段階的な進め方は、「中小企業のLLMO対策」で具体的な判断軸を解説しています。
社内で運用するか外部に依頼するかで迷う場合は、「LLMO対策の内製化」で体制・費用・ツールの考え方をまとめています。事業フェーズと社内リソースに応じて、内製・部分外注・フル外注のいずれが適切かを判断する材料にしてください。
まとめ:ChatGPTのLLMO対策でAIに見つけられ信頼され引用される状態を作ろう

ChatGPTのLLMO対策は、OAI-SearchBotの許可とBingでの発見性確認という技術基盤の整備から始まり、引用されやすい記事構成、信頼シグナルの強化、外部メディア露出、そしてShare of Modelによる継続測定まで、複数のレイヤーを同時並行で進める取り組みです。一発逆転の魔法はなく、基礎の積み上げが最も効きます。生成AIを検索に使うユーザーが全世代で37.0%に達した今、AI回答内の可視性は事業成果に直結する経営課題です。
株式会社アドカルでは、LLMO診断・AI検索での表示状況調査・コンテンツ改善・外部言及強化まで一貫して支援しています。ChatGPTやGoogle AI Overview上で自社がどのように引用・言及・推薦されているかを把握したい企業は、LLMOコンサルティングサービスをご覧ください。
【SEO・LLMO対策でお困りではないですか?】
株式会社アドカルは主に生成AIを活用したデジタルマーケティング支援やマーケティングDXに強みを持った企業です。
貴社のパートナーとして、少数精鋭で担当させていただくので、
「LLMO対策について詳しく知りたい」
「現状のSEO対策で成果が出ていない」
「LLMO対策でAI検索からの集客を強化したい」
とお悩みの方は、ぜひ弊社にご相談ください。
貴社のご相談内容に合わせて、最適なご提案をさせていただきます。
サービスの詳細は下記からご確認ください。無料相談も可能です。


