
ブラックハットLLMOとは?5つの手口と違反リスク・ブランドを守る対策
この記事でわかること
-
ブラックハットLLMOの定義とSEOとの違い
-
実在する根拠と代表的な5つの手口
-
手を出す危険性と攻撃された場合の被害
-
自社を守る防御策と正しいLLMO対策


「ブラックハットLLMO」とは、ChatGPTやGemini、GoogleのAI Overviews、Perplexityといった生成AIの回答に、自社や特定ブランドを不自然に表示・引用させることを狙った、不正またはグレーな最適化手法の総称です。ただし業界で完全に定義が固まった公式用語ではないため、本記事では「生成AI回答・AI検索・LLM検索の出力を、欺く目的で操作しようとする行為」と定義したうえで解説します。本記事のゴールは攻撃手法のハウツーではありません。何が公式にNGで、なぜ危険なのかを正しく理解し、自社ブランドを汚染攻撃から守りながら、AIに信頼される正攻法のLLMOへ進むための「判断軸」を示すことにあります。
目次
ブラックハットLLMOとは?生成AI回答を不正に操作する手法
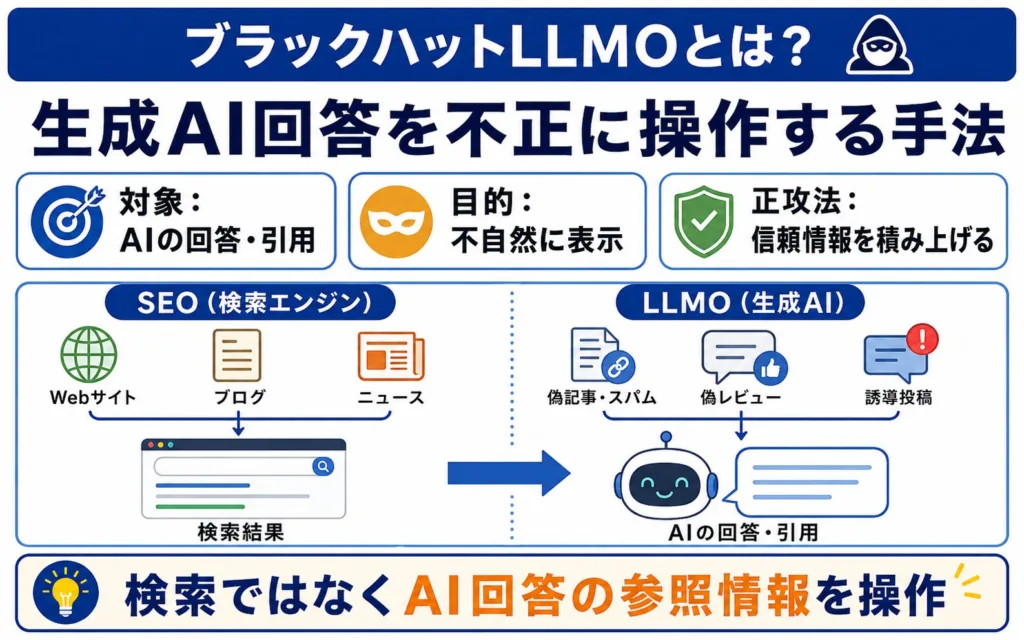
このセクションでは、ブラックハットLLMOという言葉が何を指すのかをあらためて整理します。そのうえで、従来のブラックハットSEOとの違いや、ホワイト・グレー・ブラックを分ける境界線を、実務施策のレベルまで具体的に示します。
ブラックハットLLMOの定義
ブラックハットLLMOとは、生成AIが返す回答や要約のなかに、自社や特定ブランドを不自然に表示・引用させることを狙った、不正またはグレーな最適化手法の総称です。前述のとおり、これは業界で公式に定義が固まった用語ではありません。LLMO(大規模言語モデル最適化)やGEO(生成エンジン最適化)、AIO(AI最適化)といった概念が広がるなかで、その「不正なやり方」を指す通称として使われ始めた、と理解しておくとよいでしょう。LLMO・AIO・GEOの違いを先に整理しておくと、本記事の位置づけも理解しやすくなります。
本記事では混乱を避けるため、ブラックハットLLMOを「生成AI回答・AI検索・LLM検索の出力を欺く目的で操作する行為」と一貫して定義します。重要なのは、ここでの操作対象が「AIの学習そのもの」ではなく、AIが回答を組み立てる際に参照する情報である、という点です。なお、LLMOの基本概念やSEOとの違いは、LLMOとはを解説した記事で詳しく整理しています。
ブラックハットSEOとの違い
ブラックハットSEOとブラックハットLLMOは、欺こうとする標的が異なります。前者が検索エンジンのランキングアルゴリズムや被リンクの数を操作しようとするのに対し、後者はAIが回答を生成する際に「取得・引用・要約の対象になる情報」を操作しようとする点に特徴があります。
ただし両者は完全な別物ではありません。多くの生成AI検索は通常の検索インデックスから情報を取得するため、土台はSEOと地続きです。Googleの生成AI最適化ガイドも、生成AI機能はコアの検索ランキング・品質システムに根ざしており、生成AI検索向けの最適化は本質的にSEOであると説明しています。SEOの延長線上に、新たなリスクと機会が生まれていると捉えるのが正確です。
ホワイト・グレー・ブラックの境界線
ある施策が「白か黒か」を分けるのは、使うテクニックそのものよりも、ユーザーやAIを欺く意図があるかどうかです。考え方の軸は次のように整理できます。
- ホワイト:信頼できる一次情報を整え、正しく拾われることを目指す
- グレー:違反とは言い切れないが、意図や手法に不自然さが残る
- ブラック:実体のない評価を信じ込ませるなど欺瞞を明確に狙う
より実務に引きつけると、同じ「LLMO施策」でも、その目的と中身によって判定は次のように分かれます。読者が一番知りたい「どこまでが普通の対策で、どこから危ないのか」を、施策単位で示したものが以下の表です。
表1:LLMO施策のホワイト〜ブラック判定
| 施策 | 判定 |
|---|---|
| 著者情報・会社情報を正確に明示する | ホワイト |
| 独自調査や具体的な導入事例を公開する | ホワイト |
| 構造化データを整備する | ホワイト |
| AI向けにだけ過剰な説明文を追加する | グレー〜ブラック |
| 実在しない監修者・著者を掲載する | ブラック |
| 第三者を装った比較記事を量産する | ブラック |
Googleの生成AI最適化ガイドでも、汎用的なコモディティコンテンツではなく、一次体験や独自データ・専門家の視点を備えた「非コモディティな」コンテンツを作ることが、長期的なAI検索での可視性に最も効くと説明されています。つまり、正攻法のLLMOとは特別な裏技ではなく、信頼できる独自情報を地道に整える取り組みそのものなのです。
ブラックハットLLMOは本当に存在するのか

「造語のように聞こえるが、本当に存在するのか」という疑問に答えます。公式ポリシーと学術研究の両面から、実在する部分と、過大に語られがちな誤解の部分を切り分けて整理します。
生成AI回答の操作はGoogleのスパムポリシー対象になり得る
まず公式の位置づけから確認します。Googleはウェブ検索のスパムポリシーを改定し、スパムの定義を「検索でコンテンツを目立たせるためにユーザーを欺いたり、検索システムを操作したりする技術」とし、ここに「Google検索における生成AI回答を操作しようとする行為」を明確に含めました。これにより、AI Overviewsなどの生成AI回答に不正に取り上げられることを狙う行為も、スパムの文脈で扱われ得ることになります。AI Overviewsの仕組みやSEOへの影響は、AI Overviewsとはを解説した記事でも整理しています。
同ポリシーでは、検索エンジンとユーザーに異なる内容を見せて誤認させるクローキングや、隠しテキストもスパムの例として整理されています。違反した場合、検索結果での順位低下や除外といった対応の対象になり得ると示されています。
研究でもLLM検索への操作リスクが指摘されている
学術研究も、操作の現実性を裏づけています。LLM搭載検索エンジンを対象にした研究(arXiv:2603.25500、WWW 2026)では、従来型のブラックハットSEO攻撃の99.78%以上がリトリーバル(情報取得)の段階で抑制された一方、LLM検索向けに設計された「書き換えクエリを狙う詰め込み(rewritten-query stuffing)」や「分割テキスト(segmented texts)」では、操作率がベースラインの約2倍に上がったと報告されています。
また、LLMが複数の第三者コンテンツから推薦・選択する場面を扱った研究(Preference Manipulation Attacks、arXiv:2406.18382)では、ページや説明文の作り方によって、攻撃者側の商品を推奨させたり競合を不利に見せたりできるリスクが指摘されています。操作は理論上の話ではなく、検証されつつある現実のリスクなのです。
「AIに何でも覚え込ませられる」は誤解
一方で、誇張された理解には注意が必要です。「AIに自社の情報を好きなように覚え込ませられる」という発想は、多くの場合に誤りです。Googleの最適化ガイドが説明するように、生成AI機能はコアの検索システムに根ざし、検索インデックスから情報を取得・要約して回答を組み立てます。
つまり、一般的な企業が触れられるのはAIの学習重みではなく、あくまで「取得・引用・要約の対象になる情報」です。さらにGoogleは、非真正な言及を追い求めても、生成AI機能はコア検索と同じ仕組みやセーフガードに依拠するため有効になりにくいと述べています。だからこそ、信頼できる一次情報を整えるという正攻法が土台になります。また、Google AI Modeのように質問が複数のサブクエリへ分解される環境では、単一記事だけでなくトピック全体の網羅性も重要になります。
ブラックハットLLMOで使われる代表的な5つの手口

ここからは代表的な手口を整理します。本記事は再現手順を一切示しません。各手口について「何を狙っているか」「なぜ危険か」「どう身を守るか」の観点から、防御に役立つ知識として解説します。
AI生成サイト群による外部評価の水増し
狙いは、外部からの評価を人工的に水増しすることにあります。生成AI検索では、複数の外部ソースに共通して現れる情報が、回答生成時の裏づけとして扱われる場合があります。この性質を逆手に取り、実体のない評価をあたかも世間の総意であるかのように見せかけようとする手口です。
しかし、こうして量産されるサイト群は内容が均質になりがちです。情報が均質化すると、AIや検索システムにとって個別ページを引用する理由が弱くなり、結果として引用・参照されにくくなる可能性があります。Googleが独自性のないコモディティコンテンツを評価しないと示している方針とも整合します。防御の観点では、自社や競合について不自然に同質な評価が拡散していないかを監視することが出発点になります。自然な外部評価を高める考え方は、リンクポピュラリティとはを解説した記事でも整理しています。
AIクローラと人間で表示を変えるクローキング
狙いは、AI向けクローラと人間の閲覧者とで異なる内容を見せ、AIにだけ都合のよい情報を読ませることにあります。AIには整理された情報を提示し、人間には別のページを見せて誤認させようとするものです。
これはGoogleのスパムポリシーが明確に対象とする行為であり、検索とユーザーに異なる内容を見せて欺くものとして位置づけられています。露出低下や除外の対象になり得るため、リスクは大きいといえます。自社では、AI向けに見せている内容と人間が見る内容が一致しているかを定期的に確認することが防御になります。AIクローラーの種類やrobots.txtでの制御方法は、AIクローラーとはを解説した記事で確認できます。
偽の著者・監修者プロフィールの捏造
狙いは、専門性・権威性・信頼性を重視するAIの評価傾向を悪用することです。実在しない専門家の経歴や受賞歴を作り、コンテンツの信頼性をAIに誤認させようとします。
この危険性は実例からも明らかです。2023年には、Sports IllustratedがAI生成とされる記事・著者プロフィールを掲載していた問題が報じられ、ブランドの信頼を損なう事態となりました(PBS NewsHour ほか, 2023年11月)。防御の観点では、自社サイトの監修者・著者情報が実在の経歴に裏づけられ、検証可能であることを保つことが重要です。
比較記事や口コミの不自然な量産
狙いは、自社を有利に、競合を不利に見せる比較記事やレビューを大量に作り、AIの推薦判断を誘導することです。第三者を装った比較記事や、不自然に偏った口コミを量産するのが典型です。
前述のPreference Manipulation Attacks(arXiv:2406.18382)が示すように、AIが第三者コンテンツから推薦を選ぶ場面は操作に弱い面があります。Googleも、生成AI回答やランキングを操作する目的でページを大量に作成する行為はscaled content abuse(大量生成によるスパム)に該当し得ること、また非真正な言及を追い求める施策は長期的に有効ではないことを説明しています。防御としては、自社に関する比較・口コミの分布を監査し、不自然な量産の兆候を早期に把握することが有効です。なお、安全な外部評価の獲得方法は、リンクビルディングとはを解説した記事も参考になります。
キーワード・エンティティの不自然な詰め込み
狙いは、AIが拾いやすいように、エンティティ(自社名・関連語)を不自然に詰め込むことです。人間が読むための文脈やストーリーを削り、固有名詞や関連語を高密度に並べたテキストに置き換えようとします。
研究(arXiv:2603.25500)でも、書き換えクエリを狙った詰め込みなどがLLM検索の操作率を高めうると報告されています。ただし、こうした無機質なコンテンツは均質化しやすく、引用候補から外れやすくなる可能性もあります。Googleも、AIではなく人間の読者に向けて、明確な構成で書くことを推奨しています。防御の観点では、自社のページが読者にとって自然で価値ある文章になっているかを基準に点検することが大切です。
ブラックハットLLMOが危険な理由

手口の解説に続き、なぜこれらに手を出すべきでないのかを整理します。検索露出、ブランド、AI引用、セキュリティの4つの側面から、自社が被る不利益を具体的に見ていきます。
Google検索でスパム扱いされ露出が下がる可能性
第一のリスクは、検索での露出が下がることです。前述のとおりGoogleは、生成AI回答を操作しようとする行為をスパムポリシーの対象に含めました。違反が検出されれば、検索結果での順位低下や除外といった対応の対象になり得ます。
Googleは違反の検出を自動システムと人間によるレビューの両面で行うとしており、深刻な場合には手動による対策が取られる可能性もあります。短期的な可視性のために、検索からの露出という土台そのものを失う構図になりかねません。
ブランド毀損や法務リスクにつながる
第二のリスクは、ブランドと法務の問題です。捏造した監修者や偽のレビューは、発覚すればブランドへの信頼を大きく損ないます。前章で触れた架空の執筆者の事例のように、一度の発覚が長期的な信用の毀損につながることもあります。
さらに、虚偽の実績表示や他社を貶める表現は、景品表示法などの観点から法務リスクをはらみます。小手先の操作が、企業全体のレピュテーションと法的責任に波及しうるのです。
AI回答で逆に引用されにくくなる可能性
第三のリスクは、皮肉にもAI回答で引用されにくくなることです。AIに読ませる目的で量産された均質なコンテンツは、独自性が乏しいために、引用・参照の候補として埋もれやすくなります。
その結果、本来狙っていた「AIに引用される」という目的とは逆の結果を招きかねません。短期的に露出を狙っても、長期的には引用・検索露出・ブランド信頼を損なう可能性があります。
間接プロンプトインジェクションなどセキュリティリスクに発展する
第四のリスクは、セキュリティ問題への発展です。外部のWebページや文書に指示を埋め込み、それを読み込んだAIの挙動を変えようとする行為は、間接プロンプトインジェクションと呼ばれます。OWASPはこれを最重要級のLLMリスク(LLM01:2025)として整理しています。
AI回答の操作を狙う発想は、こうした攻撃と地続きです。自社が手を染めればコンプライアンス上の重大な問題となり、また後述のように、自社が標的にされる側のリスクとしても理解しておく必要があります。
出典:OWASP「LLM01:2025 Prompt Injection」
自社がブラックハットLLMO攻撃を受けると何が起きるか
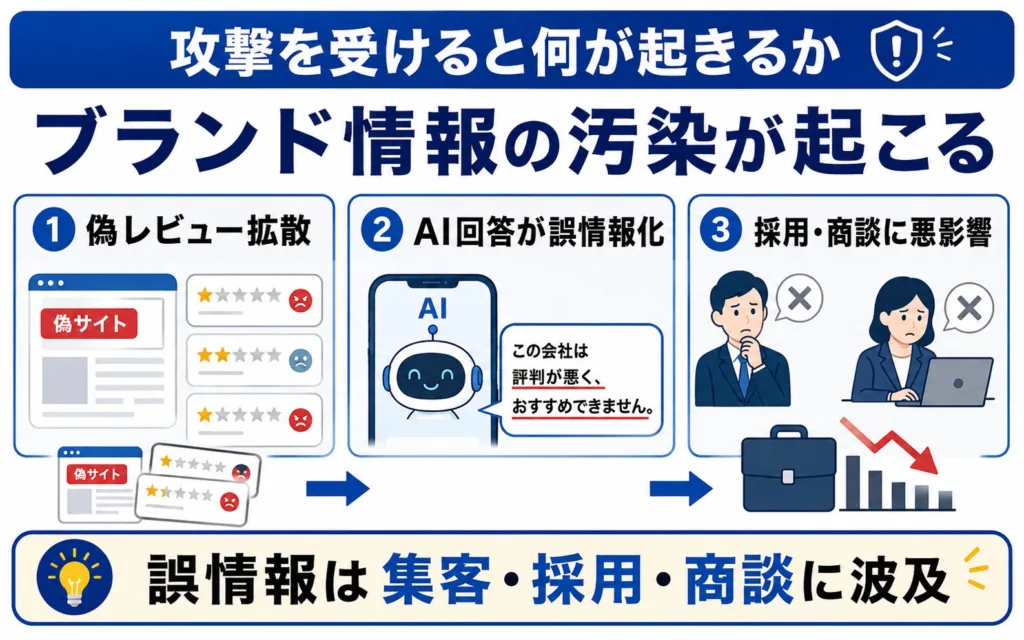
ここまでは「やってはいけない」視点でした。本セクションでは視点を変え、自社が攻撃の標的にされたときに何が起きるのかを整理します。加害ではなく被害の観点です。
なりすましや偽レビューでブランド情報が汚染される
第三者が、自社になりすましたサイトや偽のレビューをばらまくことで、AIが参照するブランド情報そのものが汚染される恐れがあります。AI検索では、複数ソースで一貫して確認できる情報が回答の裏づけとして扱われる場合があるため、悪意ある情報が複数のドメインに広がると、それが事実のように扱われかねません。
実体のない否定的情報が拡散すれば、AIの回答に誤った前提が紛れ込み、自社の説明よりも攻撃者の主張が優先される事態も起こり得ます。
AI回答に誤情報や競合に有利な情報が表示される
前述のPreference Manipulation Attacks(arXiv:2406.18382)が示すように、ページや説明文の作り込みによって、AIに競合製品を推奨させたり、自社を不利に見せたりすることが可能だと指摘されています。
その結果、利用者がAIに「おすすめ」を尋ねた際に、自社が不当に外されたり、競合が不自然に持ち上げられたりするリスクがあります。自社のあずかり知らないところで、購買の入り口が歪められてしまうのです。
指名検索・採用・BtoB商談に悪影響が及ぶ
AI回答の汚染は、実際のビジネス指標にも波及します。具体的には、次のような場面での悪影響が懸念されます。
- 指名検索:社名で調べた利用者が誤情報に触れ離脱する
- 採用:候補者がAI経由で否定的な誤情報を受け取る
- BtoB商談:担当者の事前リサーチで競合が優位に映る
AIが意思決定の入り口になるほど、その回答の汚染は集客・採用・商談という重要局面に直接響きます。だからこそ、攻撃を前提とした防御の備えが必要になります。BtoB企業におけるAI検索時代の商談獲得については、BtoB企業のLLMO対策でも詳しく解説しています。
ブラックハットLLMO攻撃から自社ブランドを守る方法
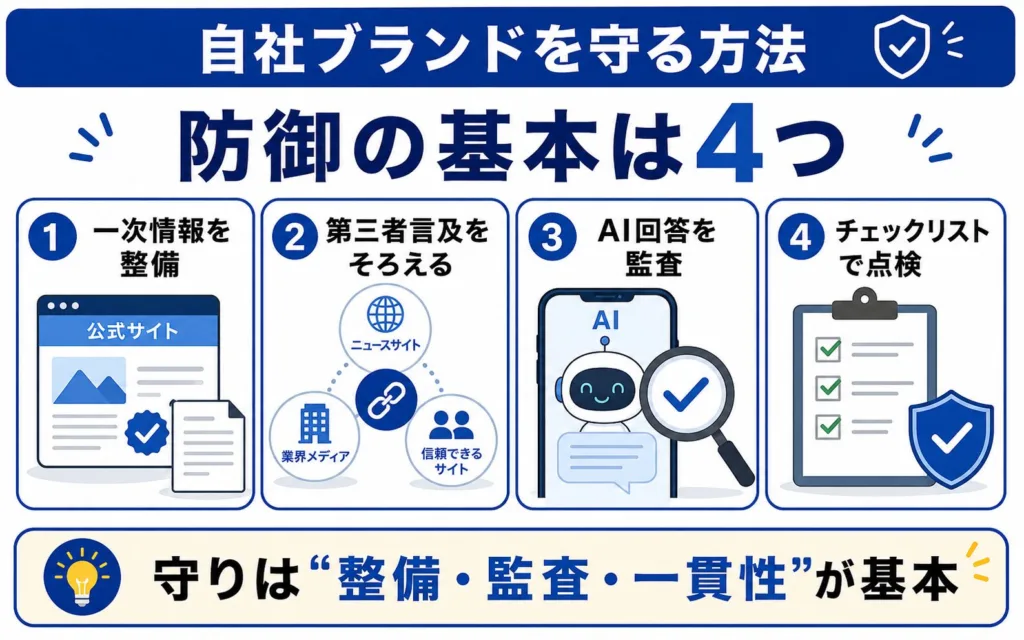
攻撃のリスクを踏まえ、自社ブランドを守るための実践的な備えを整理します。情報基盤の整備、第三者ドメインでの一貫性、定期監査、そして自己診断という順で見ていきます。
公式サイトと一次情報(会社・著者情報)を整備する
防御の土台は、AIが最も信頼すべき一次情報を自社で確実に整えることです。会社概要、運営者情報、著者・監修者の実在する経歴、事業実績などを公式サイト上で正確かつ最新に保ちます。
公式サイトは、自社情報の正確性を示す一次情報源として機能します。ここが整っていれば、外部の誤情報と矛盾が生じた際に「正しい基準」として参照できる状態を作れます。汚染情報に対抗する最初の防壁は、自社が発信する正確な一次情報なのです。
信頼できる第三者ドメインで情報の一貫性を高める
自社サイト内で主張するだけでは十分でない場合があります。AI回答の根拠として参照される情報を増やすには、自社サイト外での一貫した言及も重要になります。中立的なプレス、信頼性の高い専門メディア、検証可能な実データなど、複数の信頼できる第三者ドメインにまたがって、自社の情報が矛盾なく描かれている状態を作ることが有効です。
本記事では、公式サイト・第三者メディア・外部データの内容が一致している状態を「三角的な合意」と呼びます。この一貫性が高いほど、攻撃者が流す虚偽の主張は浮き上がりやすく、矛盾が検知されて自社の正しい情報が優先される可能性が高まります。オウンドメディア単体ではなく外部言及まで含めて設計する考え方は、オウンドメディアのLLMO対策でも詳しく解説しています。
AI回答・指名検索・外部言及を定期的に監査する
汚染は予兆を伴うことが多いため、定期的な監査が防御の要になります。主要な生成AIに自社や主力製品について尋ね、回答内容と引用元を継続的に記録します。あわせて、指名検索の結果や外部サイトでの言及も観察し、なりすましや偽レビュー、不自然な比較記事の兆候を早期に把握します。AI回答内で自社がどの程度見えているかを測る考え方は、AI Visibilityと呼ばれます。
なお、アドカルのLLMO診断では、現状を可視化するために次の観点を確認します。
- ブランド回答:主要な生成AIが自社をどう説明しているか
- 引用元:回答の根拠としてどのドメインが参照されているか
- 競合比較:比較を尋ねた際に自社がどう表示されるか
- 外部言及の一貫性:第三者サイトでの記述に矛盾がないか
- 情報差分:公式サイトとAI回答の間に古い・誤った情報がないか
具体的には、次のような監査対象とポイントに沿って点検します。
表2:アドカルのLLMO診断における監査観点
| 監査対象 | 見るべきポイント |
|---|---|
| 生成AI回答 | 社名・サービス名・競合比較で誤情報が出ていないか |
| 引用元 | 公式サイトではなく低品質な第三者サイトが根拠になっていないか |
| 外部言及 | 比較記事・口コミ・レビューに不自然な偏りがないか |
| AIクローラー | 検索用クローラーを誤ってブロックしていないか |
| 公式情報 | 会社情報・著者情報・サービス内容が最新か |
単に「AIに表示されるか」だけでなく、誤情報・古い情報・競合に有利な情報が混ざっていないかまで点検するのがポイントです。
自社が該当しないか自己診断チェックリストで確認する
守る側に回るには、自社が無自覚にグレー〜ブラックな手法に近づいていないかの確認も欠かせません。次のチェックリストで、自社の状態を点検してみてください。
表3:ブラックハットLLMO自己診断チェックリスト
| チェック項目 | 危険度 |
|---|---|
| AIに読ませるためだけの不自然なテキストがある | 高 |
| 実在しない監修者・著者を作っている | 高 |
| 第三者サイト風の比較記事を量産している | 高 |
| 人間には見えずクローラには見える情報がある | 高 |
| 出典のない統計・実績・受賞歴を載せている | 高 |
| 自社名・関連語を不自然に反復している | 中 |
| AI回答での見え方を定期監査していない | 中 |
「高」に一つでも当てはまる場合は、その施策を見直すことを強くおすすめします。より広い観点で自社サイトを点検したい場合は、LLMOチェックリストも参考になります。

【SEO・LLMO対策でお困りではないですか?】
株式会社アドカルは主に生成AIを活用したデジタルマーケティング支援やマーケティングDXに強みを持った企業です。
貴社のパートナーとして、少数精鋭で担当させていただくので、
「LLMO対策について詳しく知りたい」
「現状のSEO対策で成果が出ていない」
「LLMO対策でAI検索からの集客を強化したい」
とお悩みの方は、ぜひ弊社にご相談ください。
貴社のご相談内容に合わせて、最適なご提案をさせていただきます。
サービスの詳細は下記からご確認ください。無料相談も可能です。
ブラックハットLLMOに頼らない正しいLLMO対策
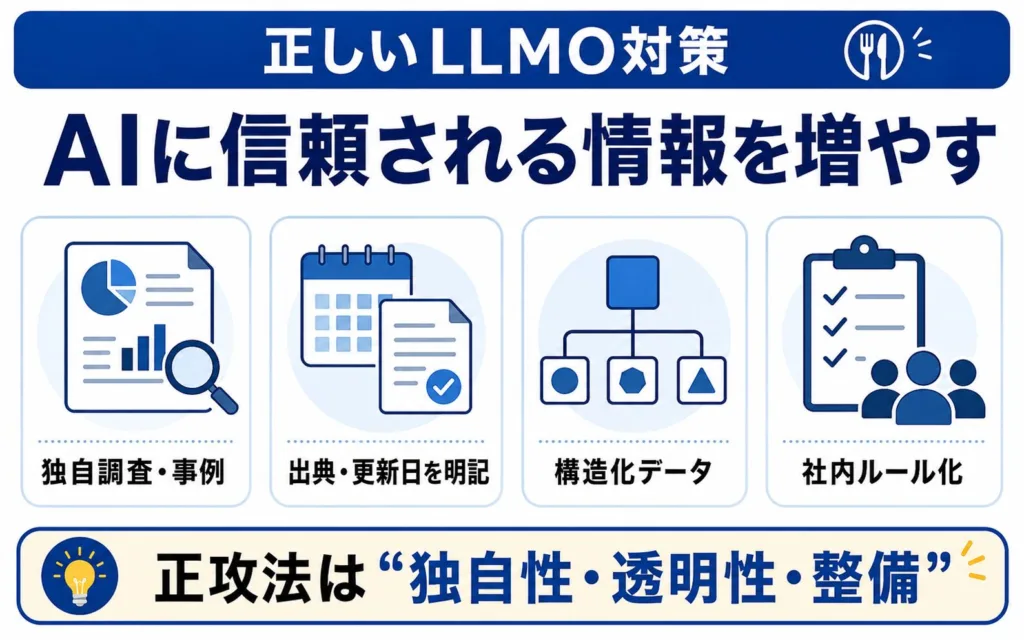
最後に、リスクの高い手口に頼らず、AIに信頼され引用されるための正攻法を整理します。一次情報の発信、出典の明確化、構造化、そして社内ルール化という4点です。
独自調査・事例・専門家コメントで一次情報を発信する
AIに引用されやすいのは、他にはない一次情報です。自社の独自調査データ、具体的な導入事例、実名の専門家によるコメントなどは、AIが要約・引用する際の価値ある根拠になります。
Googleの最適化ガイドも、一次体験や独自データ・専門家の視点を備えた非コモディティなコンテンツが、AI検索での可視性に最も効くと説明しています。だからこそ、量産ではなく「ここでしか得られない情報」を地道に積み上げることが、最も持続的なLLMO対策になります。ChatGPT Searchで引用されるための考え方は、ChatGPTに引用されるLLMO対策の記事で解説しています。
出典・更新日・運営者情報を明確にする
情報の信頼性は、その出どころの明確さで支えられます。統計や主張には出典を添え、記事には更新日を記し、運営者・著者情報を明示することが基本です。
これらはAIが信頼性を判断する手がかりであると同時に、攻撃者による偽情報との違いを際立たせる要素でもあります。透明性を高めることが、そのまま防御にもつながります。
構造化データと内部リンクでAIが理解しやすくする
正しい情報も、AIが理解しやすい形で提供されてはじめて拾われます。組織・著者・製品などの情報を構造化データ(スキーマ)で明示し、関連ページを内部リンクで適切につなぐことで、AIが自社のエンティティとその関係を把握しやすくなります。
これは欺くための技術ではなく、正確な情報を正確に伝えるための土台づくりです。正攻法のLLMOにおける、地味だが効果の大きい施策といえます。構造化データの基本的な考え方は構造化データとは、関連ページを適切につなぐ設計は内部リンクとはを解説した記事もあわせてご覧ください。
やってよい施策と避ける施策を社内で明文化する
持続的な運用には、判断基準を組織で共有することが欠かせません。やってよい施策と避けるべき施策を社内で明文化し、関係者が同じ基準で判断できる状態を作ります。
- 推奨:一次情報の発信、出典明記、構造化データの整備
- 注意:意図や手法に不自然さが残るグレー施策の安易な採用
- 禁止:捏造・なりすまし・クローキングなど欺瞞を狙う施策
基準が明文化されていれば、担当者が無自覚にリスクへ近づくことを防げます。迷ったときは、第三者の専門家に相談する選択肢も持っておくとよいでしょう。
まとめ:ブラックハットLLMOではなく信頼される情報設計で勝つ
ブラックハットLLMOは、生成AI回答を欺く目的で操作する行為であり、Googleのスパムポリシー対象になり得るうえ、ブランド毀損やセキュリティリスクにもつながります。研究が示すとおり操作は現実のリスクですが、同時に自社が汚染攻撃の標的にもなり得ます。頼るべきは小手先の手口ではなく、一次情報の整備・第三者での一貫性・定期監査という信頼の積み上げです。自社ブランドがAI検索でどう表示されているかを可視化したい場合は、主要な生成AIでの指名検索・競合比較・引用元を確認するところから始めましょう。自社だけで判断が難しい場合は、アドカルのLLMOコンサルティングサービスで現状診断から進めることも可能です。
【SEO・LLMO対策でお困りではないですか?】
株式会社アドカルは主に生成AIを活用したデジタルマーケティング支援やマーケティングDXに強みを持った企業です。
貴社のパートナーとして、少数精鋭で担当させていただくので、
「LLMO対策について詳しく知りたい」
「現状のSEO対策で成果が出ていない」
「LLMO対策でAI検索からの集客を強化したい」
とお悩みの方は、ぜひ弊社にご相談ください。
貴社のご相談内容に合わせて、最適なご提案をさせていただきます。
サービスの詳細は下記からご確認ください。無料相談も可能です。


